Prof D’s Regression Sessions - Vol 1
Time to go deep!
- a.dennett@ucl.ac.uk
1st August 2024
CASA0007 Quantitative Methods
This week’s Session - Foundations
- A Recipe for Success:
- understanding your ingredients (data)
- understanding the basic method (rules) - sample size, heteroscedascity, variance, degrees of freedom
- baking your first cake (model)
- judging your efforts (interpreting the outputs)

Secondary Schools, Attainment and Urban Policy
- School performance and pupil attainment can be a big urban policy issue - particularly where variations in access and perceived quality occur
- These variations feed into broader socio-economic issues in cities
- In the UK, schools are the responsibility of local government
- Understanding the drivers behind pupil attainment and school performance vital for effective resource allocation and good local policy

Secondary Schools, Attainment and Urban Policy
- In 2024, Brighton and Hove Council convinced pupil attainment mainly driven by Disadvantage Attainment Gap - socio-economically disadvantaged students perform worse than their more affluent peers
- Work of Professor Stephen Gorard, University of Durham, suggests mixing of disadvantage improves attainment
- Solution: create more socially mixed schools through a new controversial admissions policy
Step 1a - Ingredients (gathering and preparation)
- The data is collected by the Department for Education (DfE) - a full annual census of each school’s
- Hundreds of variables collected relating to:
- attainment and progress
- pupil characteristics
- school characteristics
- Some data / variables (ingredients) will be more useful than others
Step 1b - Ingredients (familiarisation)
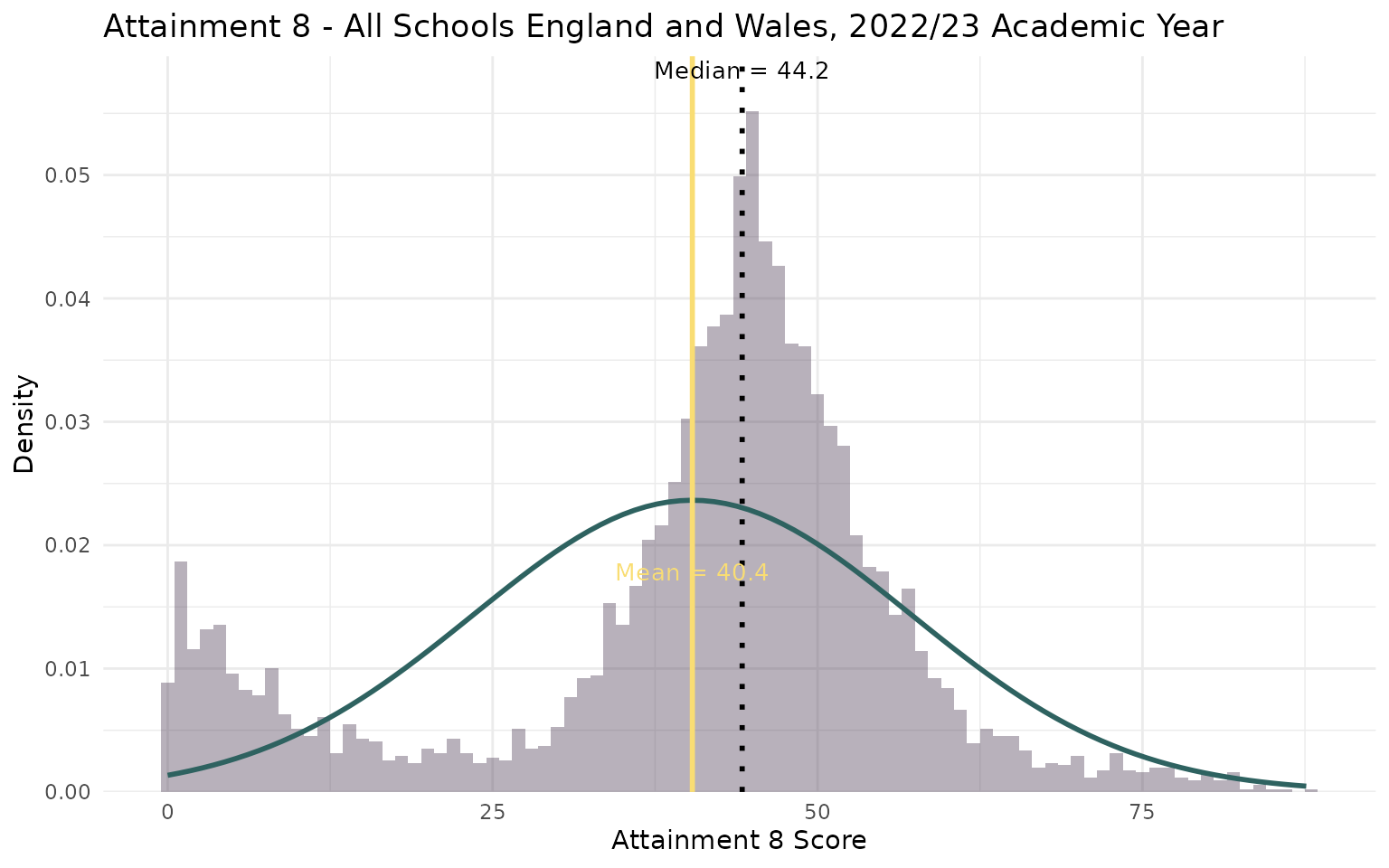
- Hmmm? Are there any problems that could be indicated here?
Step 1b - Ingredients (familiarisation)
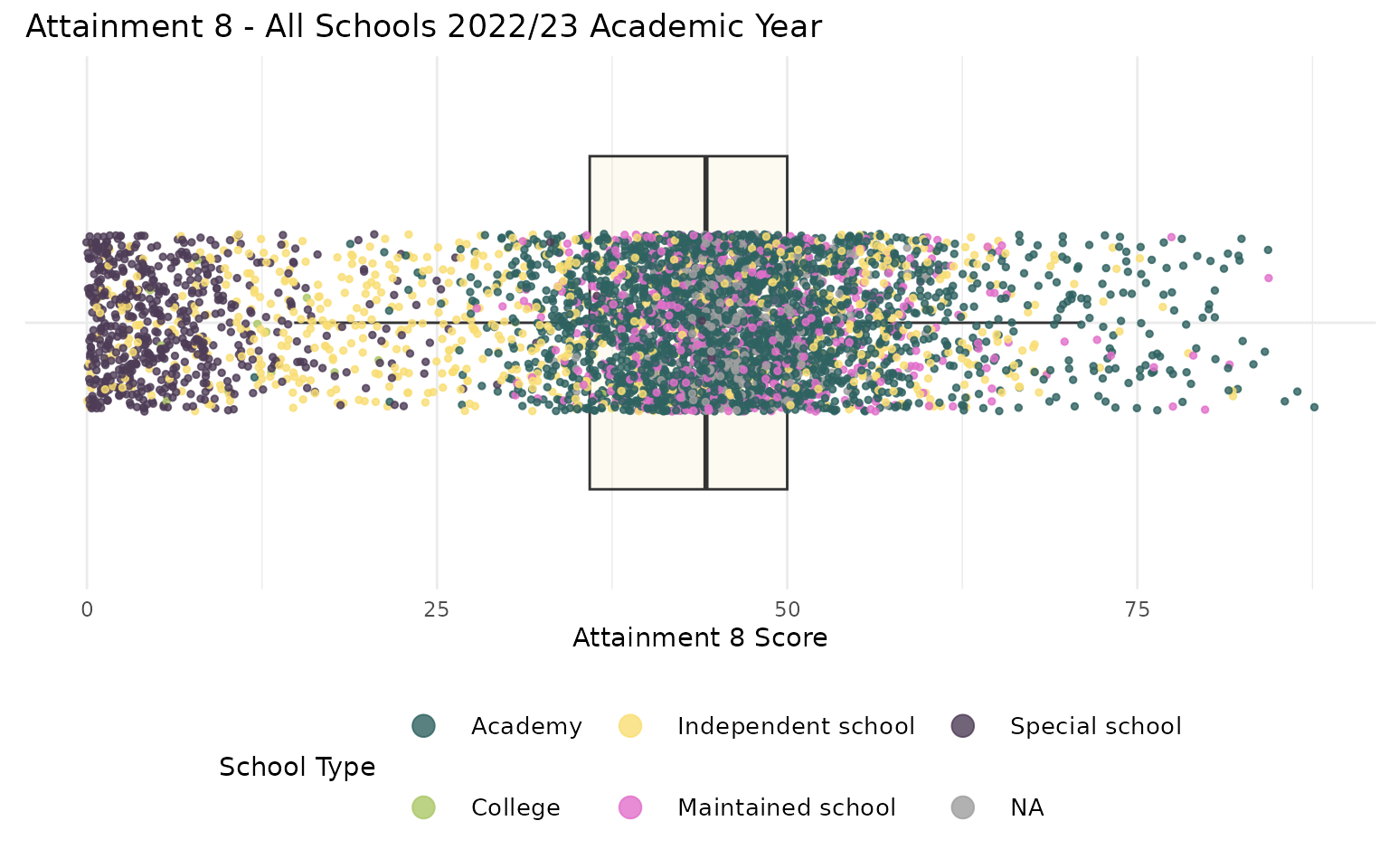
- Notice anything now?
- What could/should we do about it? Any suggestions?
Step 1c - Ingredients (selection)
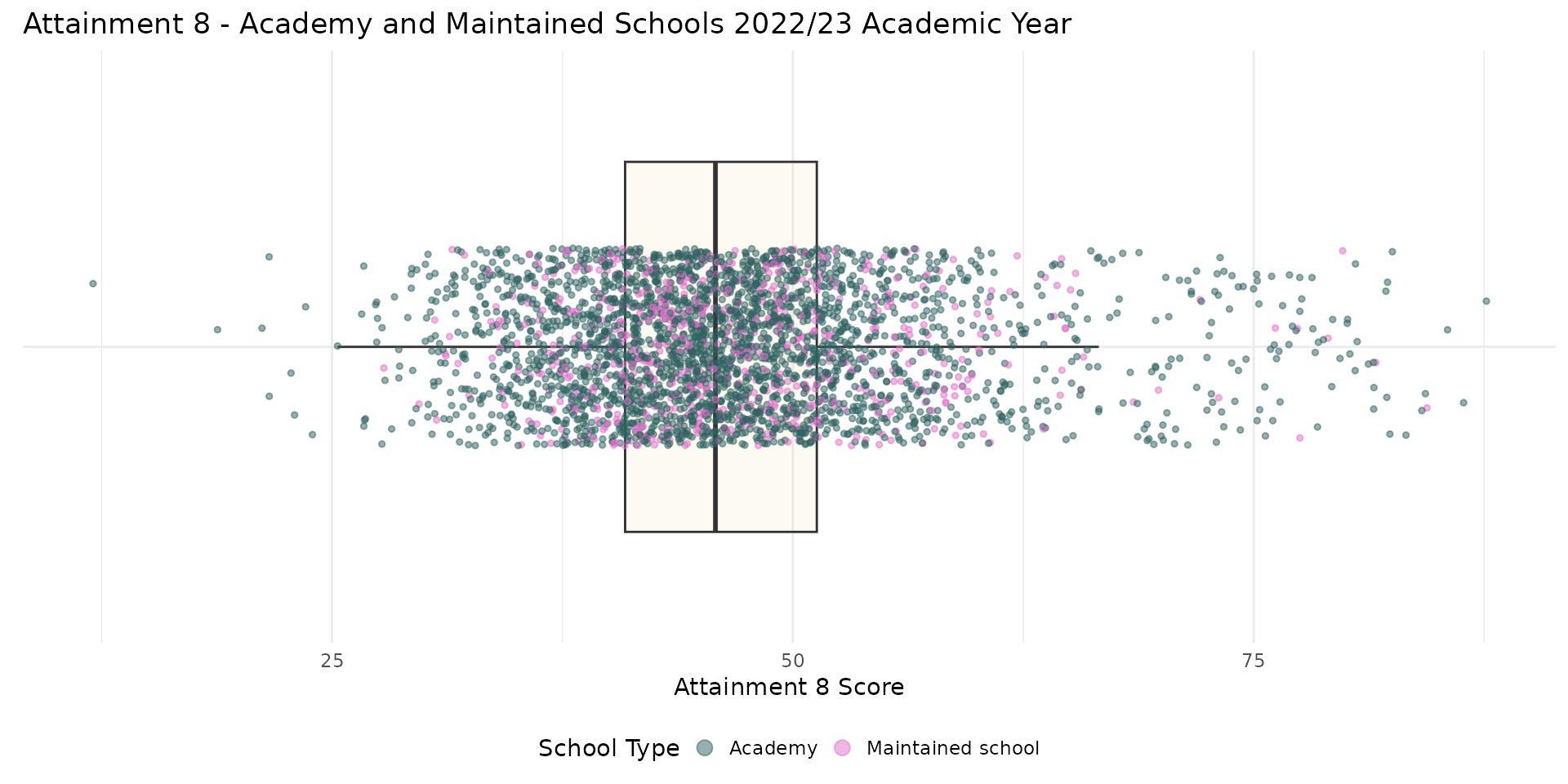
Step 1c - Ingredients (selection)
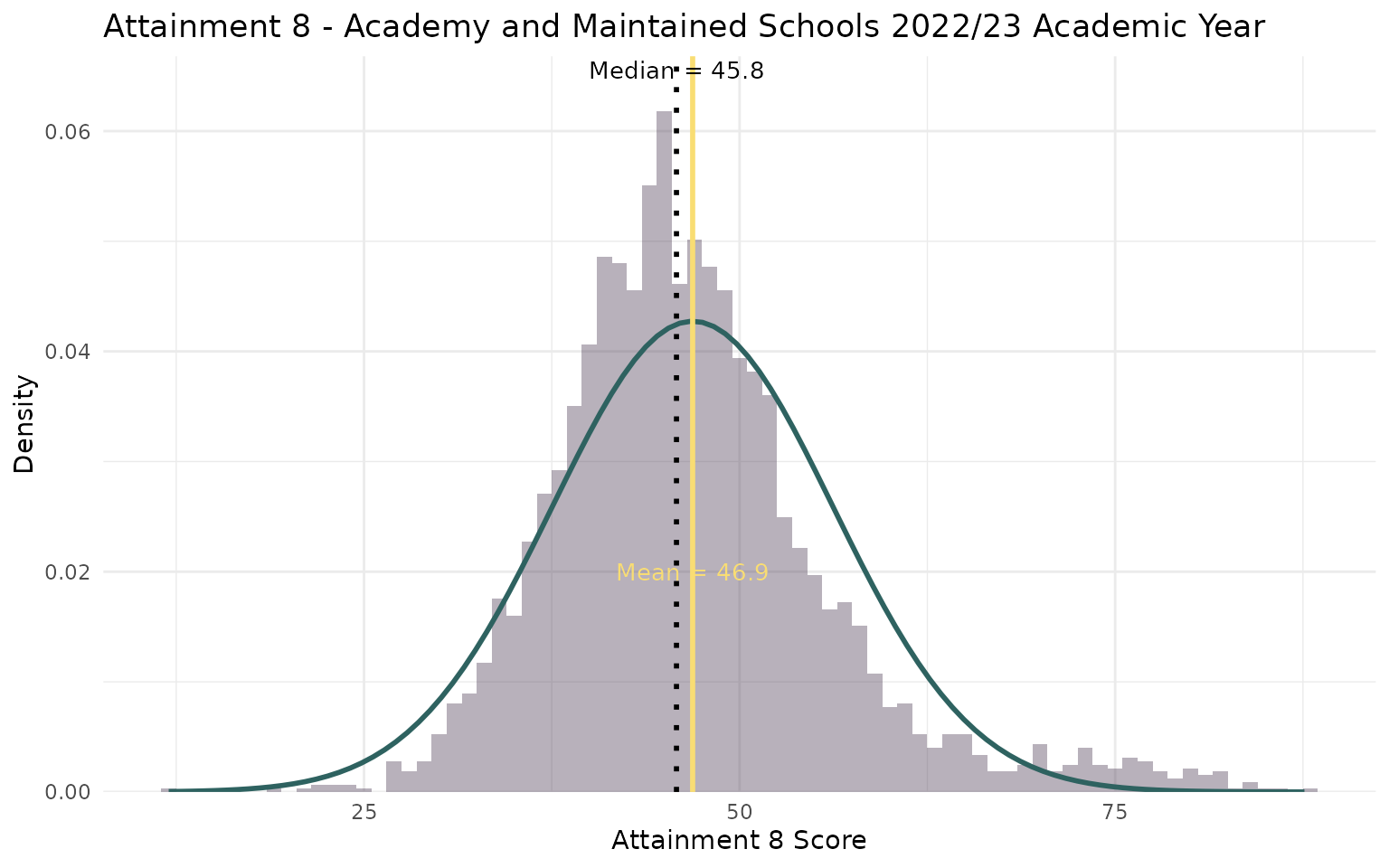
Step 1c - Ingredients (selection)
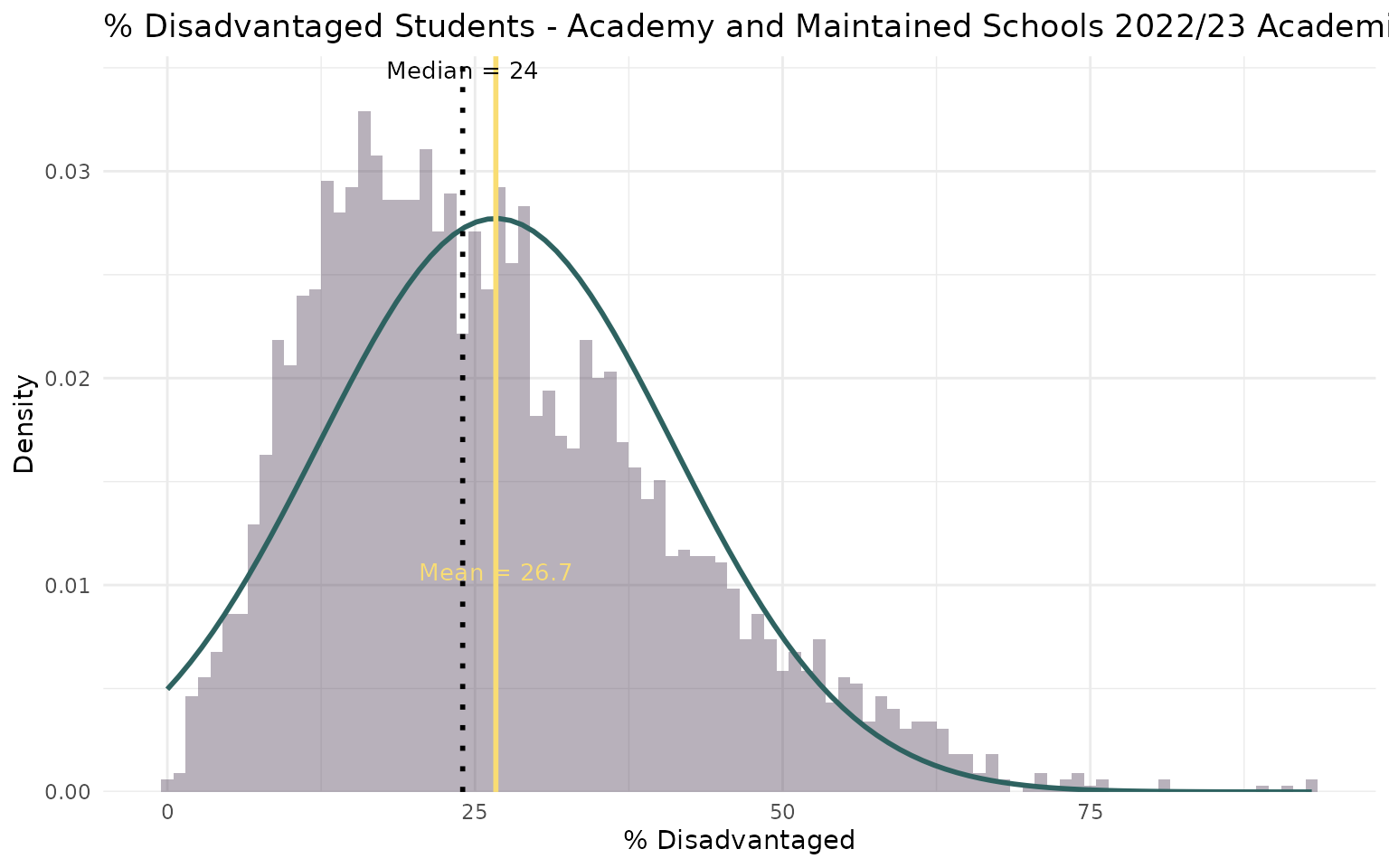
Step 1c - Ingredients (selection)
- Understanding your ‘system’ is vital
- What is “in” and what is “out”?
- How do you know?
- Experience (e.g. I used to be a school teacher so aware of differences in types of school)
- Research! If you are unfamiliar with the system, do your research

Step 1c - Ingredients (selection)
- Brighton and Hove City Council relied heavily on the work of Gorard in building its policy
- Paper links social mixing to improved attainment for disadvantaged pupils
- Includes variables such as:
- school type (e.g. academy, maintained)
- pupil characteristics (e.g. free school meals (FSM) eligibility, special educational needs, ethnicity)
- school characteristics (e.g. size, location)
- Thus all might be worth investigating

Step 1c - Ingredients (selection)
- However, wider reading also suggests that factors such as attendance (which Gordard does not include in his paper as a variable) may also play a big role in the attainment of disadvantaged pupils
- Work by Claymore suggests that a large proportion of the gap in attainment between disadvantaged pupils and more affluent peers can be explained by:
- the differences in absence rates
- exclusion
- rates of moving between schools

Linear Regression - It’s just a scatter plot!
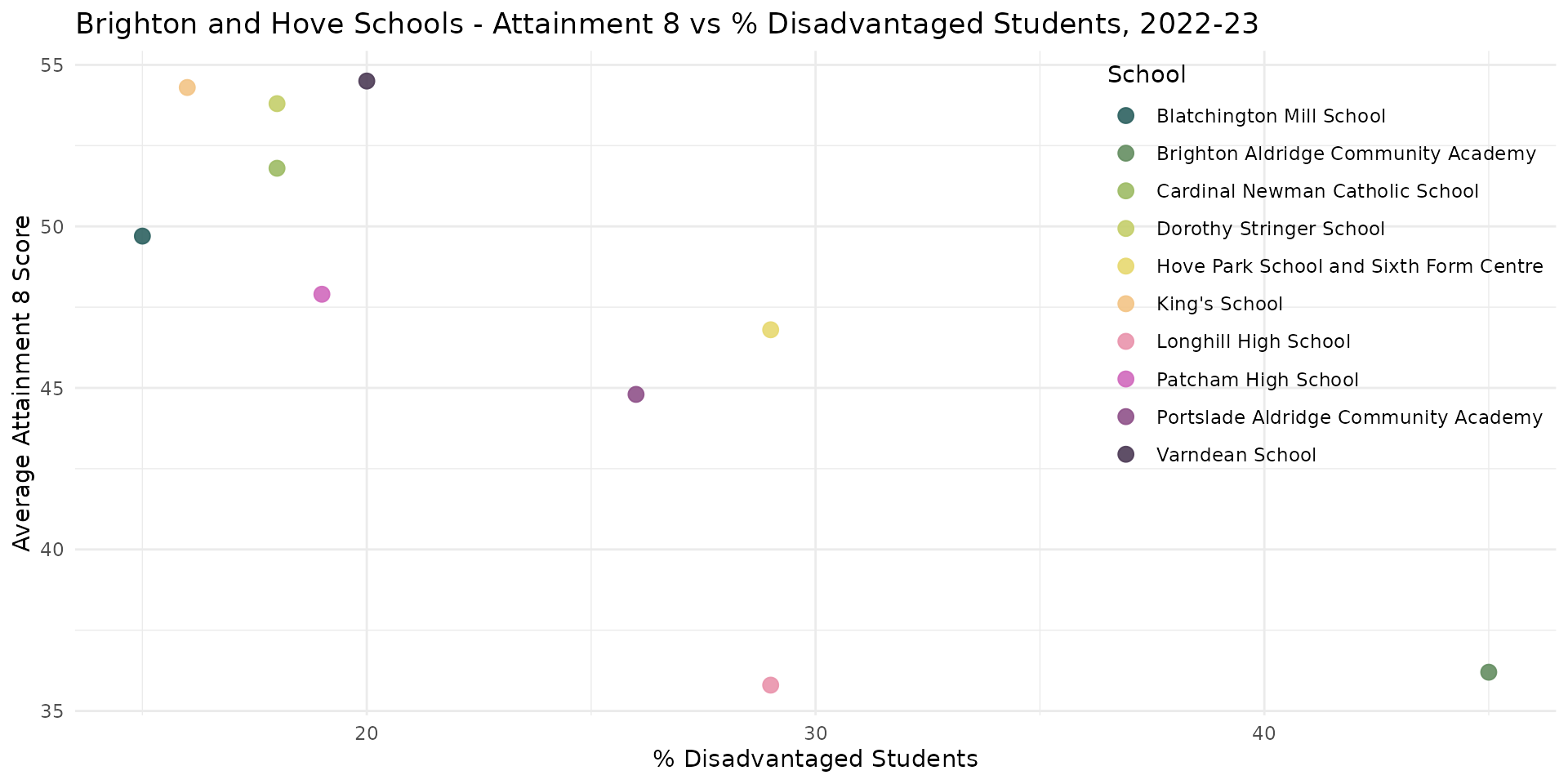
- A regression model is nothing more than a description of a scatter plot
- Dependent variable = \(Y\)-axis
- Independent variable = \(X\)-axis
Linear Regression - Line of Best-fit
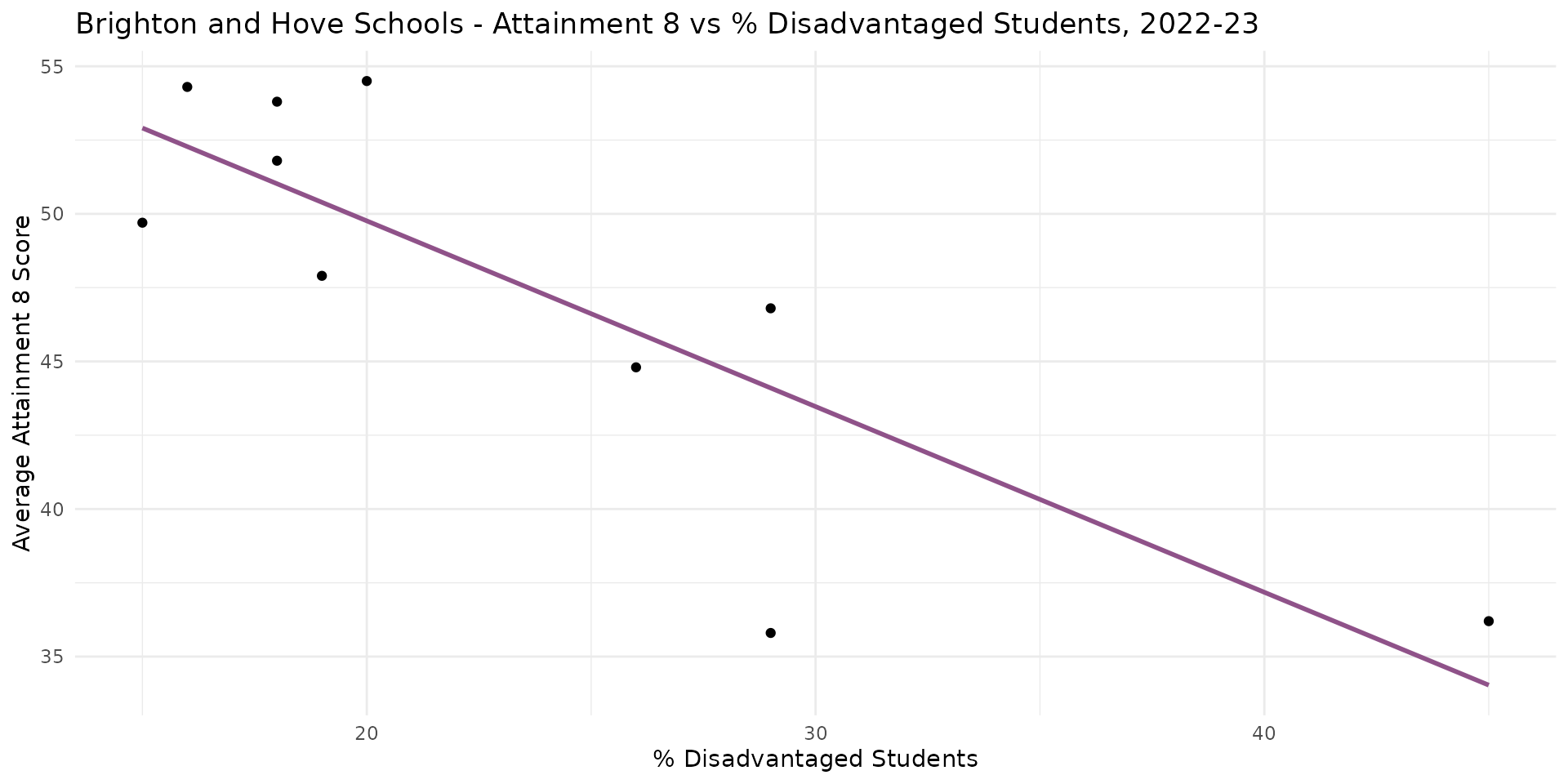
- The linear regression model is the straight line of best-fit
- A linear model function
lm()(inR) uses a method called Ordinary Least Squares (OLS) to find the line of best-fit. - The best line minimises the squared (so that negatives and positives don’t cancel) vertical distances between the line and the points - hence OLS
Linear Regression - Residuals / Error
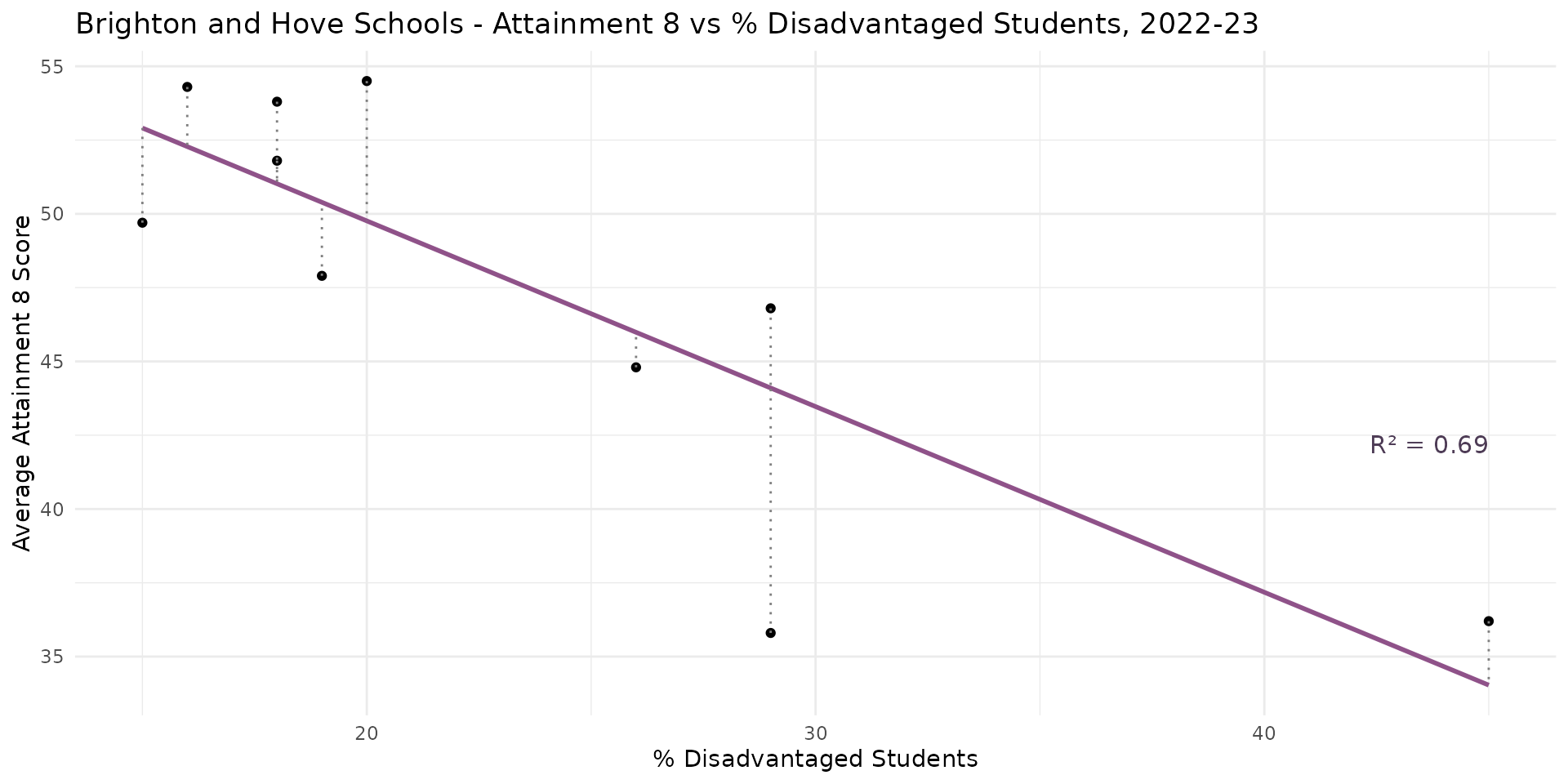
- The vertical distances between the points and the line of best fit are called the residuals - sometimes also referred to as the errors or \(\epsilon\)
- The closer the points are to the line, the better the fit of the model
Linear Regression - R-Squared
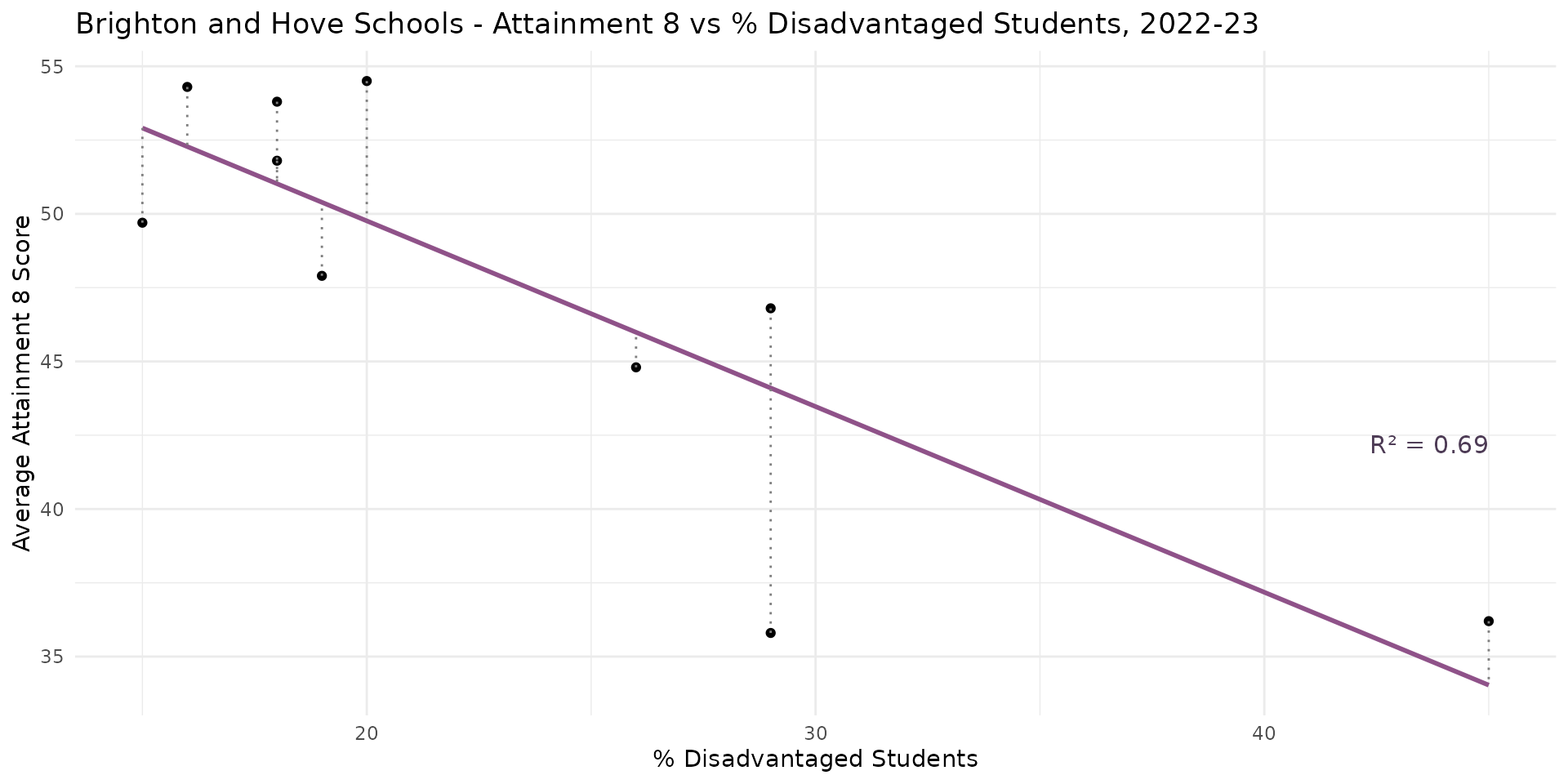
- The fit of the model is represented by the coefficient of determination or \(R^2\) value (0-1), which is calculated from the residuals
- It describes how much of the variation in \(Y\) (Attainment 8 score) is explained by the variation in \(X\) (% Disadvantaged Students) - here 69%
- The closer to 1 (100%), the better the fit of the model
Linear Regression - R-Squared
- It’s easy to visually estimate your \(R^2\) value from looking at how well correlated the points are. NB as squared, always +
Linear Regression - Slope and Intercept
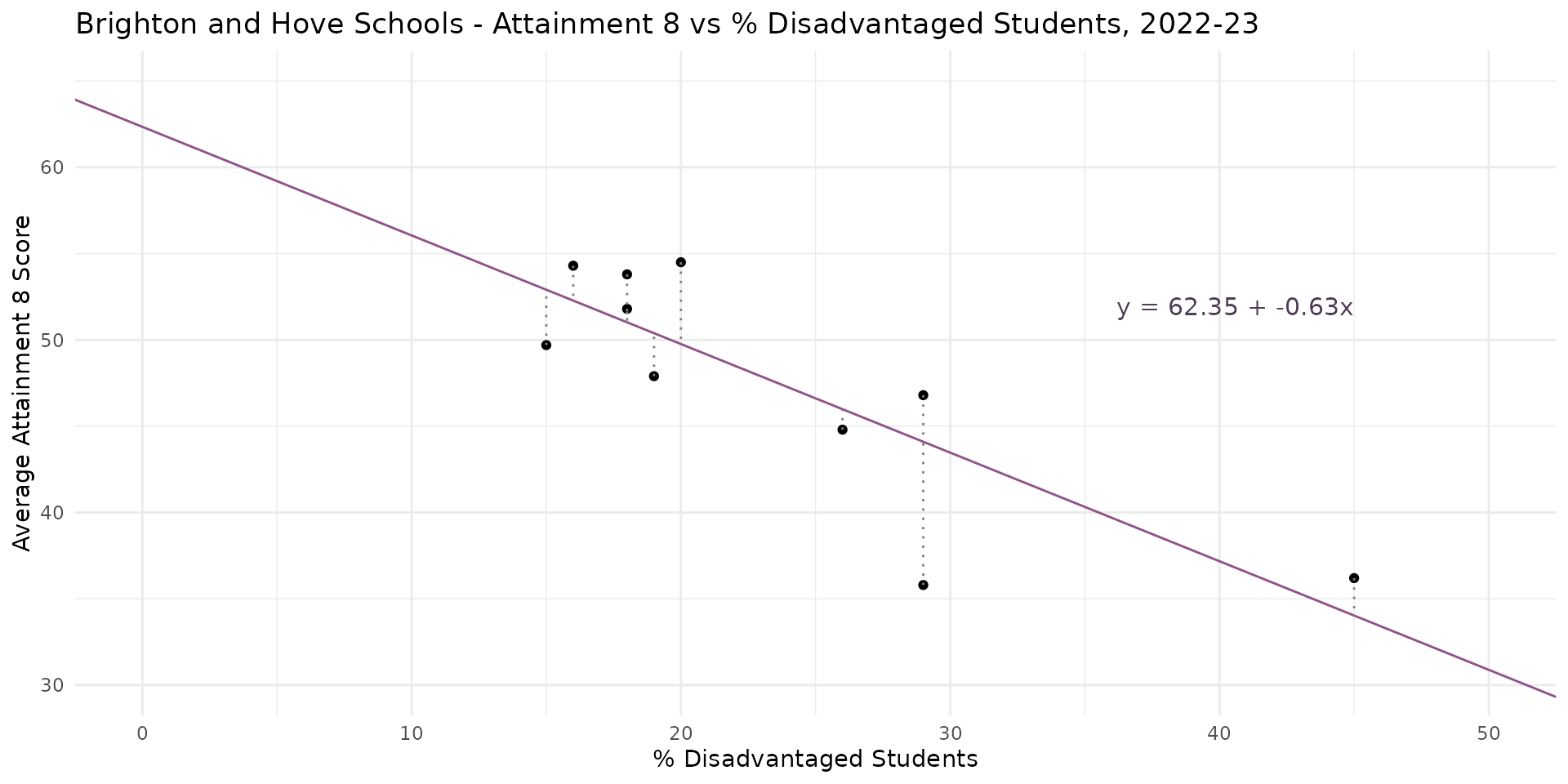
- The regression line itself can be described by an equation with two parameters / coefficients:
- The intercept - \(\beta_0\) - which is the value of \(Y\) when \(X = 0\)
- The slope - \(\beta_1\) - which the change in the value of \(Y\) for a 1 unit change in \(X\)
Linear Regression - Model Estimates
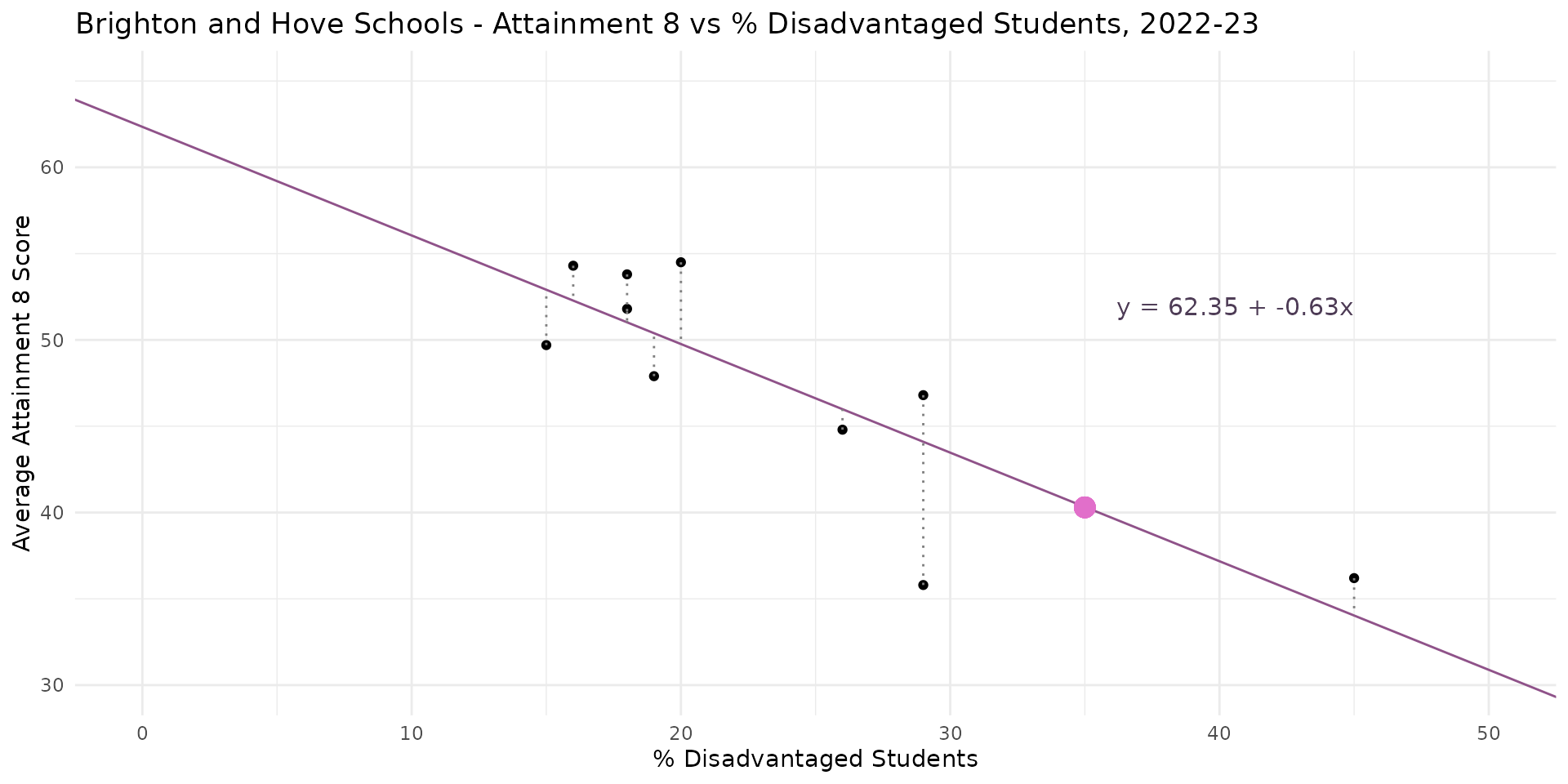
\[Y = \beta_0 + \beta_1X_1 + \epsilon\] \[\hat{Y} = 62.35 + (-0.63 \times X) + \epsilon\] \[40.3 = 62.35 + (-0.63 \times 35) + 0\]
Linear Regression - The Statistical Model
- Scatter plots are an excellent intuitive way to understand the relationship between two continuous variables
- But algorithms are required to generate the various plot statistics and other useful info
- Lots of different statistical software packages will do this
- Doesn’t matter which you use, they all do pretty much the same thing under the hood
![]()
![]()
![]()
![]()
![]()

Linear Regression - Running the Model

- This is the code representation of the model equation we saw earlier:
lm()is the function that fits a linear modelATT8SCR(Attainment 8 Score) is the dependent variable \(Y\)~means “is modelled by”PTFSM6CLA1A(% Disadvantaged Students) is the independent variable \(X\)data = bnt_subis the dataset we are using which contains the variables
Linear Regression - Residuals and Error


- The residual errors range from -8.3 (Longhill) to + 4.7 (Varndean)
- The residual standard error of 4.087 = predictions for School’s Attainment 8 score are off by about 4.1 points
- Residual Standard Error (RSE) and \(R^2\) are inversely related - A smaller RSE and larger \(R^2\) both mean a more precise model
- The F-Statistic is a ratio of the amount of variance in \(Y\) explained by the model to that not. x17.7 more - statistically significant <0.005
Linear Regression - Degrees of Freedom
- DF are the Degrees of Freedom in the model. DF very important for understanding how reliable your \(R^2\) value might be
- The first number (1) relates to the number of variables
- The second number (8) relates to the number of observations (cases) in the dataset, minus the number of parameters
- In our example we have 10 observations and 2 parameters (intercept and slope) so \(10 - 2 = 8\) degrees of freedom
Linear Regression - Degrees of Freedom
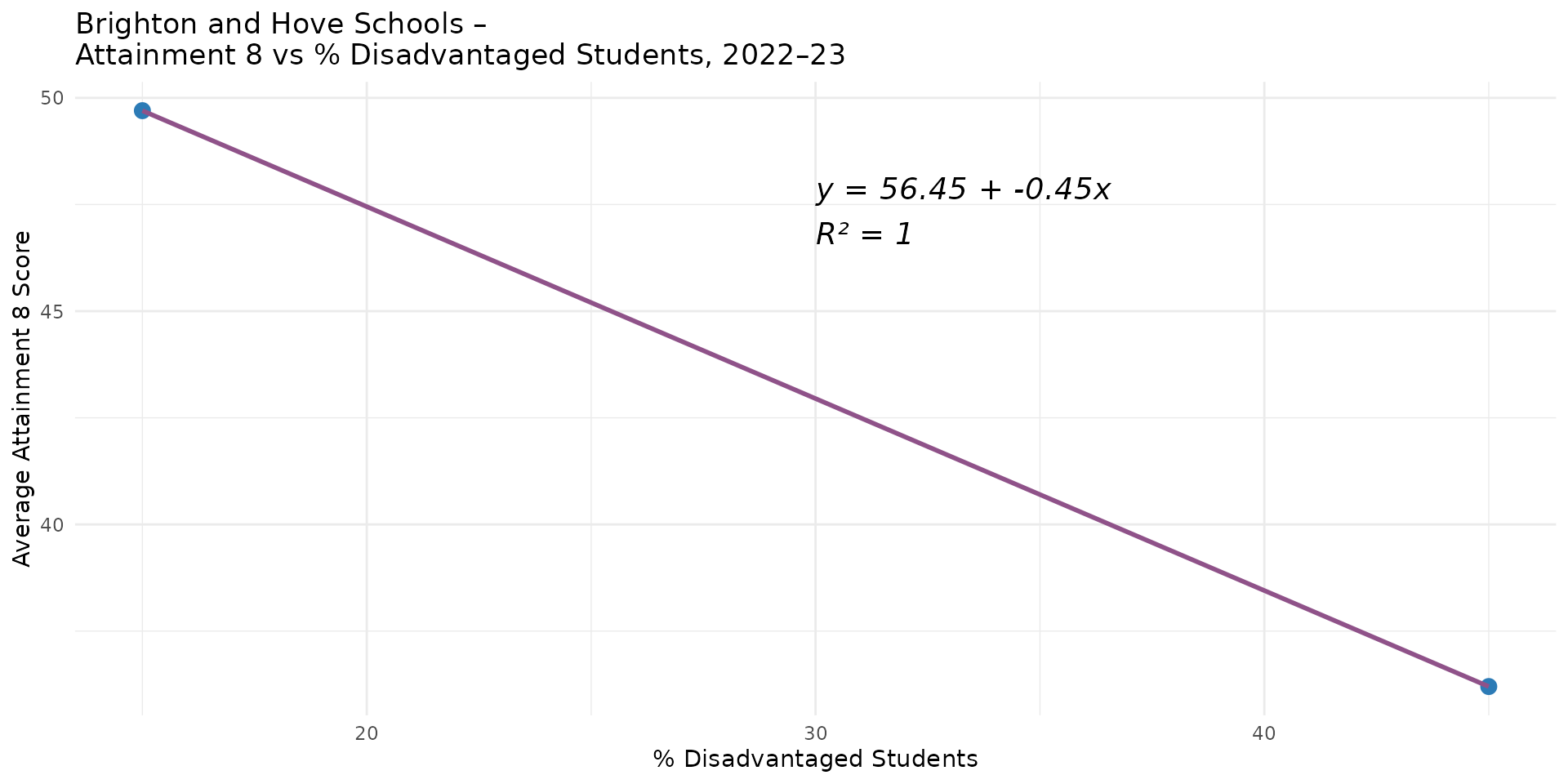
- 2 observations - 2 parameters = 0 degrees of freedom
Linear Regression - Degrees of Freedom
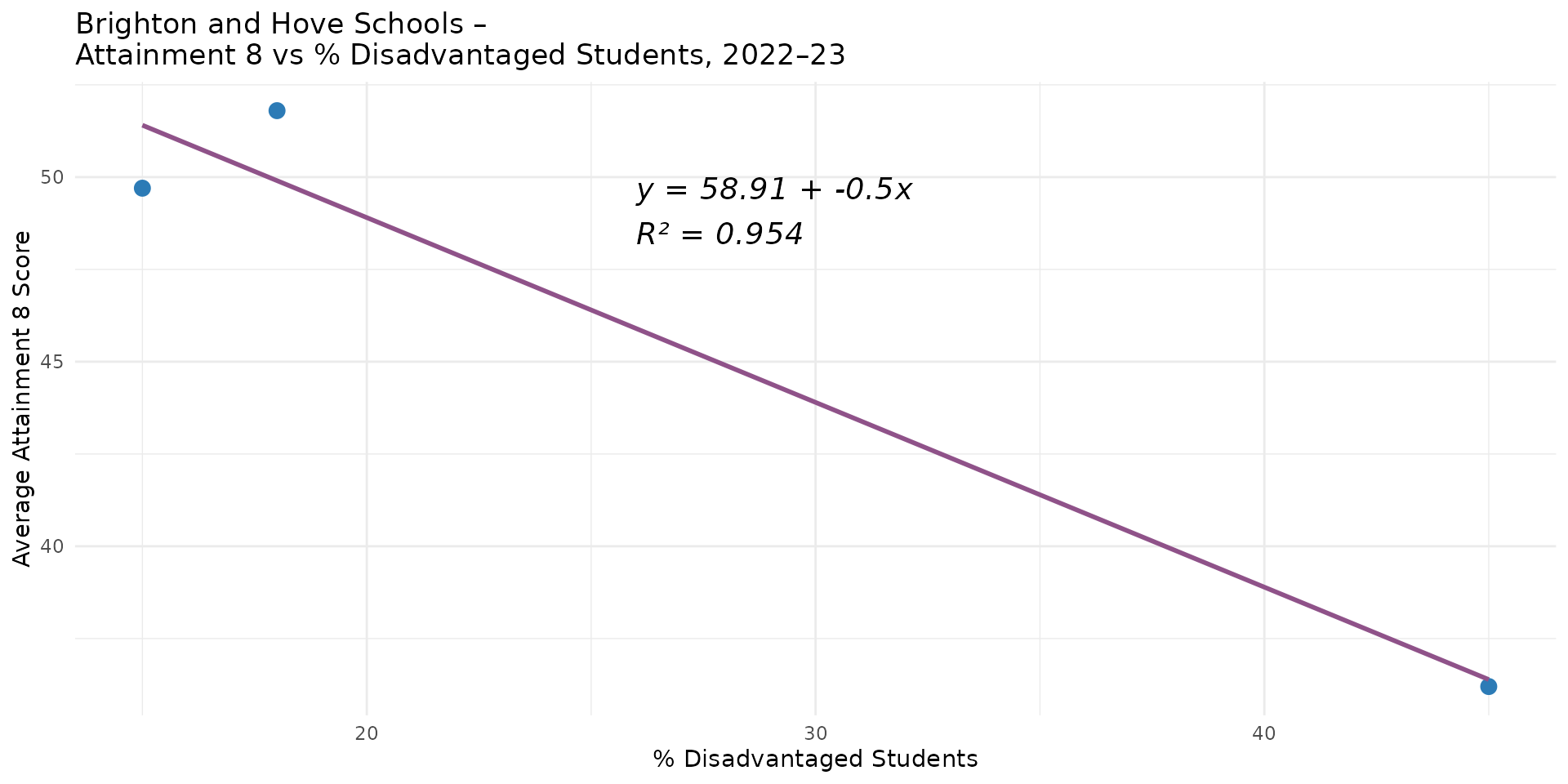
- 3 observations - 2 parameters = 1 degree of freedom
Linear Regression - Degrees of Freedom
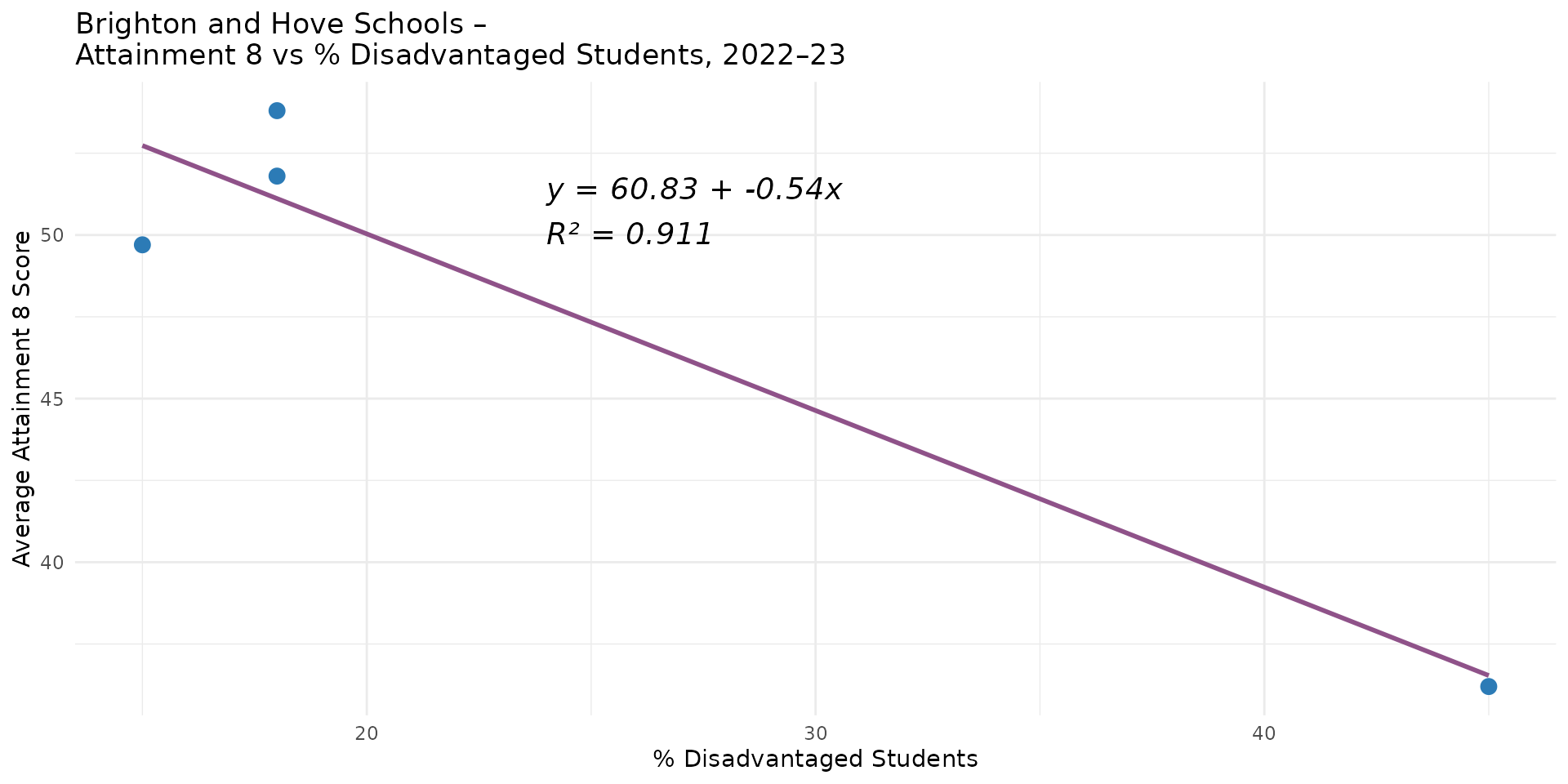
- 4 observations - 2 parameters = 2 degrees of freedom
Linear Regression - Degrees of Freedom
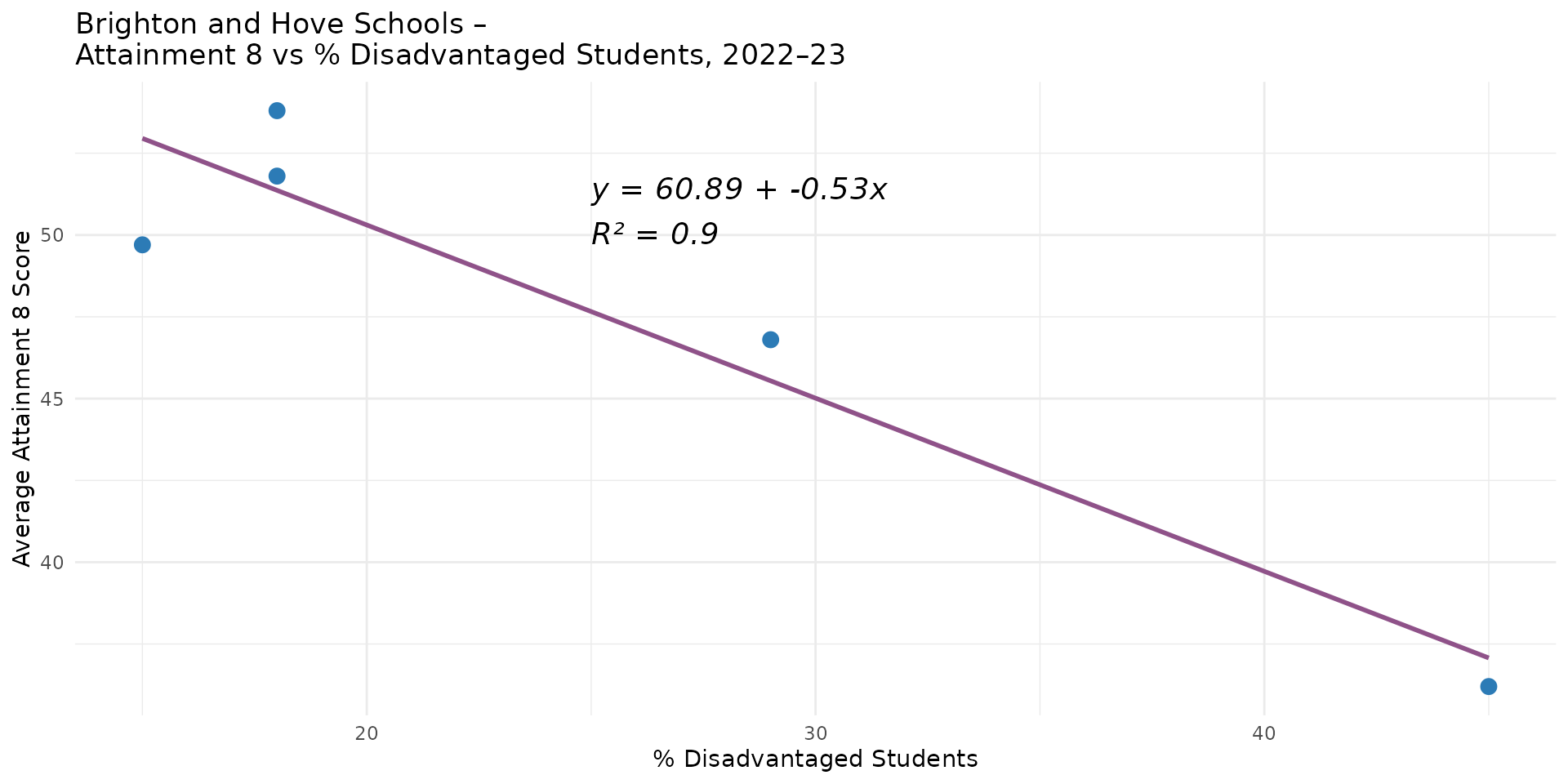
- 5 observations - 2 parameters = 3 degrees of freedom
Linear Regression - Coefficients 1
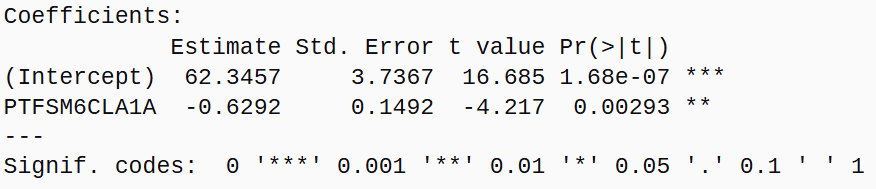
- The Estimates (\(\beta\))
- Intercept \(\beta_0\) - estimated Attainment 8 value when % Disadvantaged Children in a school is zero
- PTFSM6CLA1A (slope \(\beta_1\)) - effect of a one-unit change in the % Disadvantaged Children on Attainment 8 - therefore linked to the units of the independent variable and not directly comparable across different variables if measured on different scales
Linear Regression - Coefficients 2
- The Standard Error (SE) - measure of the uncertainty or precision of the estimate (coefficient) - how much it might vary
- Large SE relative to the Estimate = estimate unreliable / uncertain
- SE of 0.15 for the estimate of -0.63 for PTFSM6CLA1A means the change in the value of Attainment 8 for a 1% change in disadvantaged students could vary between -0.48 and -0.78
Linear Regression - Coefficients 3
- The t-value - ratio of the \(\frac{Estimate}{SE}\)
- a large standard error will make the t-value small (close to zero)
- t-values can be thought of as a standardised coefficient - very useful for comparing the relative importance of different predictors in the model
- The larger the t-value, the more important the predictor is in explaining the variation in the dependent variable - more important the variable
Linear Regression - Coefficients 4
- The \(P\)-value - \(P\)-robability of observing a t-value as extreme as the one calculated if there were no relationship between the independent and the dependent variable
- A small \(P\)-value (typically \(p\) < 0.05) indicates <5% chance that \(X\) is not really explaining variation in \(Y\)
- The Signif. codes (like *** and **) are just a quick visual guide to this p-value, showing you at a glance which variables are significant.
- Any parameter with 1, 2 or 3* is “statistically significant” at 5% or better
Linear Regression - Coefficients 4
- The \(P\)-values relate to the null hypotheses that:
- The true value of the intercept (baseline attainment) is zero when the independent variable (% disadvantage) is zero.
- \(P\) <0.001 = <0.1% \(P\)-robability that 62.3 occurred by random chance
- Note - It doesn’t tell us that when % Disadvantaged is zero, 62.3 will be a correct Attainment 8 score, just that real value is unlikely to be zero
Linear Regression - Coefficients 4
- The \(P\)-values relate to the null hypotheses that:
- The true value of the PTFSM6CLA1A slope (relationship between % Disadvantaged and Attainment 8) is zero. \(P\)- < 0.01 = <1% \(P\)-robability that the relationship observed is by chance. Relationship is likely to be real.
Linear Regression - Summary so far
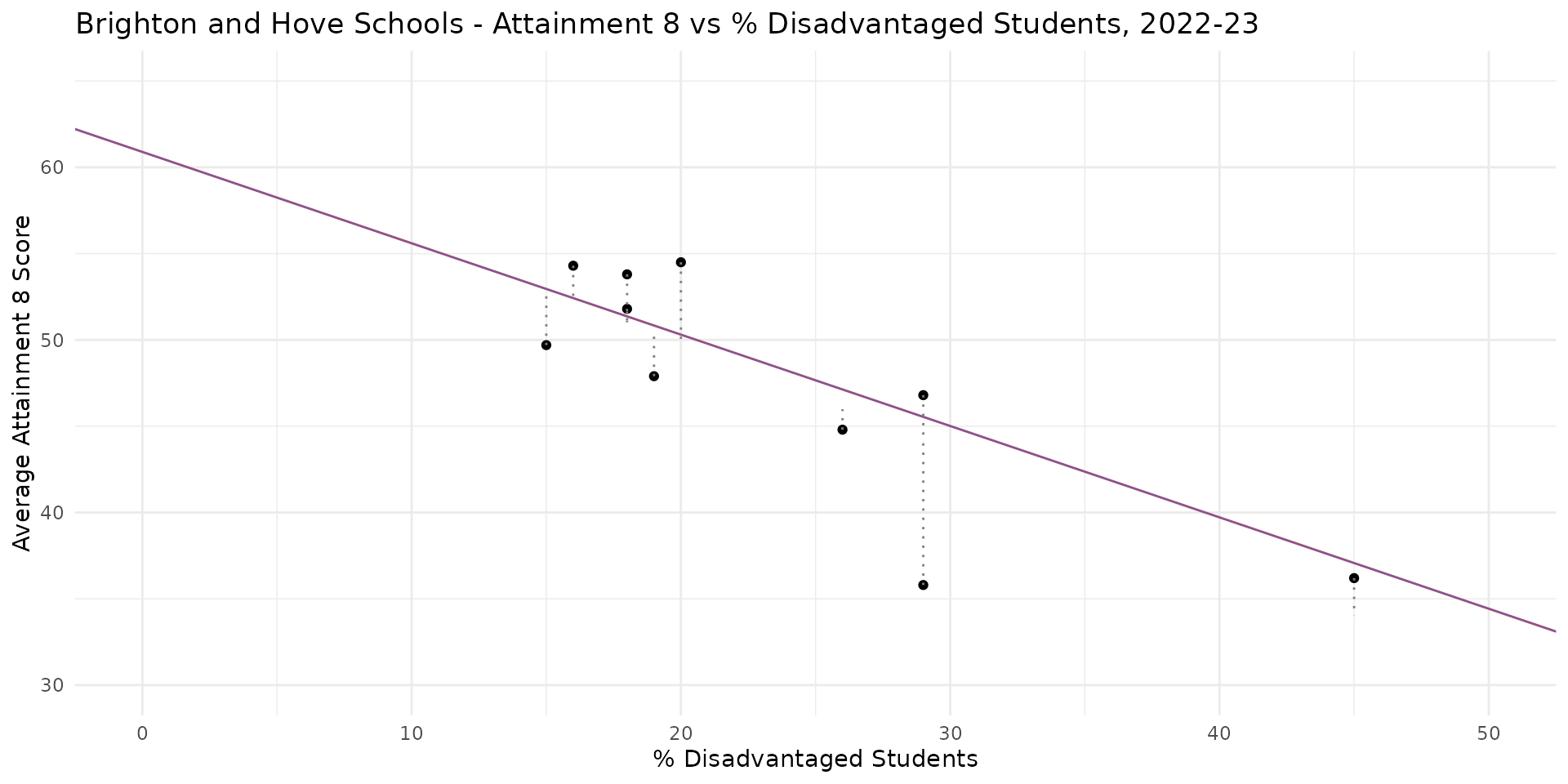
Variation in % disadvantaged students in schools in Brighton appears to explain about 65-68% of the variation in Attainment 8 at the school level
The % disadvantaged students is a statistically significant predictor and the relationship appears to be linear
A 1% reduction in the number of disadvantaged students in a school appears to be associated with a 0.62 point increase in Attainment 8, and vice versa. So the council was right? Well, not quite…
Linear Regression - Overfitting, Outliers and High Leverage Points
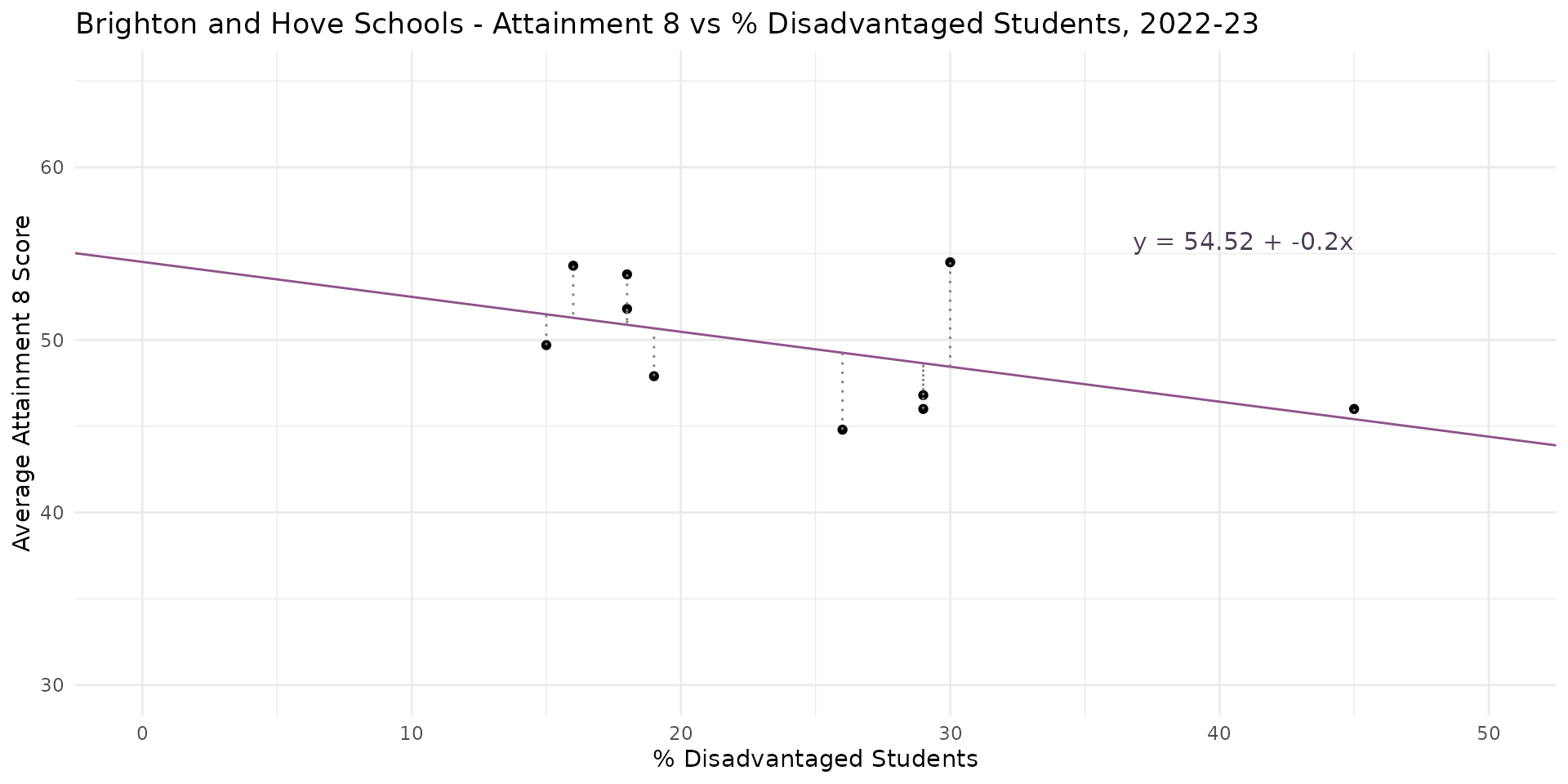
- Plausible changes to three schools have almost completely removed relationship between % Disadvantaged Students & Attainment 8
- Overfitting -> parameters highly sensitive to minor changes to a few key data points
- The closer the best-fit line gets to horizontal, the closer we get to NO RELATIONSHIP between the independent and dependent variables
Linear Regression - More Degrees of Freedom
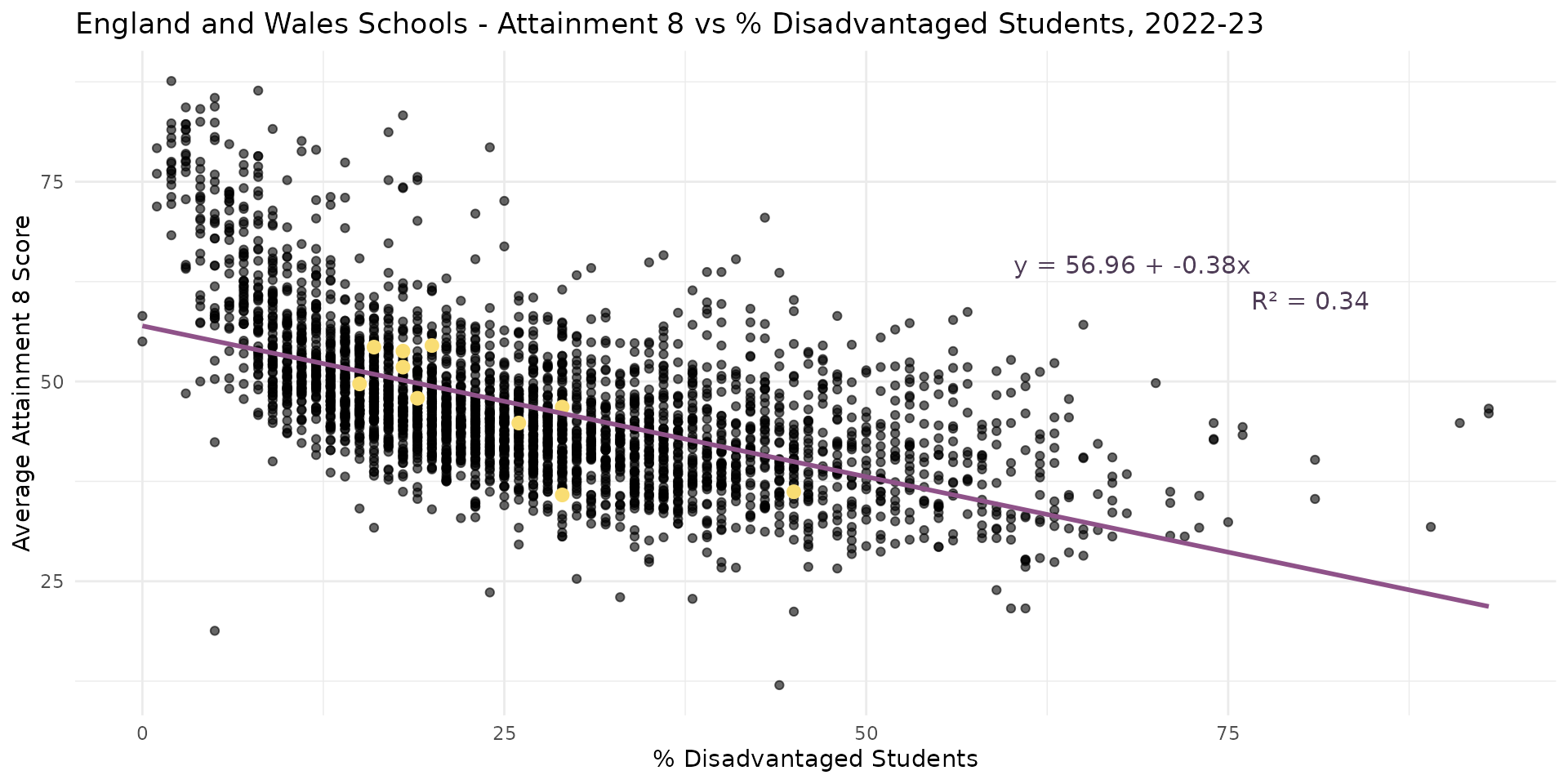
- Now we have a model that includes all schools in England and Wales
- Negative association present - appears to confirm Gorard’s observation
- R-Squared is reasonable - 34% of the variation explained
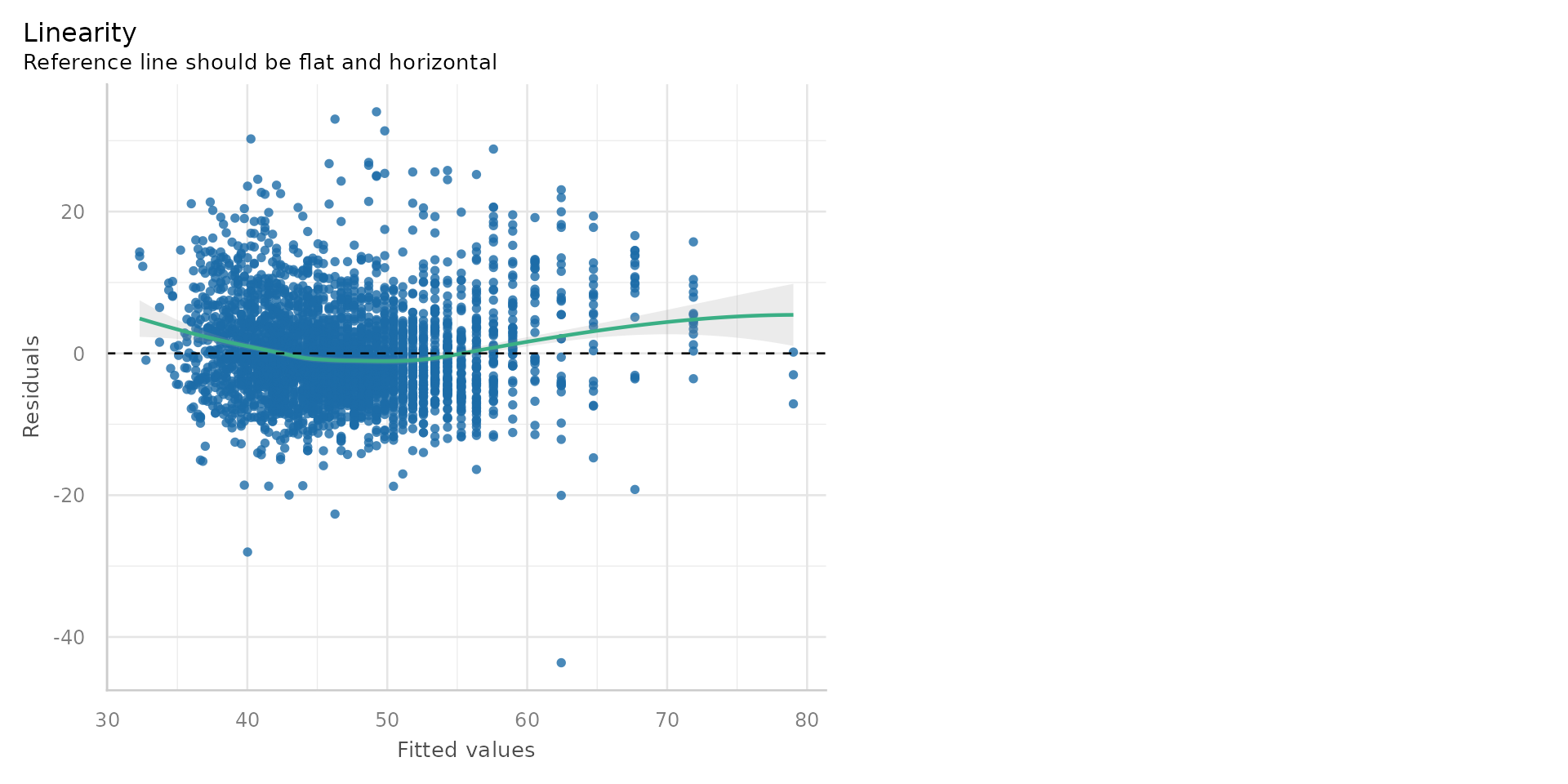
Linear Regression - Linearity?
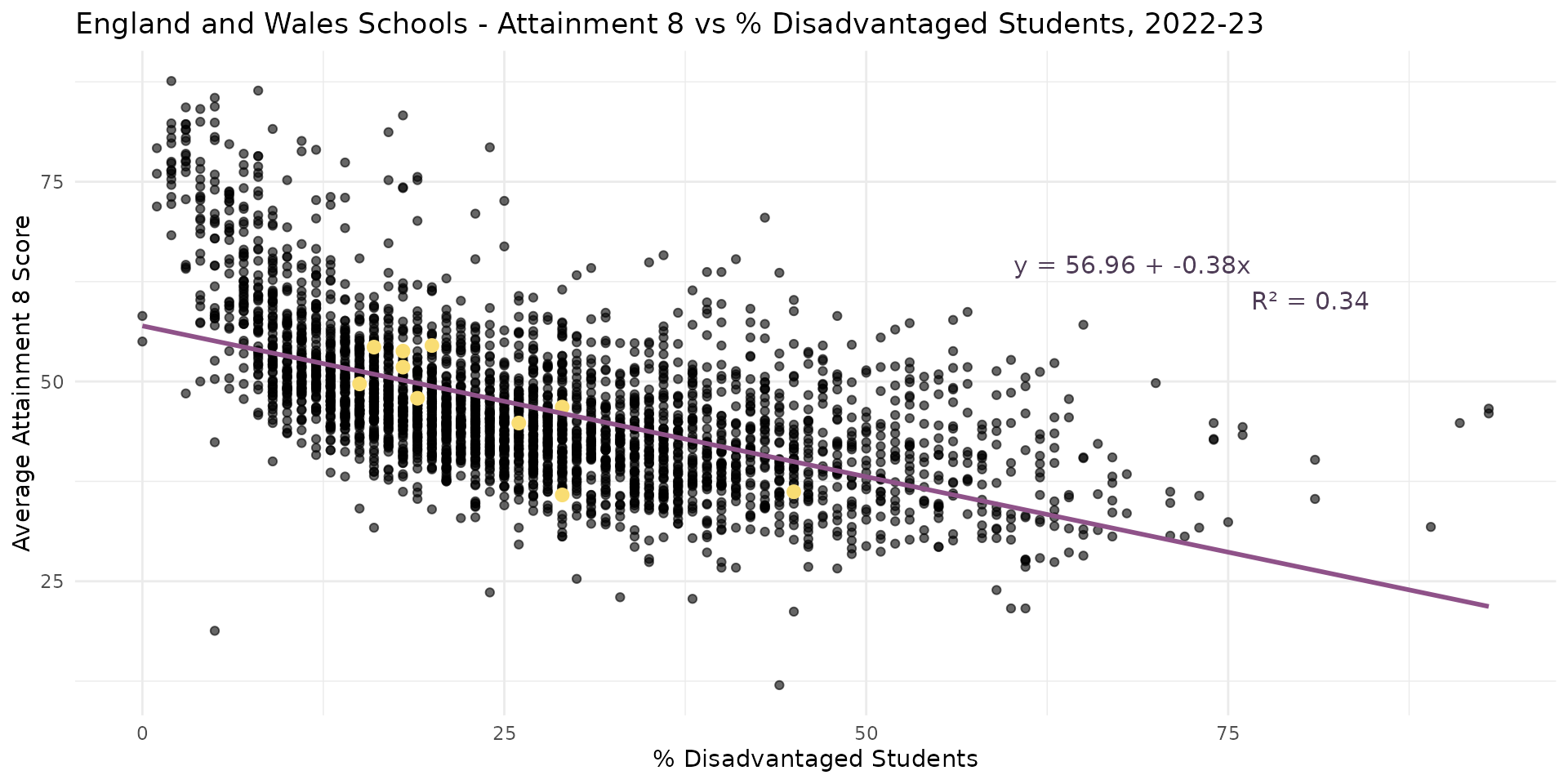
- Linearity - Does your line go through all the points nicely?
- Hmmmm - suggestion of non-linearity with big up-tick at the low end of disadvantage
Linear Regression - Linearity?
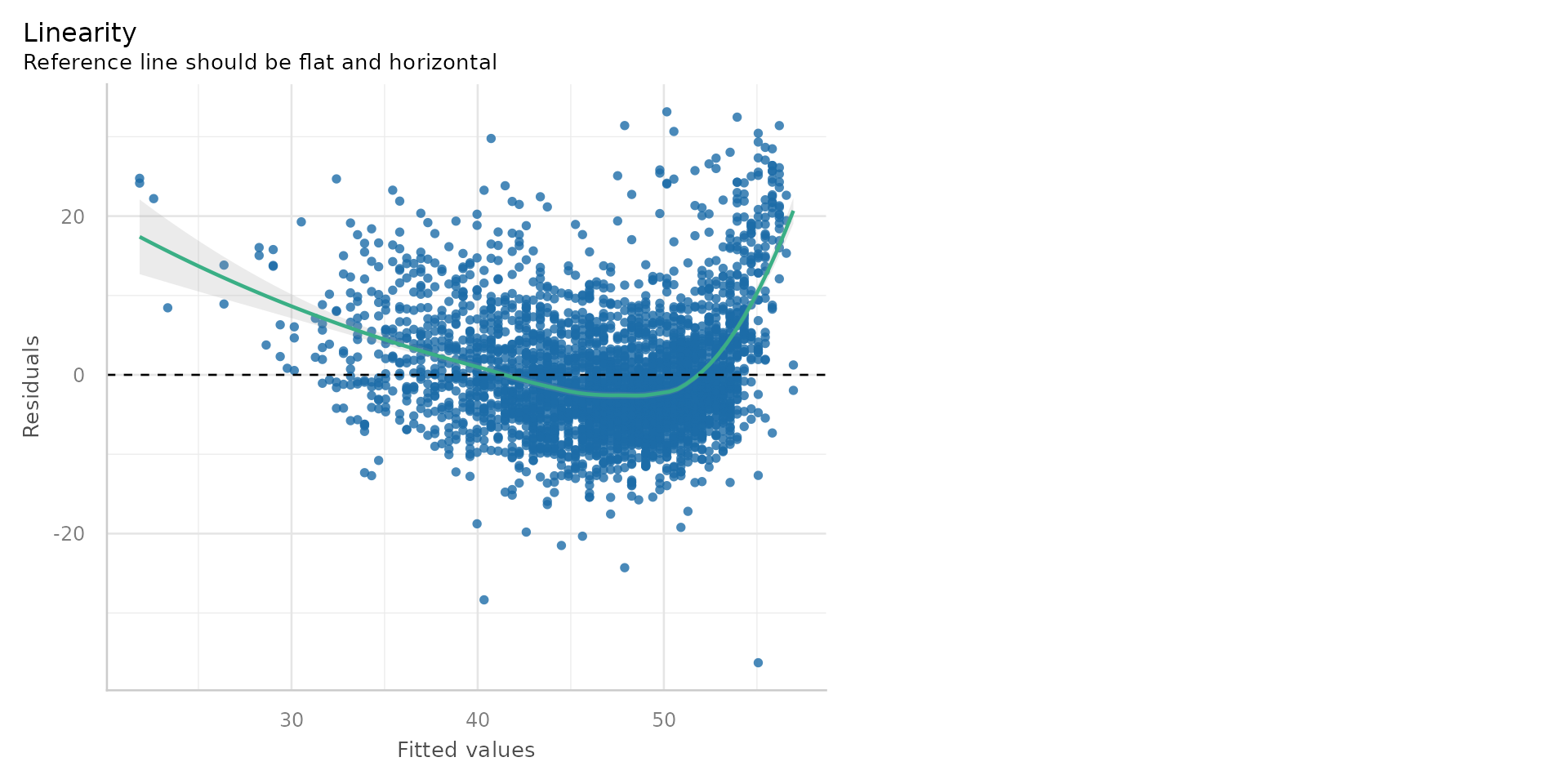
- Ploting the residuals against the fitted values is one check for linearity
- The residuals should be randomly scattered around zero - if they are not, it suggests a non-linear relationship
- The reference line should be horizontal at zero
Linear Regression - Homoscedasticity (Constant variance)?
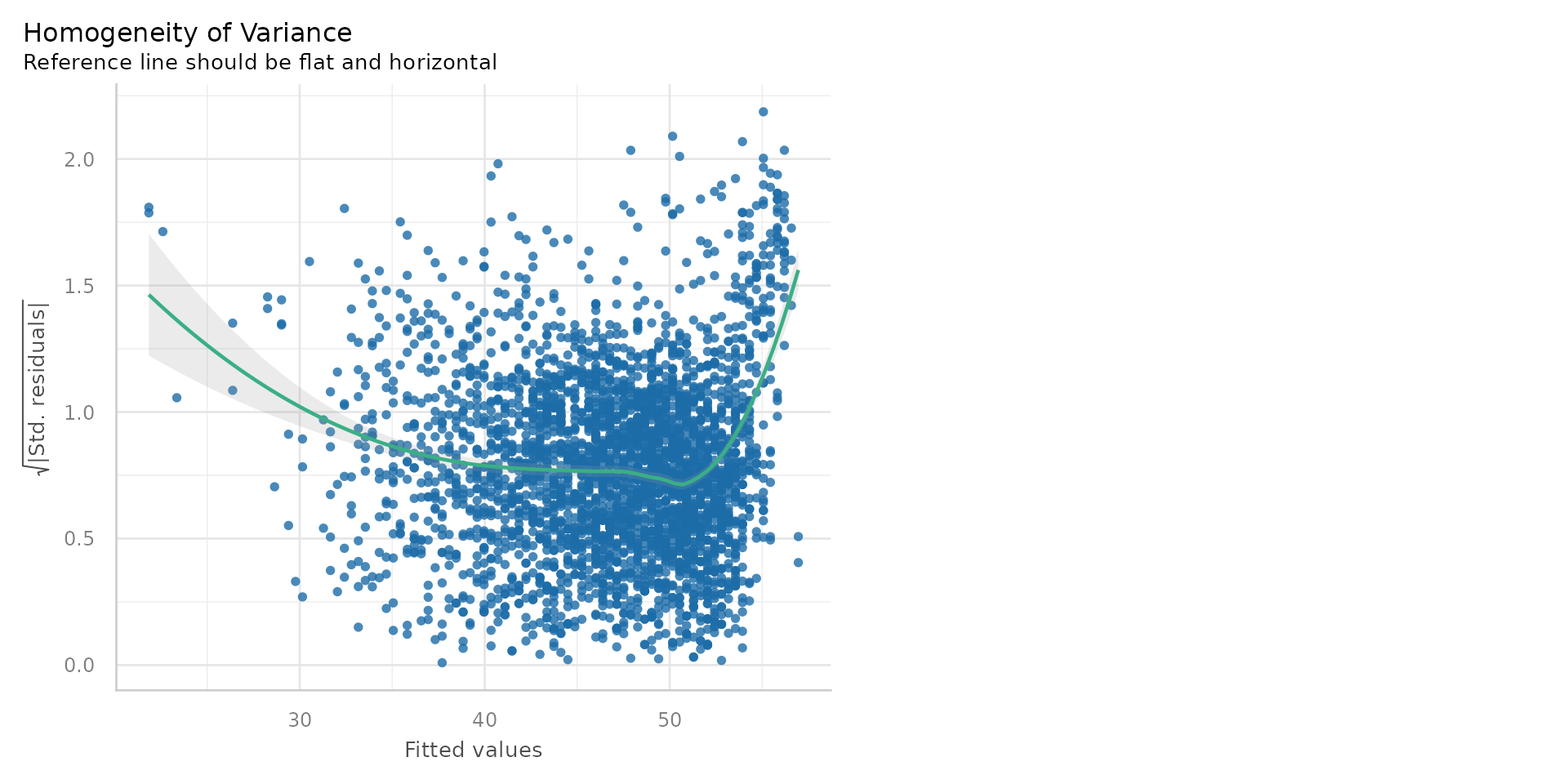
- Issues here too: the residuals are not randomly scattered around zero
- They are instead displaying heteroscdasticity (different variance)
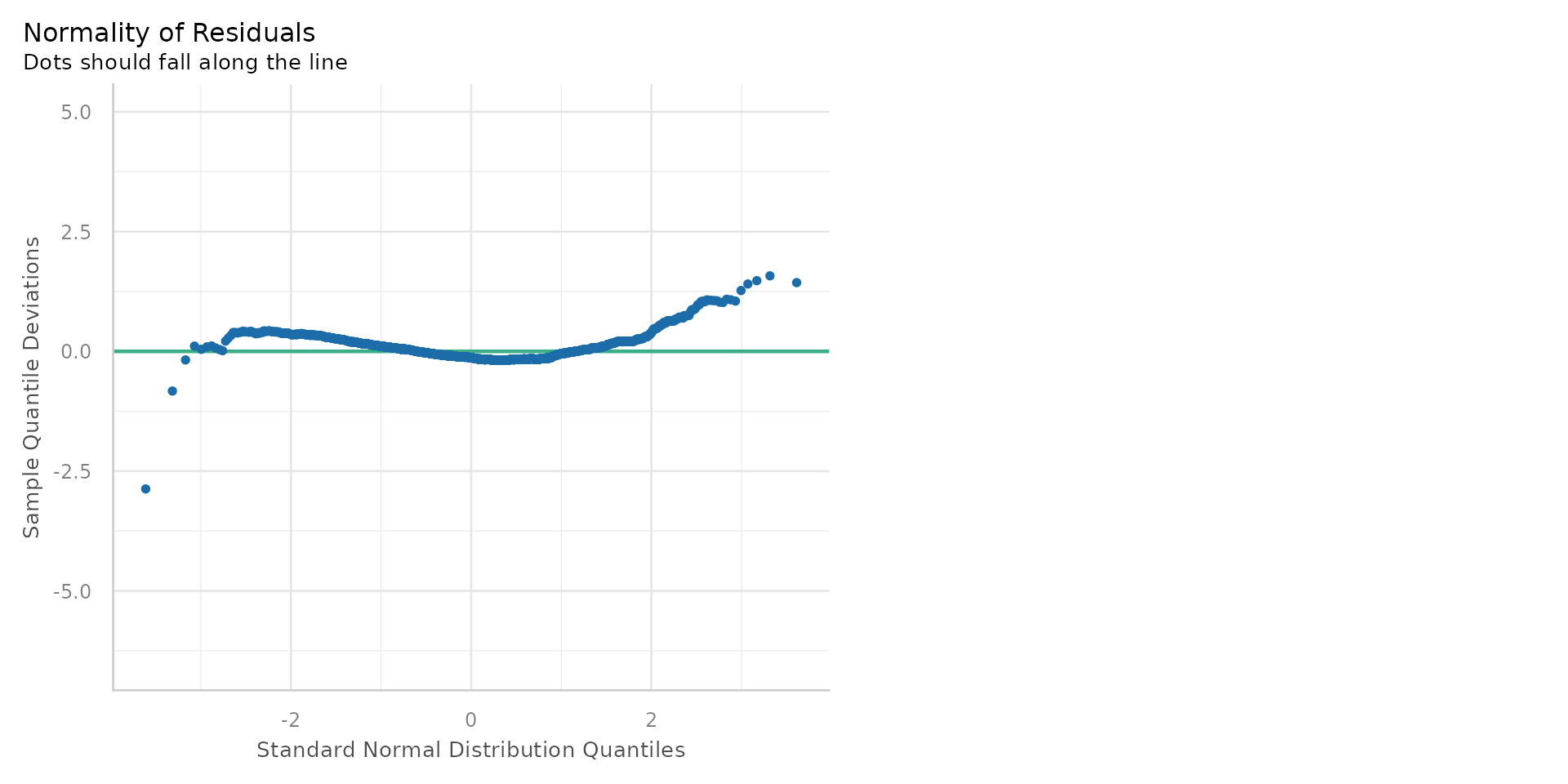
Linear Regression - Normality of Residuals?
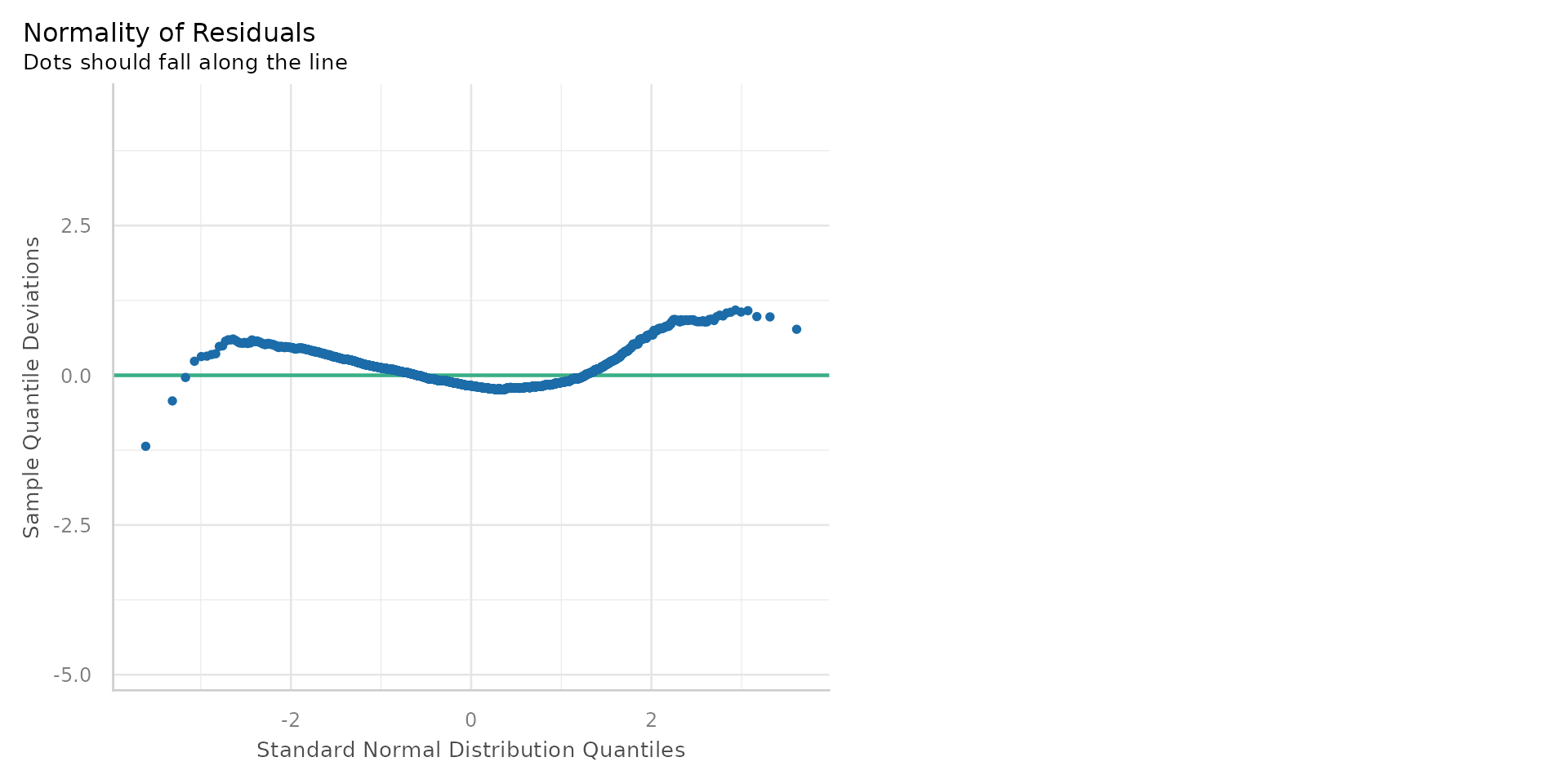
- This is known as a Q-Q plot (Quantile-Quantile plot)
- A number of points not on the line - suggesting the residuals are not normally distributed
- Many points off line could mean untrustworthy p-values
Linear Regression - Outliers?
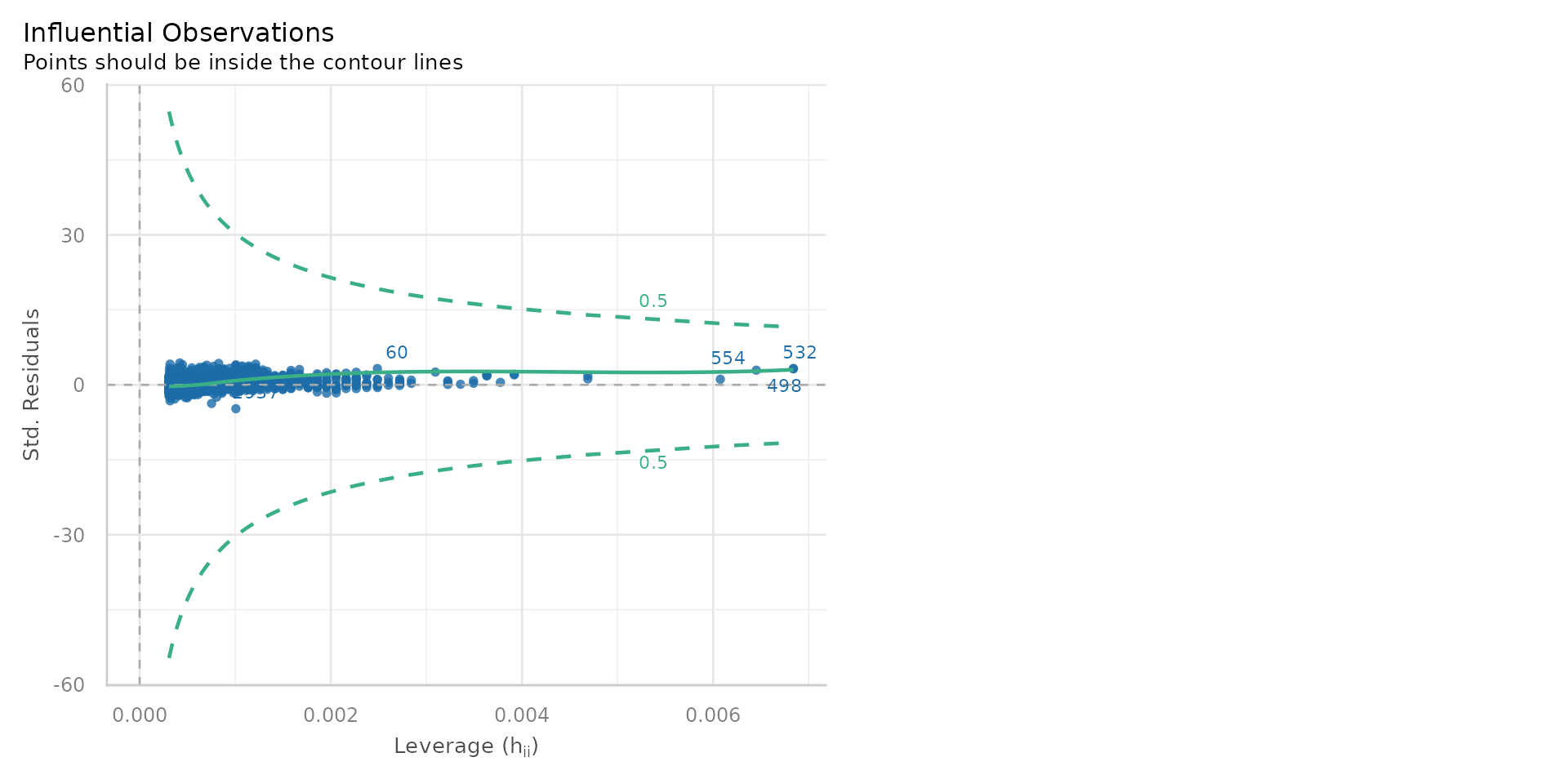
- At least we don’t have any problems with outliers!
Linear Regression - Non-Linearity
\[log(Y) = \beta_0 + \beta_1log(X_1) + \epsilon\]
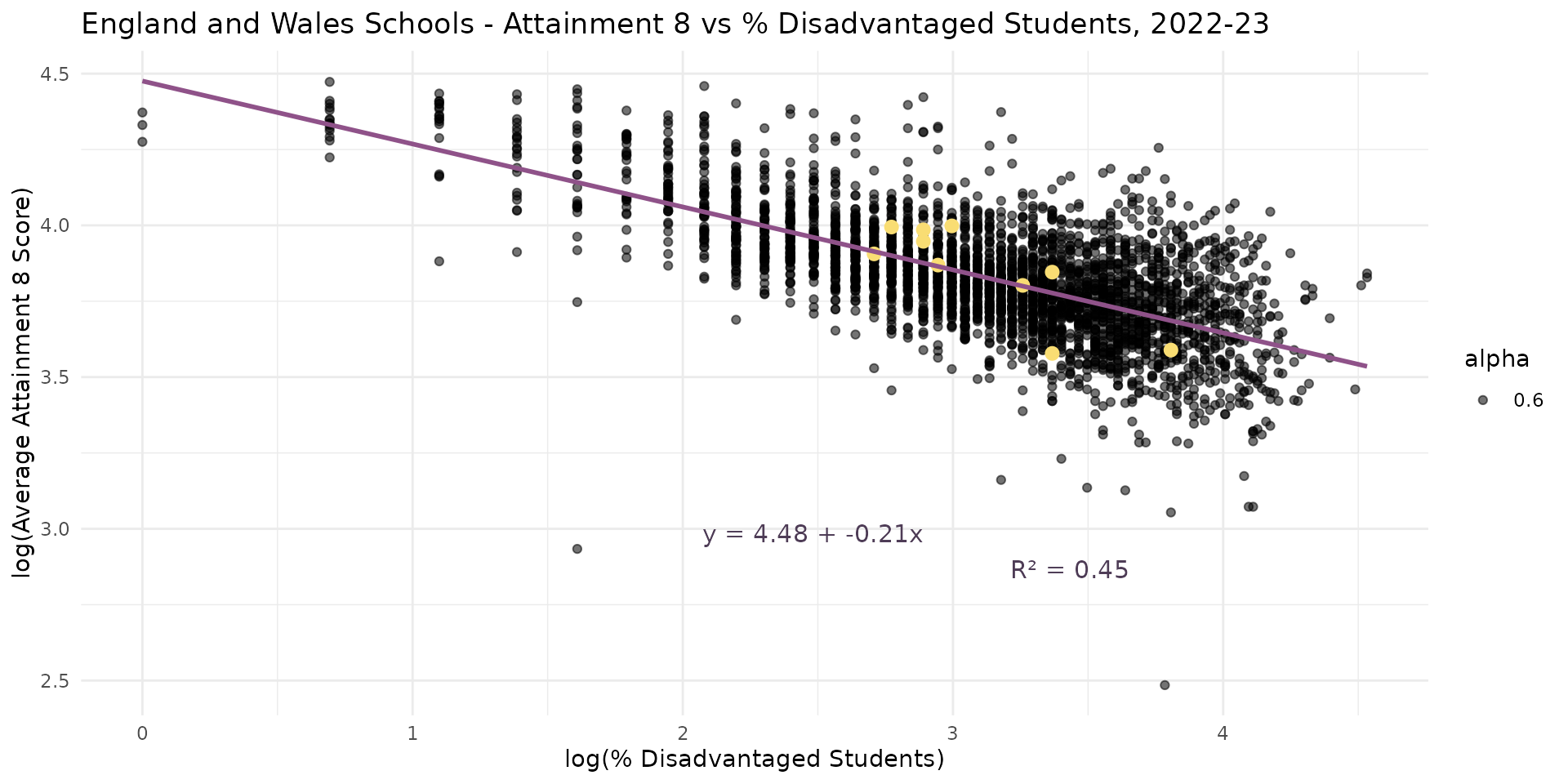
- The log(\(Y\)) log(\(X\)) model is a standard transformation of these variables that can help to linearise relationships
- Sometimes referred to as an elasticity model - a % (rather than constant) change in \(X\) leads to a % (not constant) change in \(Y\)
Linear Regression - the log-log transformation
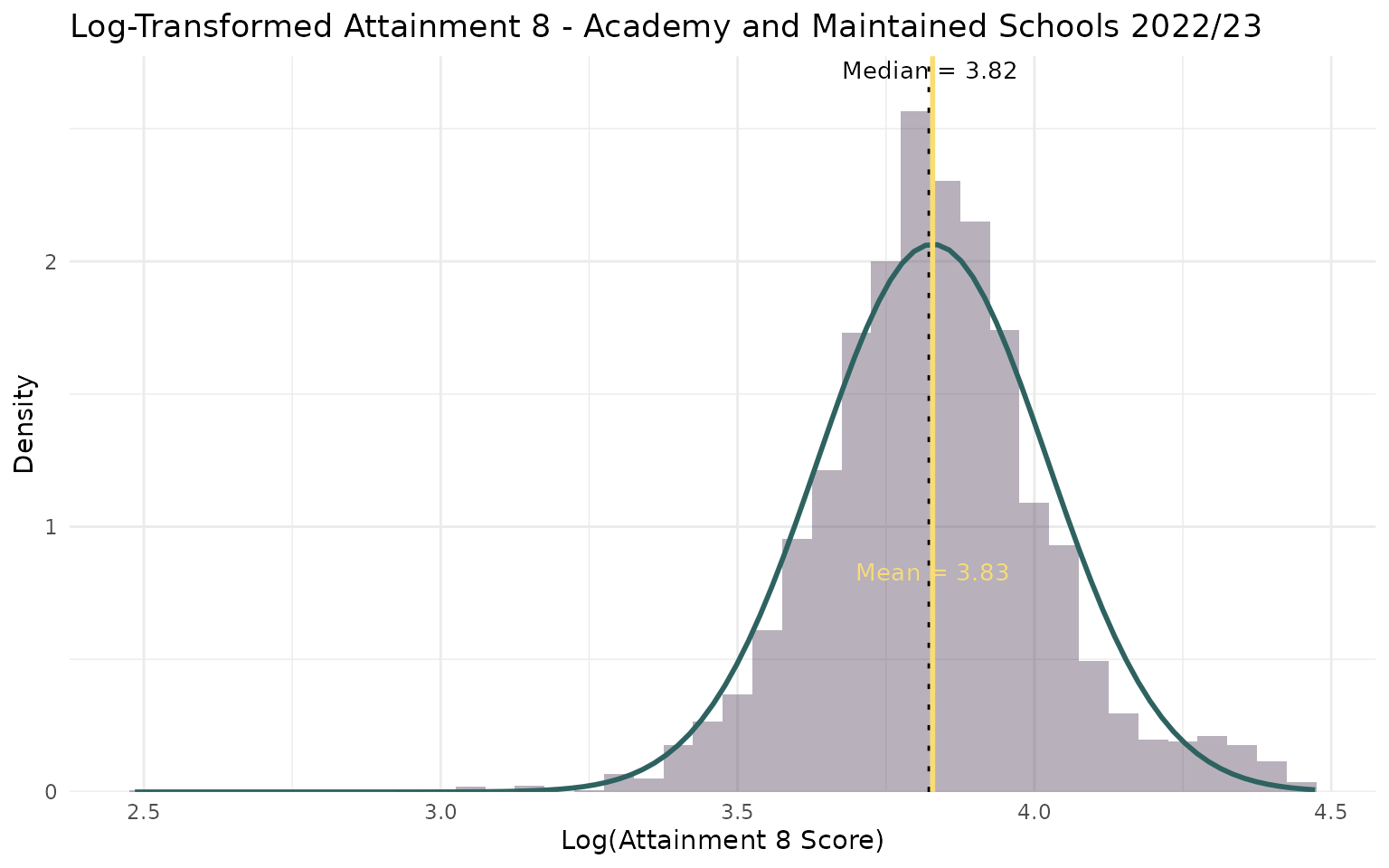
Linear Regression - the log-log transformation
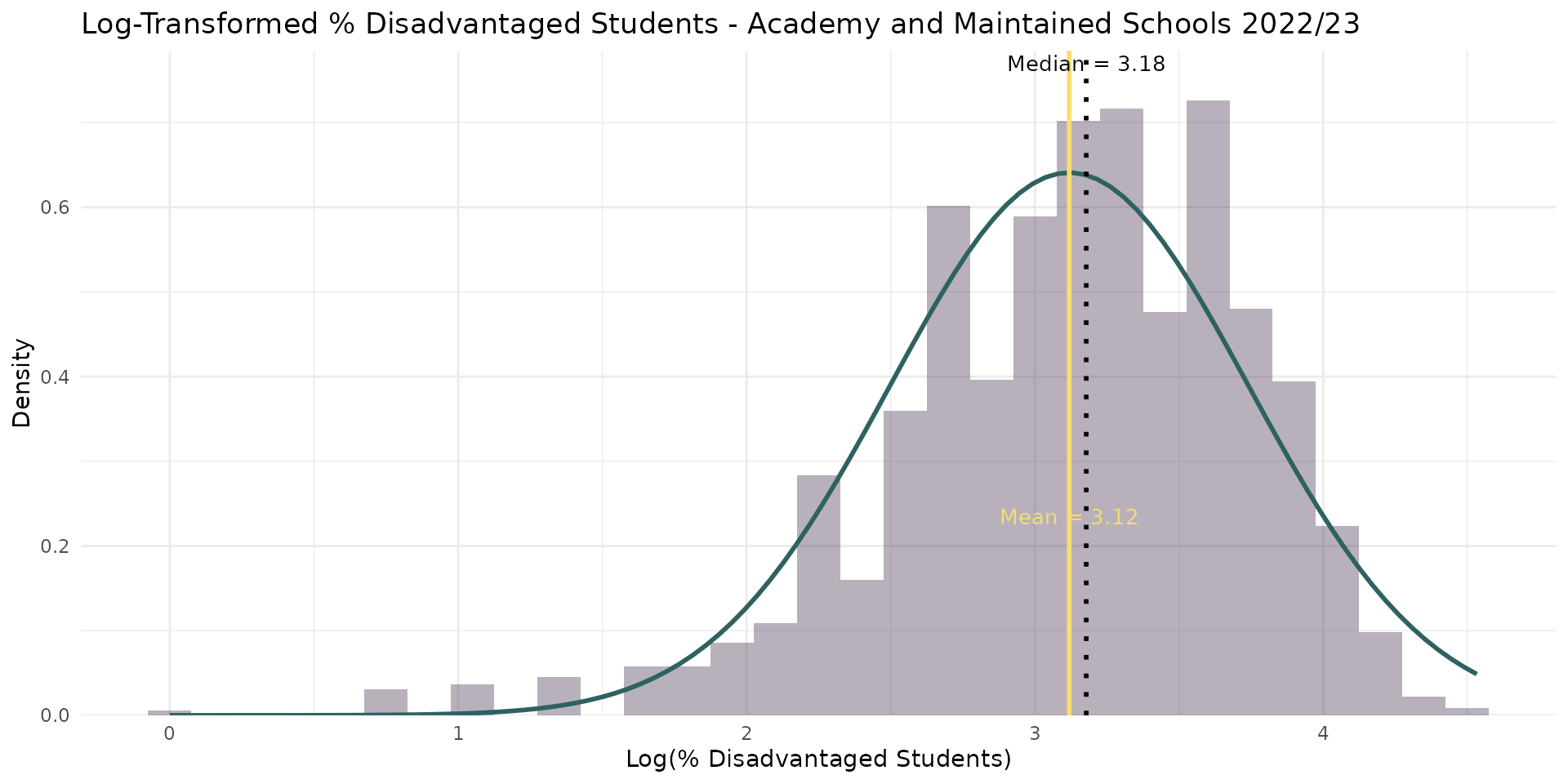
Linear Regression - the log-log transformation
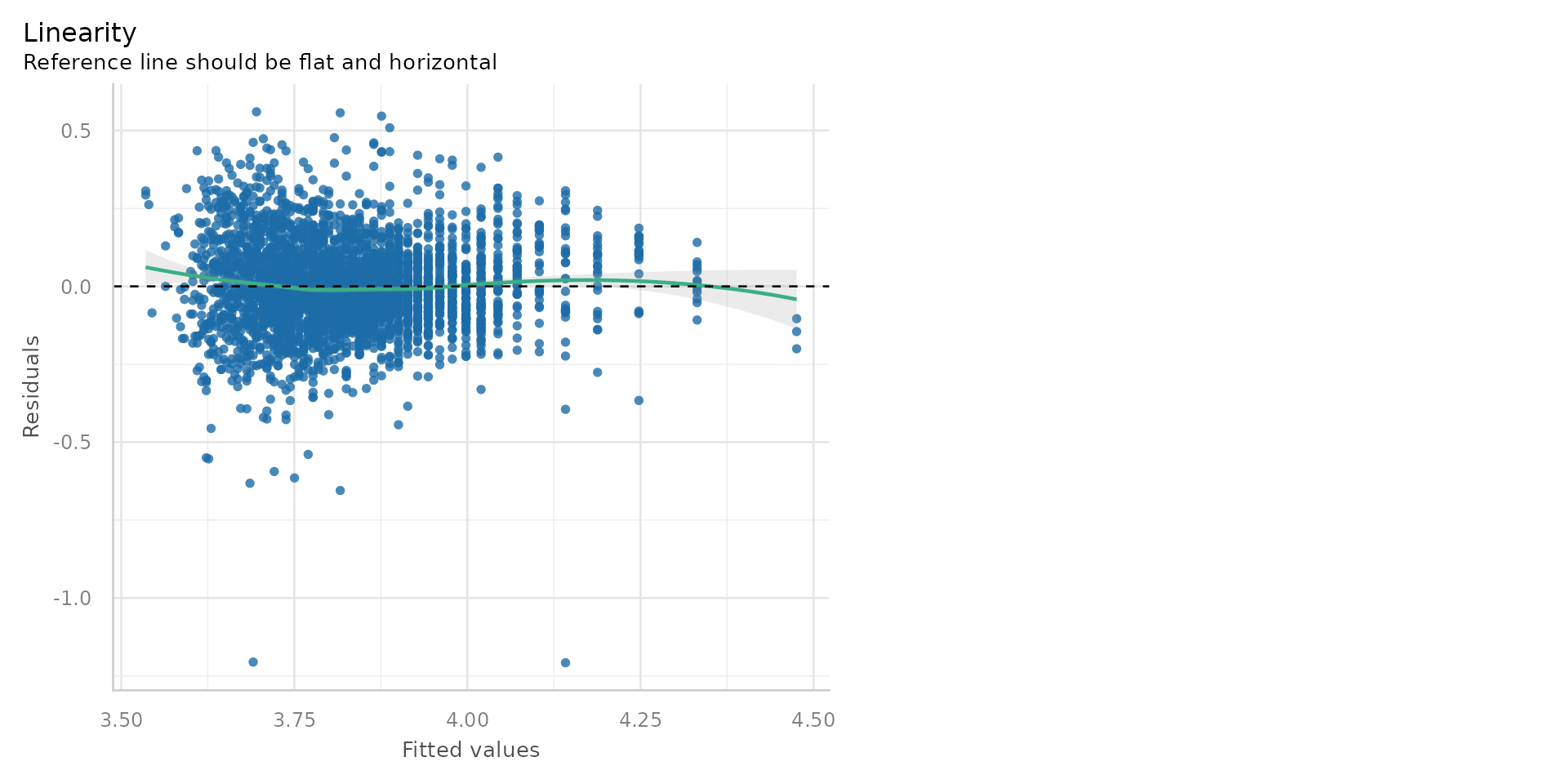
- The residuals are now randomly scattered around zero - suggesting a linear relationship
Linear Regression - the log-log transformation
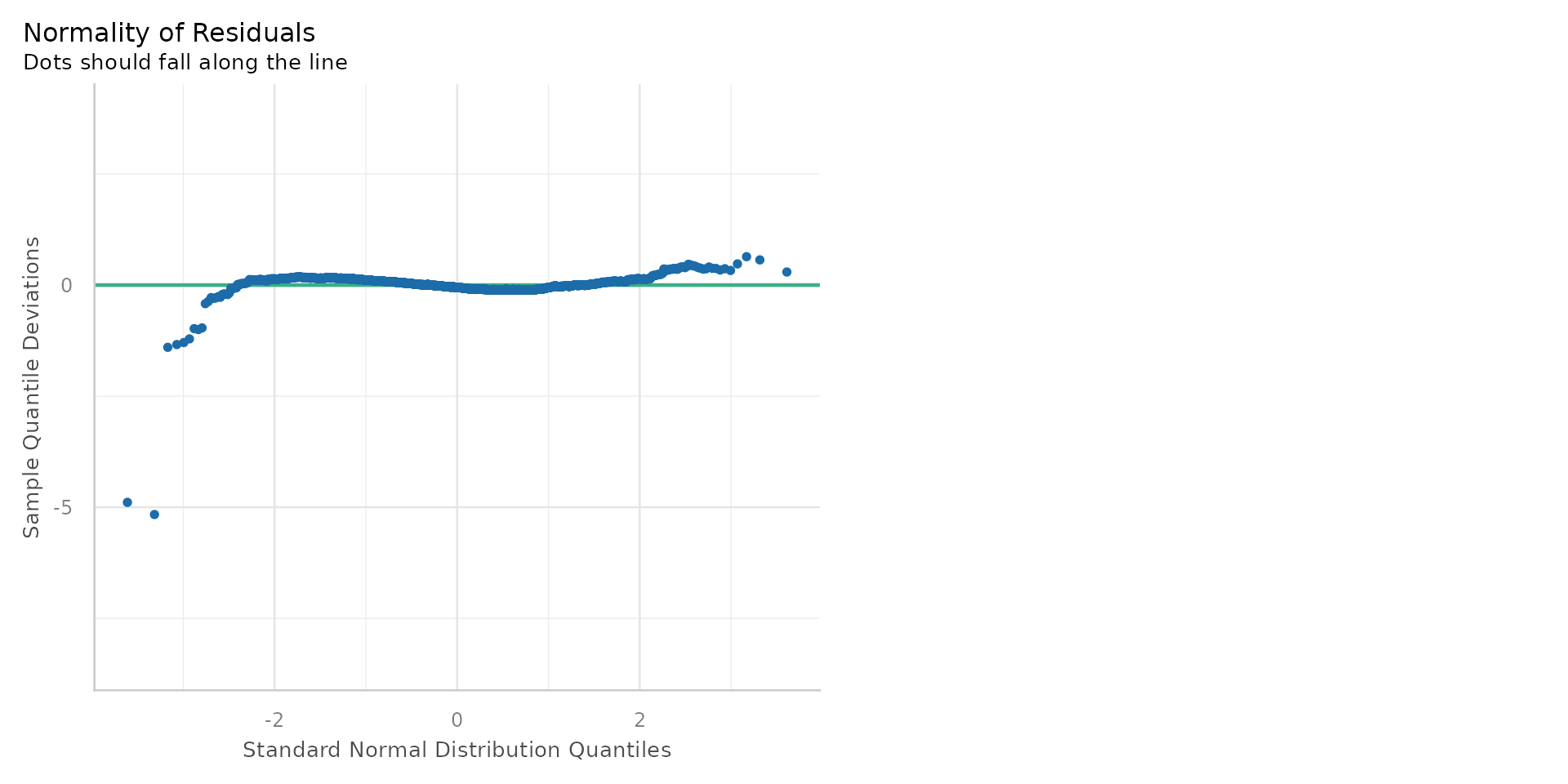
- The residuals are now normally distributed - the Q-Q plot shows most points on the line
Linear Regression - Level-log model
\[Y = \beta_0 + \beta_1log(X_1) + \epsilon\]
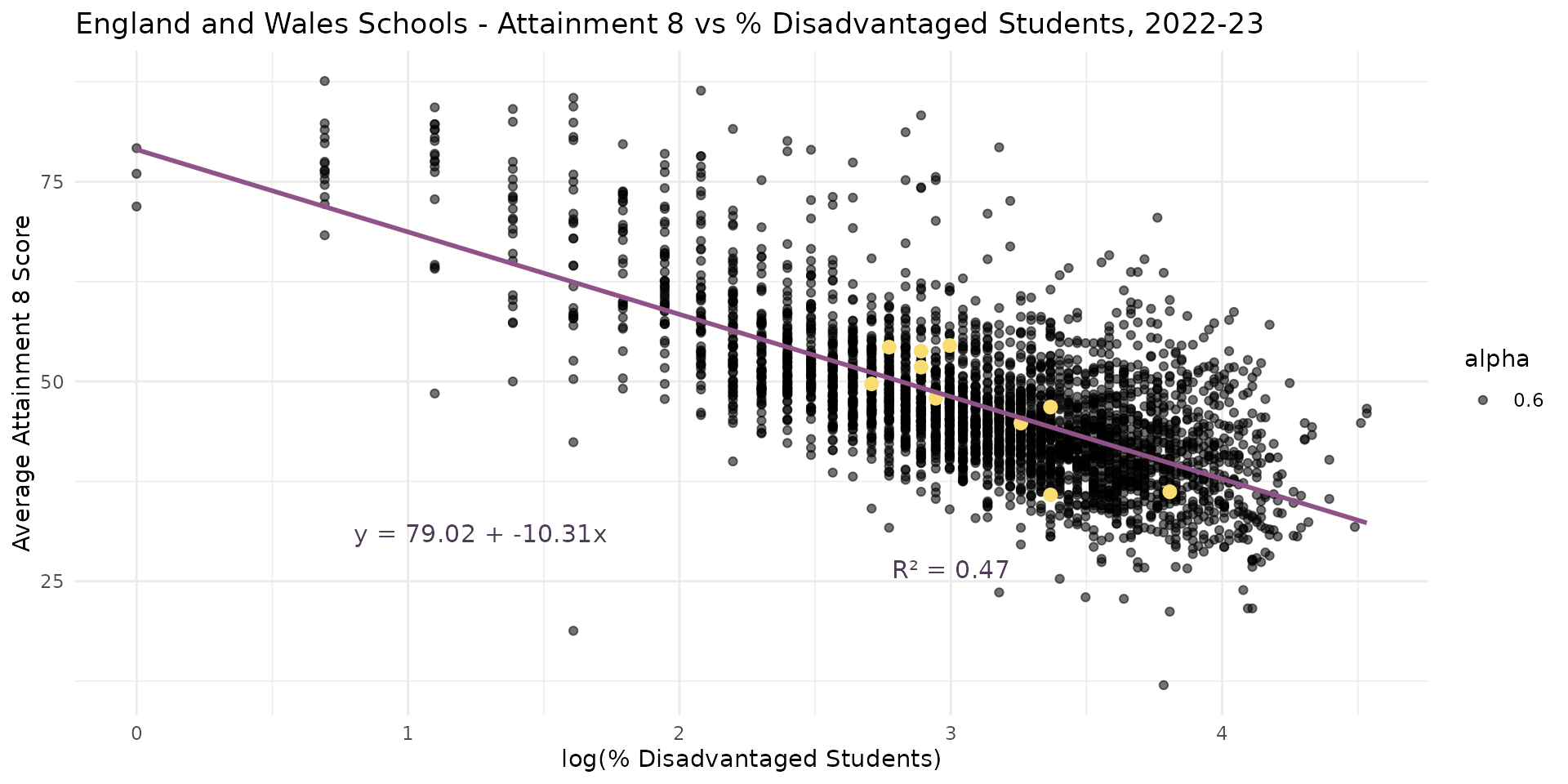
- Other options are to use a level-log model, where the dependent variable is not transformed but the independent variable is log-transformed.
- Use when the effect of the independent variable has diminishing returns - e.g. a change from \(log(2.7%)\) or \(exp(1)\) to \(log(7.3%)\) \(exp(2)\) disadvantaged students has same effect as a change from \(log(20%)\) \(exp(3)\) to \(log(54.5%)\) \(exp(4)\)
Linear Regression - Level-log model
Linear Regression - Level-log model