Hypothesis Testing
Establishing and evaluating research hypotheses
Beatrice Taylor - beatrice.taylor@ucl.ac.uk
8th October 2025
Last week
Overview of lecture 2
Continued concepts from exploratory data analysis, in particular probability distributions.
- Representative data
- Normal distribution
- Binomial distribution
- Poisson distribution
- Exponentials
- Logarithms
This week
Motivation
How do we understand how likely events are to occur?
Question
What is the probability of someone at UCL being over 190cm?
Answer
Try to understand the distribution of heights.
The scientific method
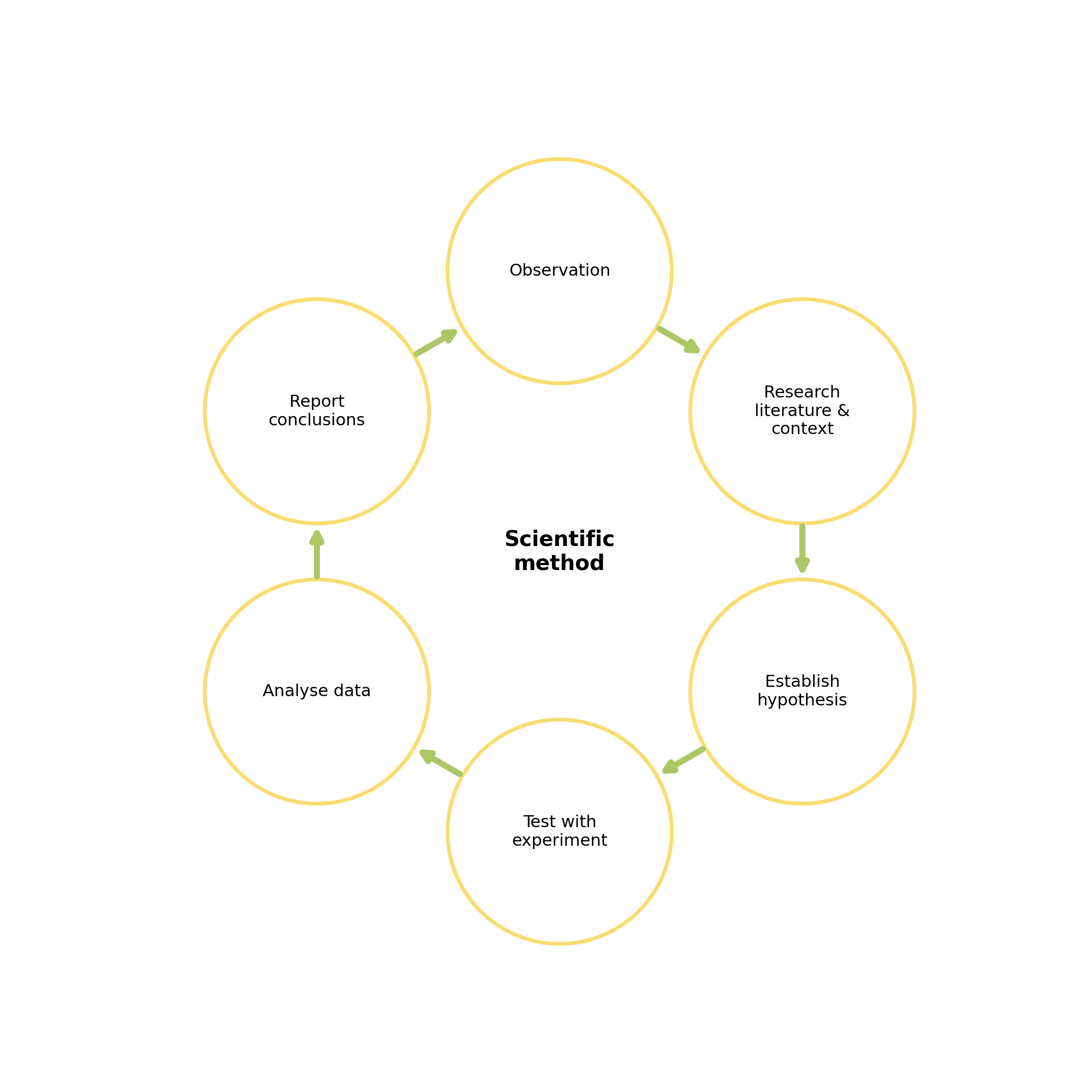
Statistical tests: - formal way to define a threshold of what is an interesting result - and hence evaluate the hypothesis
Learning Objectives
By the end of this lecture you should be able to:
- Establish a hypothesis for a given research project.
- Define the Type I and Type II errors.
- Evaluate a hypothesis using appropriate statistical tests.
How do you come up with a hypothesis?
Research question vs. hypothesis
Research question
A research question focuses on a specific problem.
Hypothesis
A formal statement that you will seek to prove or disprove.
Flip a coin
- You have a coin.
- You think it’s a fair coin.
- You toss it 10 times.
- It comes up heads 7 times.
What do you think is the hypothesis here?
The hypothesis
- You have a coin.
- You think it’s a fair coin.
- You toss it 10 times.
- It comes up heads 7 times.
The evidence
- You have a coin.
- You think it’s a fair coin.
- You toss it 10 times.
- It comes up heads 7 times.
What question can you ask?
- You have a coin.
- You think it’s a fair coin.
- You toss it 10 times.
- It comes up heads 7 times.
Is it a fair coin?
What’s the probability that it’s fair?
If the coin is fair, how likely would it be to see 7 heads out of 10 flips?
What question should you ask?
- You have a coin.
- You think it’s a fair coin.
- You toss it 10 times.
- It comes up heads 7 times.
Correct formulation:
If the coin is fair, how likely would it be to see 7 heads out of 10 flips or an even more extreme result?
Establishing and evaluating a hypothesis
In five simple steps.
Step 1
Define the null and alternative hypothesis
\(H_0\) - the null hypothesis
- this is the “status quo”
- it is assumed to be true
\(H_1\) - the alternative hypothesis
- your hypothesis
- it requires some evidence (i.e. data) to verify
- it directly contradicts the null hypothesis
Step 2
Set your significance level \(\alpha\)
The significance level is the threshold below which you reject the null hypothesis.
- Decide what “too unlikely” means
- Common choice is 5% significance
- \(\alpha = 0.05\)
- This means that if we see evidence that would have less than a 5% chance of occurring under the null hypothesis, then we reject the null hypothesis.
WARNING
Decide what “too unlikely” means before you do the test

- otherwise considered ‘HARKing’
- Hypothesising
- After
- the
- Results
- are
- Known
Step 3
Identify the evidence
- This could mean collecting the data
- Or identifying a suitable existing dataset
- Crucial that it’s suitable - think about biased/ unrepresentative data
Step 4
Calculate the p-value
The p-value is the probability of seeing the evidence, or something even more extreme, if the null hypothesis is true.
- Calculated according to the appropriate statistical test
- The choice of test is determined by the research question and the data
Step 5
Compare p-value with significance level
- p-value \(> \alpha\)
- Evidence not that unlikely.
- Not enough evidence to reject \(H_0\).
- p-value \(\leq \alpha\)
- Evidence very unlikely.
- Reject \(H_0\) and accept \(H_1\).
The steps
In order to evaluate our hypothesis we just have to do the five steps:
- Define the null and alternative hypothesis
- Set you significance level
- Identify the evidence
- Calculate the p-value
- Compare p-value with hypothesis level
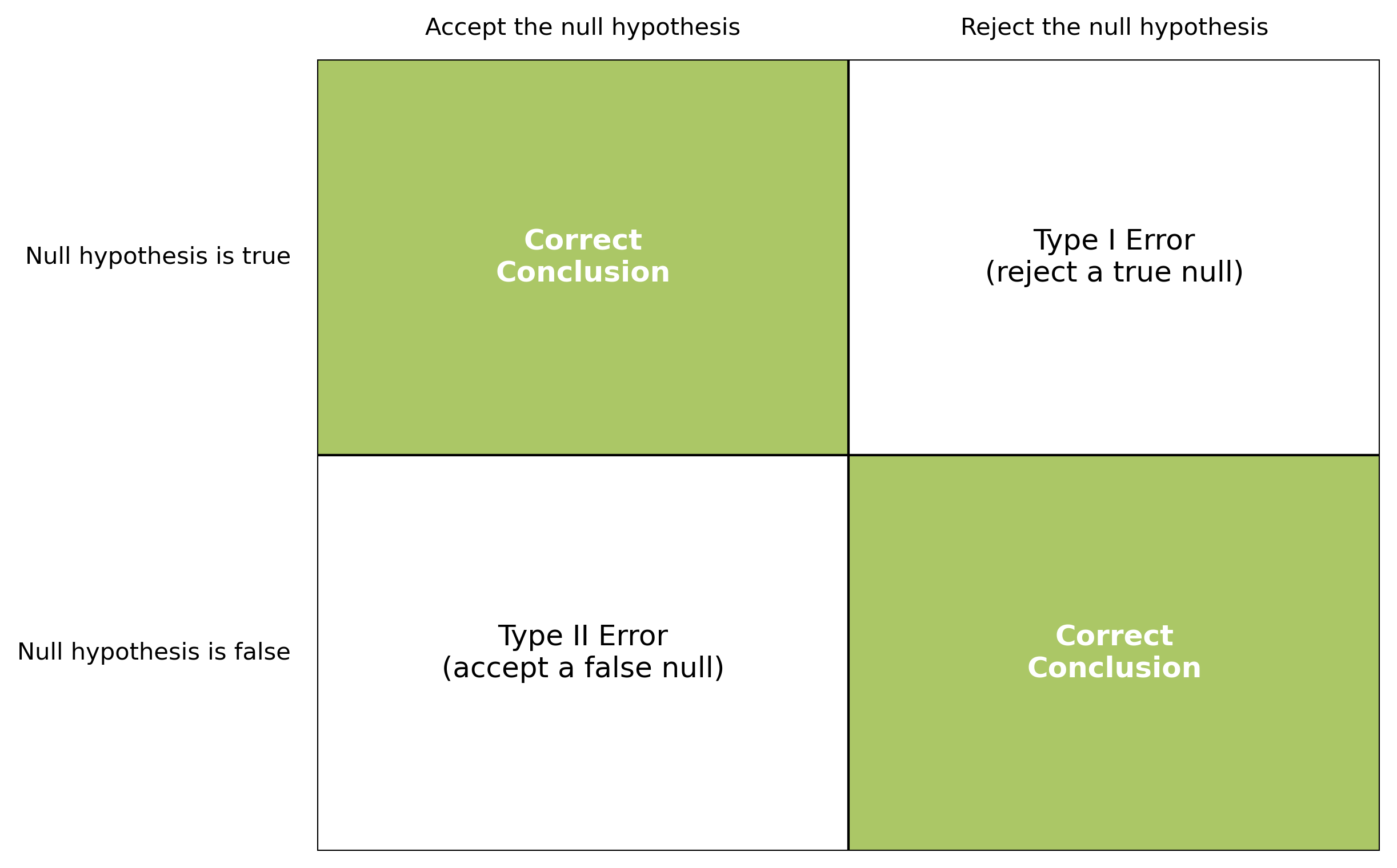
Types of error
… where things can go wrong.
Type I error
The true null hypothesis is incorrectly rejected.
The null hypothesis is true, but you get a false positive leading to you rejecting the null hypothesis.
This is also called a false positive.
Example: In court a defendant is found guilty despite being innocent.
Type II error
The false null hypothesis is incorrectly accepted.
The null hypothesis is false, but you get a false negative result, leading you to accepting the null hypothesis.
This is also called a false negative.
Example: In court a defendant is found innocent despite being guilty.
Example: Mammograms

NHS offers breast cancer screening for all people with breasts between the ages of 50 and 70.
Example: Screening outcomes
The hypothesis:
\(H_0:\) The individual doesn’t have breast cancer.
\(H_1:\) The individual does have breast cancer.
Example: Evaluating the evidence
From NHS digital.
Type I error: false positive
- In 2020-2021, 4.0% of those screened had an abnormal results and were referred for assessment.
- Of these, 77.1% were found to not have breast cancer at follow up assessment.
- Leading to a false positive rate of 3.1%.
Example: Evaluating the evidence
From NHS digital.
Type II error: false negative
- Those who had a negative screening but did in fact have breast cancer.
- Harder to calculate the false negative rate, as they might be diagnosed with breast cancer at any later point in time.
- Studies suggest the false negative rate could be as high as 20%.
Matrix of errors
A good hypothesis or a bad hypothesis?
Understanding the literature and the context
The hypothesis should not come out of thin air.
Should consider:
- What do you know about the context?
- What research have other people done?
Asking ethical hypothesis questions
It’s important to not make unethical assumptions in choosing the hypothesis.
Example
Police profiling - assumes a correlation between appearance and crime
- Use contextual knowledge
- Is this causation?
- Or correlation linked to other factors?
Correlation vs. Causation
Correlation: Two variables are statistically related, as one changes so does the other.
Causation: One variable influences the other variable to occur.
Causation implies correlation.
BUT correlation does not imply causation!
Aliens and librarians
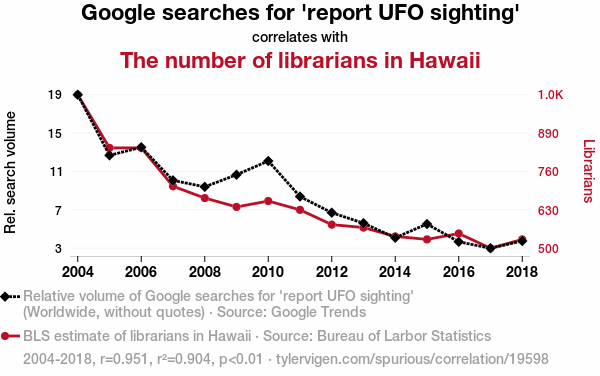
Image credit: [Spurious Correlations](https://www.tylervigen.com/spurious/correlation/19598_google-searches-for-report-ufo-sighting_correlates-with_the-number-of-librarians-in-hawaii)Correlation IS NOT causation
You might not know whether events are correlated, or causing each other
BUT
you should use your contextual understanding to come up with plausible (and ethical) initial questions.
The point of the scientific method
It’s a process
- question
- test
- evaluate
- REPEAT!
Example: students height
Research question
Are male and female students similar heights?
Research hypothesis
Male and female students are different heights on average.
Example - step 1
Define the null and alternative hypothesis
\(H_0\): The mean height of male and female students is the same.
\(H_1\): The mean height of male and female students is different.
Example - step 2
Set your significance level
\(\alpha = 0.05\)
Example - step 3
Identify the evidence
I’ve collected data from 198 students, as follows:
| Group | Sample Size | Mean (cm) | std (cm) |
|---|---|---|---|
| Female students | 95 | 170 | 5 |
| Male students | 103 | 180 | 6 |
Example - step 4
Calculate the p-value
Aha!
How do we do this? We need to know what statistical test to use!
Statistical tests
Numerically testing whether the data supports the hypothesis.
Parametric vs. Non-parametric tests
Parametric tests
- Assumptions about the distribution:
- Normal distribution
- Independent and unbiased samples
- Equal/comparable variances
- Continuous data
Non-parametric tests
- Typically less assumptions on the distribution
- Continuous or discrete data
Deciding on a test
Parametric tests
Student’s T-test
Student’s T-test is used to compare the mean of a dataset.
- parametric statistical test
- assumes the data is normally distributed

This is William Sealy Gosset - he was **not** a student.
Image credit: https://en.wikipedia.org/wiki/William_Sealy_Gosset#/media/File:William_Sealy_Gosset.jpgStudent’s T-test: steps
Calculate:
- test statistic (called the t value)
- The test statistic is a number that summarises the data so as to determine whether to reject the null hypothesis.
- degrees of freedom
- The number of degrees of freedom is the number of values in the final calculation that are free to vary.
Which we use to identify the p value - typically using a ‘look up table’.
Student’s T-test: types
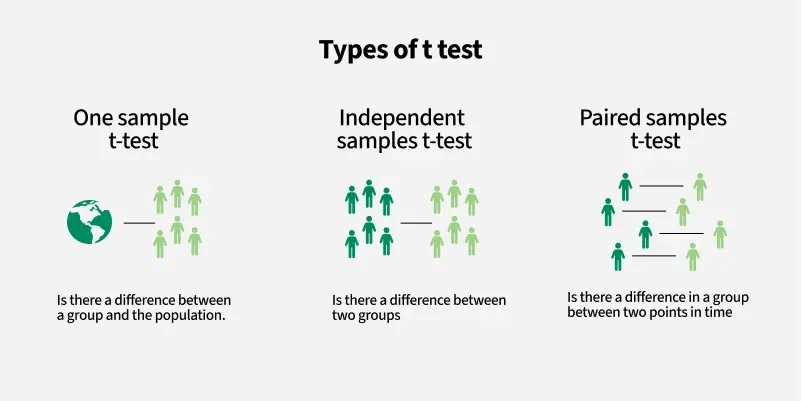
Image credit: https://www.geeksforgeeks.org/data-science/t-test/Student’s T-test: one sample
Tests whether the population mean is equal to a specific value or not
The test statistic is calculated as:
\[\begin{align} t = \frac{\bar{x} - \mu_{0}}{s / \sqrt{n}} \end{align}\]where
- \(\bar{x}\) is the sample mean
- \(\mu_{0}\) is the hypothesised population mean
- \(s\) is the sample standard deviation
- \(n\) is the sample size
Student’s T-test: one sample, degrees of freedom
The number of degrees of freedom is the number of values in the final calculation that are free to vary.
\[\begin{align} df = n-1 \end{align}\]Student’s T-test: two sample
Tests if the population means for two different groups are equal or not.
The test statistic is:
\[\begin{align} t = \frac{\bar{x}_1 - \bar{x}_2}{s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}} \end{align}\]- \(\bar{x}_1, \bar{x}_2\) are the sample means of groups 1 and 2
- \(n_1, n_2\) are the sample sizes of groups 1 and 2
- \(s_p\) is the pooled standard deviation
with \(s_1, s_2\) the sample standard deviations.
Student’s T-test: two sample, degrees of freedom
The number of degrees of freedom is the number of values in the final calculation that are free to vary.
In the two-sample Student’s T-test the degrees of freedom are:
\[\begin{align} df = n_1 + n_2 - 2 \end{align}\]Student’s T-test: paired
Tests if the difference between paired measurements for a population is zero or not - normally used with longitudinal data.
The test statistic is:
\[\begin{align} t = \frac{\bar{d}}{s_d / \sqrt{n}} \end{align}\]where
- \(\bar{d}\) is the mean of the paired differences
- \(s_d\) is the standard deviation of the paired differences
- \(n\) is the number of pairs
- the number of degress of freedom is \(n-1\)
How many tails?
Tests can be one-tailed or two-tailed - which you want is determined when you define the hypothesis.
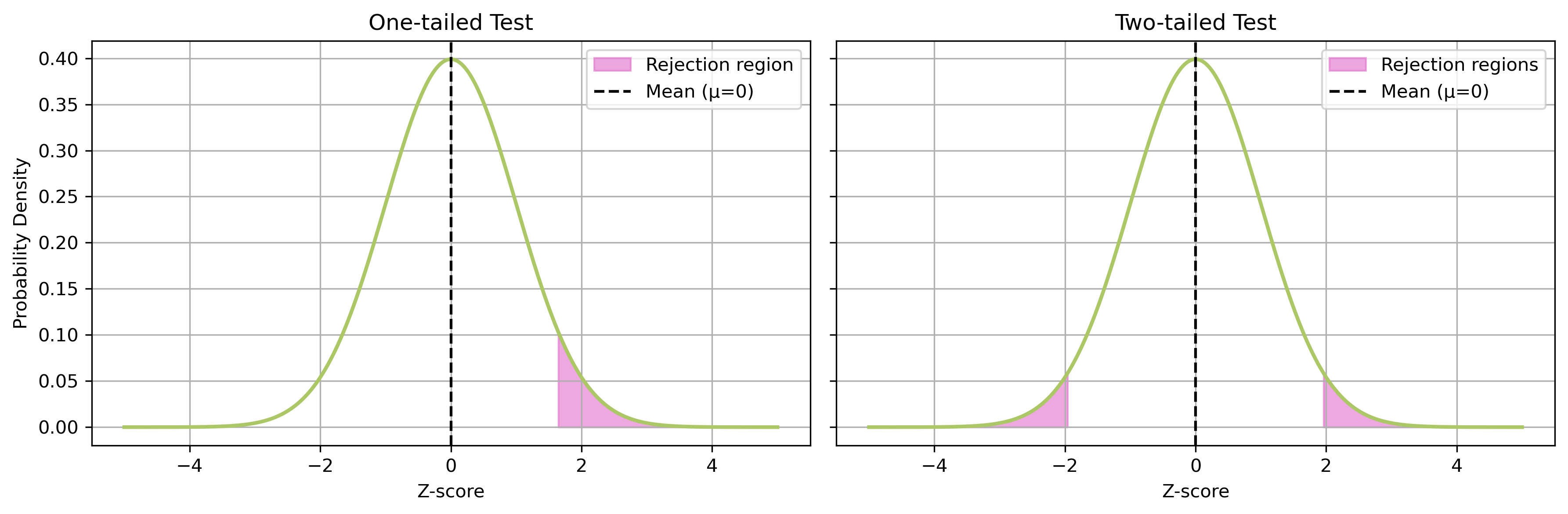
One tailed: if you only care is the mean is significant in one direction
Two tailed: if you care about the mean being different regardless of direction
Non-parametric tests
Kolmogorov-Smirnov
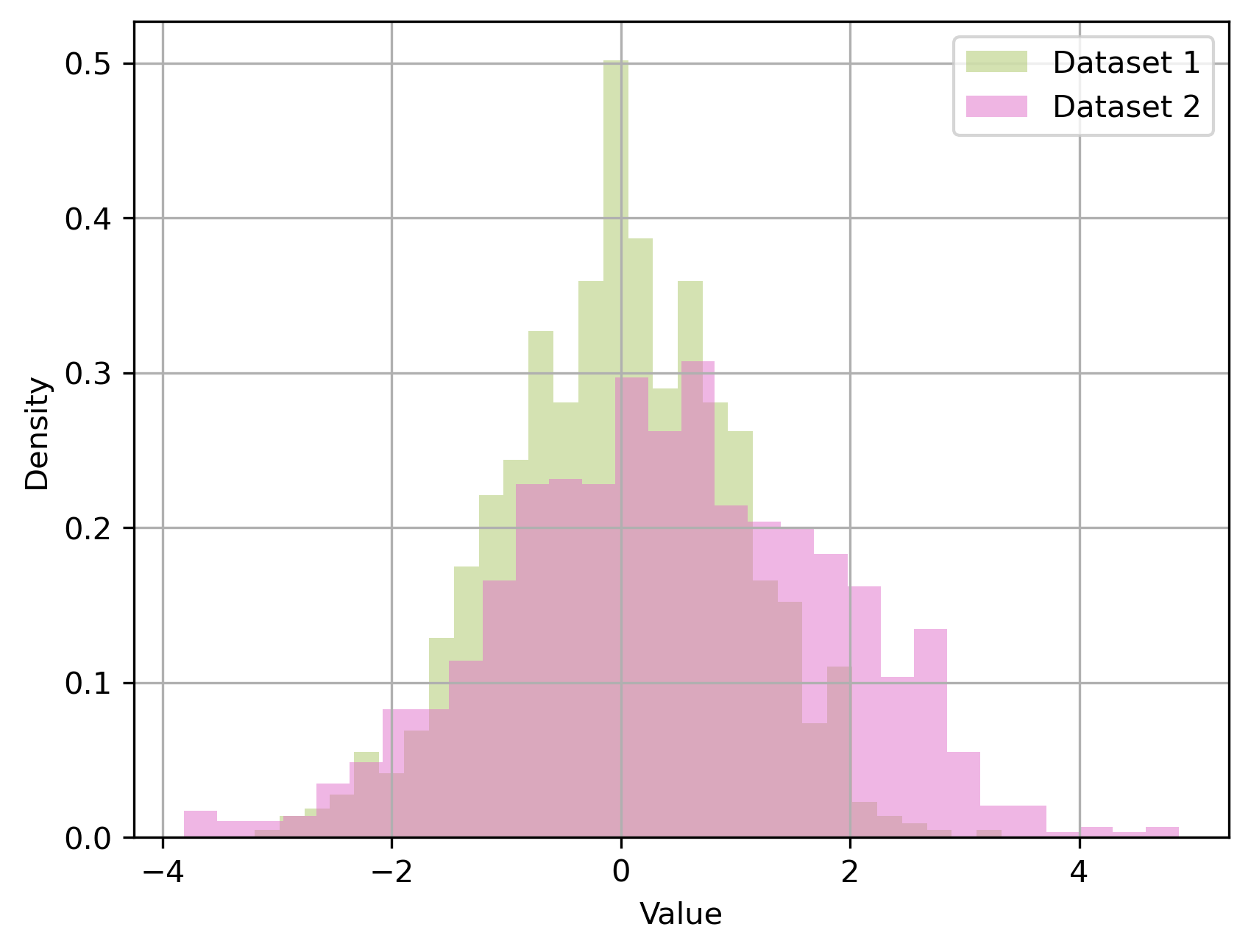
- Compares two probability distributions
- Can be used to test whether an observed sample came from a given distribution
- Or to test whether two samples both came from the same distribution
K-S test: one sample test
Tests if a sample dataset came from a known distribution.
The Kolmogorov–Smirnov test statistic is:
\[\begin{align} D_n = \sup_x \, | F_n(x) - F(x) | \end{align}\]where
- \(F_n(x)\) is the empirical distribution function (EDF) of the sample
- \(F(x)\) is the cumulative distribution function (CDF) of the reference distribution
Note
‘\(sup\)’ is the suprenum - think of it as the smallest upper bound.K-S: empirical distribution function
The empirical distribution function (EDF) is:
\[\begin{align} F_{n}(x) = \frac{1}{n} \sum_{i=1}^{n} 1_{(-\infty ,x]}(X_{i}) \end{align}\]where
- \(n\) is the number of observations
- \(X_i\) are the ordered sample values
- \(1_{(-\infty ,x]}(X_{i})\) is an indicator function (1 if \(X_i \leq x\), else 0)
K-S test: two sample test
Tests if the underlying distributions of two sample datasets are the same.
For the two-sample test:
\[\begin{align} D_{n,m} = \sup_x \, | F_n(x) - G_m(x) | \end{align}\]where
- \(F_n(x)\) and \(G_m(x)\) are the EDFs of the two samples.
K-S test: decision rule
The hypotheses would be:
- \(H_0\): the distributions are the same
- \(H_1\): the distributions differ
Larger values of the test statistic \(D\) is stronger evidence against \(H_0\).
Kernel density estimate (KDE)
- Used to generate a smooth probability density function for a random variable dataset
- Useful for understanding the underlying distribution of a sample
- Think of it as getting a smooth function to describe a histogram of data
- There are no assumptions about the prior distribution
KDE of simulated heights
It’s easy to fit a KDE to data in Python:
KDE of simulated heights
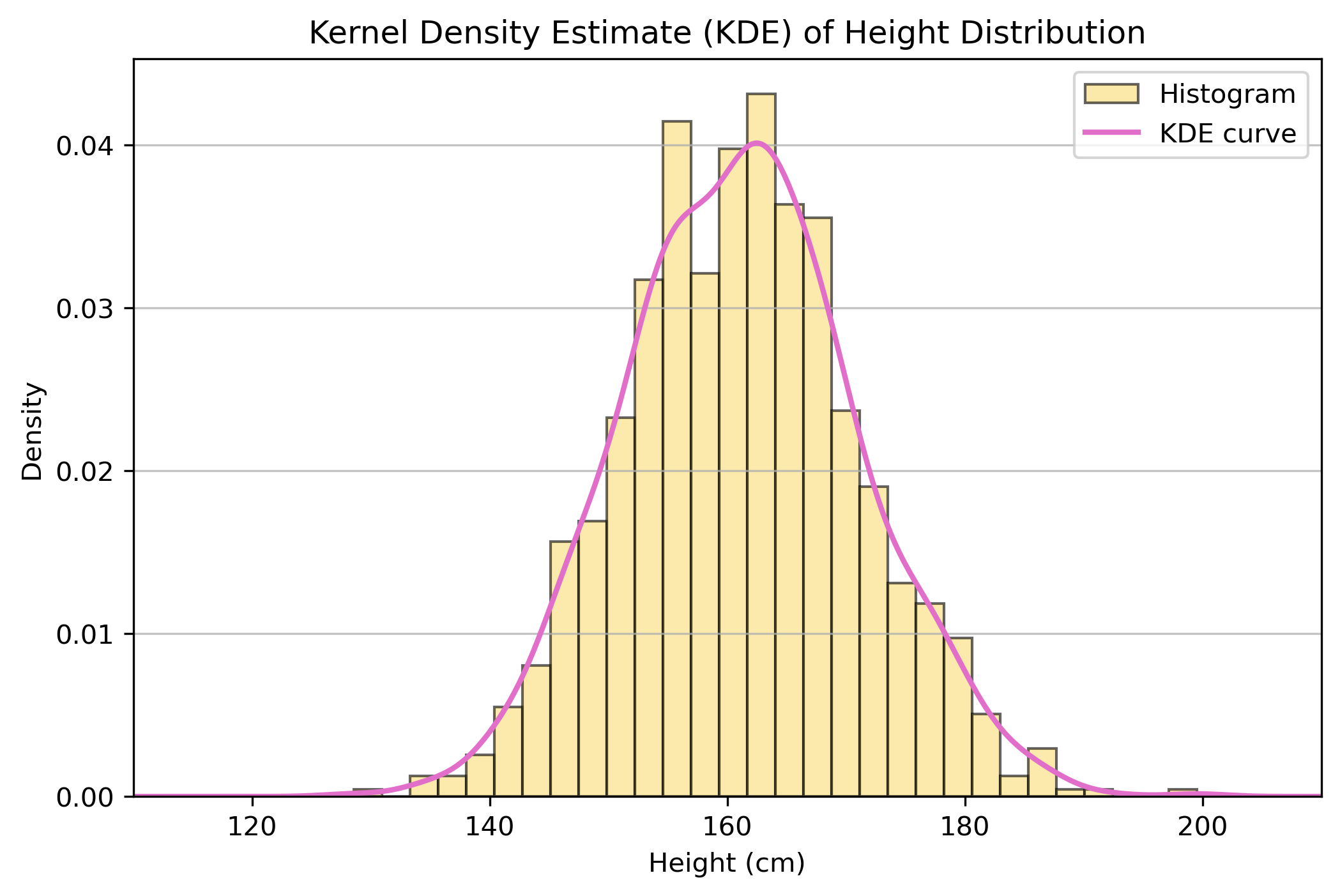
KDE use case
- fit the KDE to two sample datasets
- compare visually
- carry out a non-parametric test - such as Kolmogorov-Smirnov
Example: students height
Example - step 1, 2, 3
Define the null and alternative hypothesis
\(H_0\): The mean height of male and female students is the same.
\(H_1\): The mean height of male and female students is different.
Set your significance level
\(\alpha = 0.05\)
Identify the evidence
Group 1 – female students
\(\bar{x}_1 = 170\), \(s_1 = 5\), \(n_1\) = 95
Group 2 – male students
\(\bar{x}_2 = 180\), \(s_2 = 6\), \(n_2\) = 103
Example - step 4
Calculate the p-value
- Use Student’s T-test: two sample
- Don’t care if students are taller or shorter - so use two-tailed test
- Calculate the t value
- Calculate the degrees of freedom
- Get the p value
Example - step 4 - calculate the t value
Substituting values:
\[\begin{align} s_p &= \sqrt{\frac{(95-1)\cdot 5^2 + (103-1)\cdot 6^2}{95+103-2}} \approx 5.55 \end{align}\]Now compute \(t-value\):
\[\begin{align} t &= \frac{170 - 180}{5.55 \cdot \sqrt{\tfrac{1}{95} + \tfrac{1}{103}}} \approx -12.7 \end{align}\]Example - step 4 - calculate the degrees of freedom
For Student’s T-Test we need degrees of freedom:
\[\begin{align} df = n_1 + n_2 - 2 = 95 + 103 - 2 = 196 \end{align}\]Example - step 4 - calculate the p value
Traditionally this uses look up tables - we’re going to use Python.
Example - step 4 - simplified
We can do all the previous calulations in one step using the `scipy’ library - we’ll practise this in the tutorial.
Example - step 5
Compare p-value with hypothesis level
Now we need to compare the p-value to our siginificance level.
p-value = \(2.0151302848603336e-10 < 0.05\) = alpha
…we reject \(H_0\)!
And conclude that male and female students have significantly different heights.
Questions?
Overview
We’ve covered:
- What makes a good hypothesis
- How to formally state a hypothesis
- Types of statistical tests
Practical
The practical will focus on establishing and evaluating a research hypothesis in python.
Make sure you have questions prepared!
![]()
© CASA | ucl.ac.uk/bartlett/casa