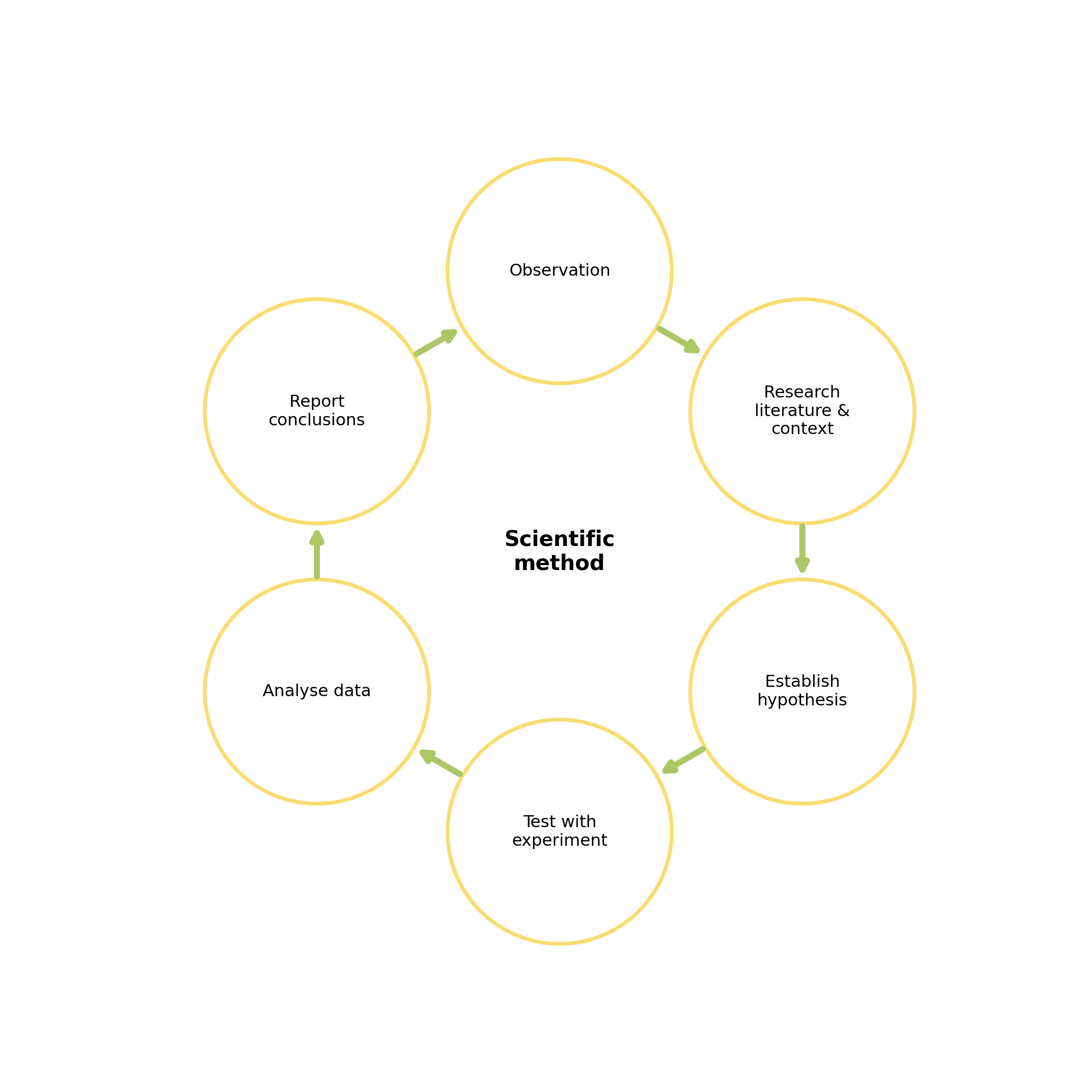
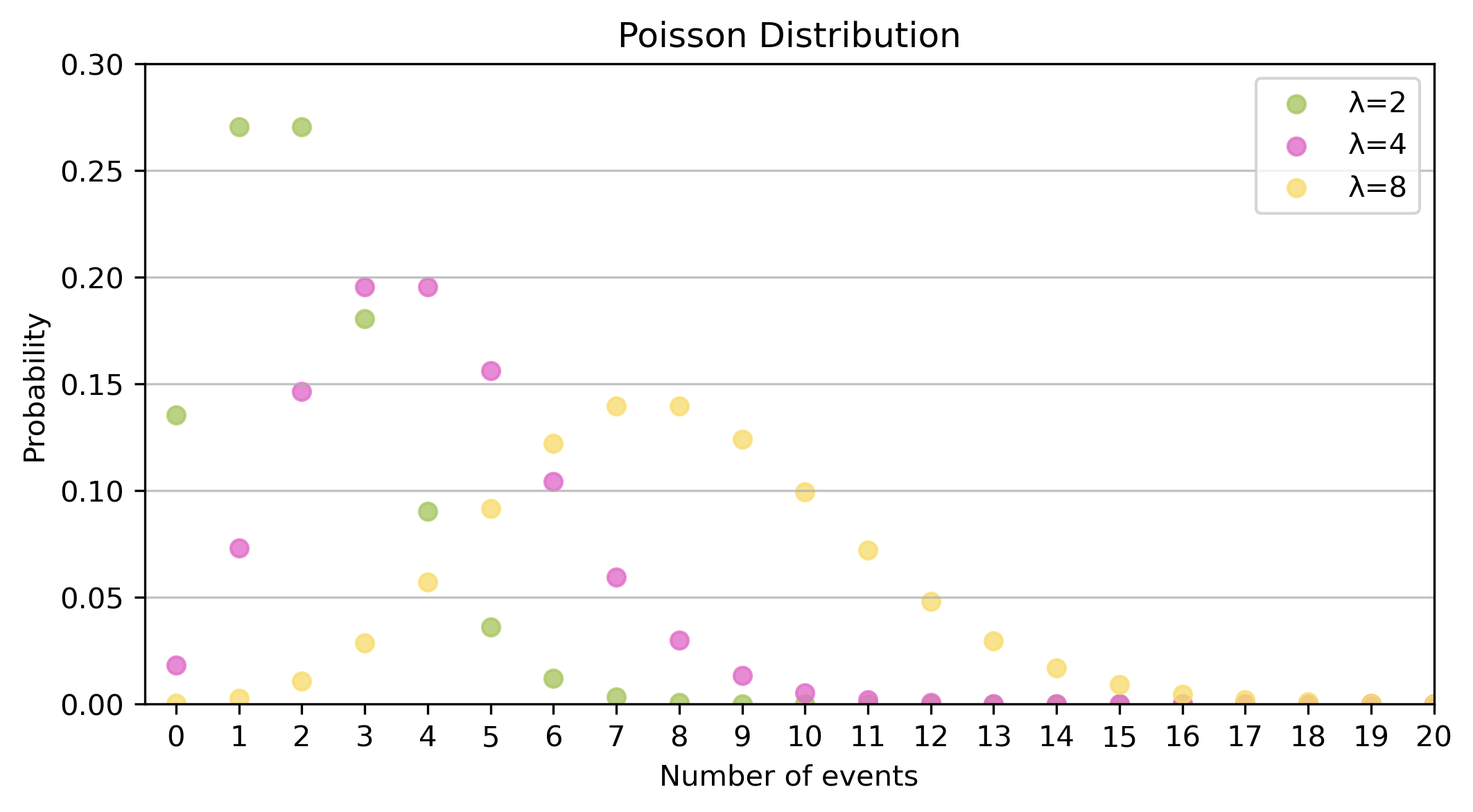When we’re working with large datasets, exploratory data analysis is the first step in the scientific method.
How to understand the dataset
What do the variables represent
What statistical techniques should be used
Introducing statistical concepts
Data science is about using ideas from statistics to describe large datasets
Focus on numerical data
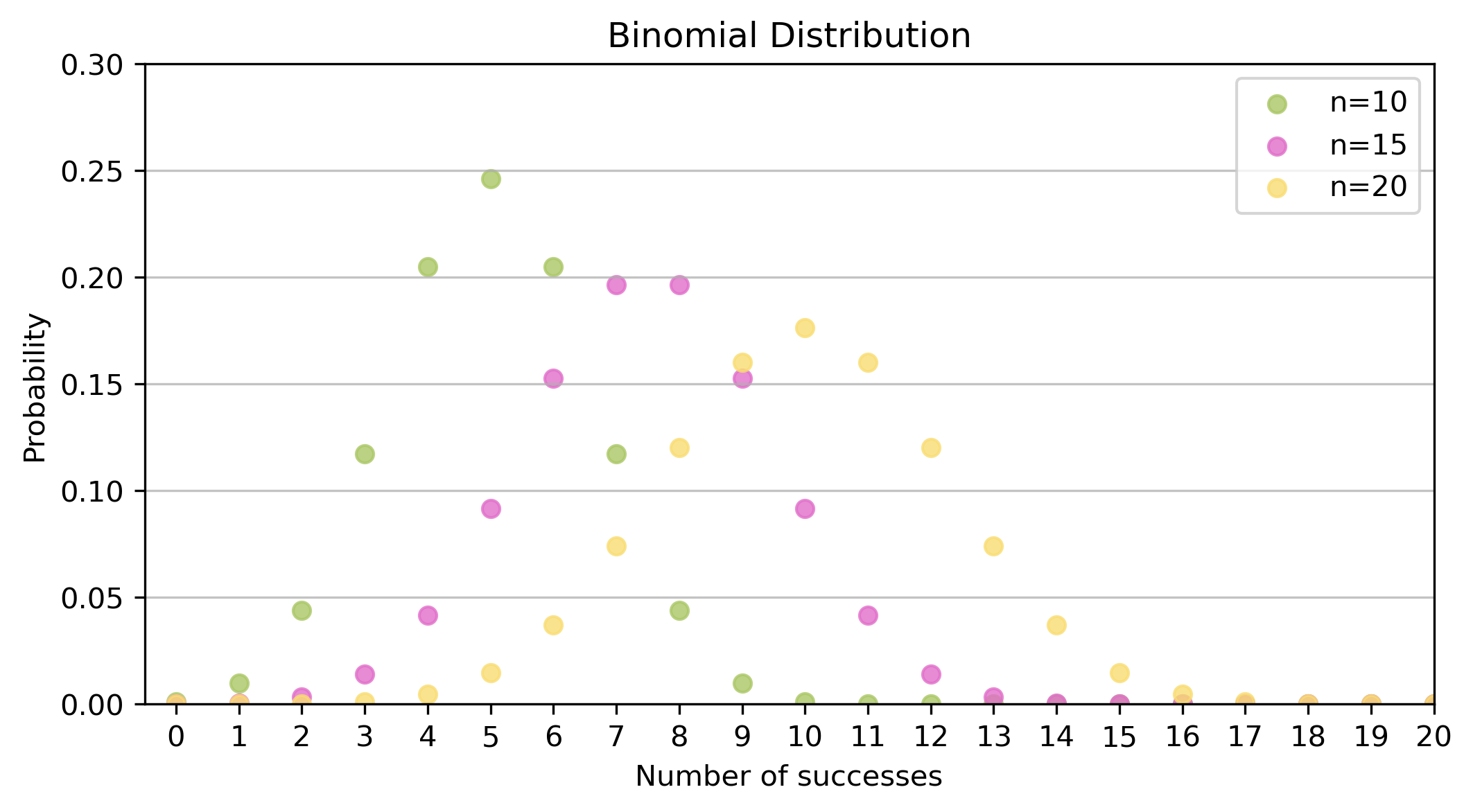
Using probability distributions to characterise them
Learning objectives
By the end of this lecture you should be able to:
Describe the characteristic features of common probability distributions.
Calculate exponentials and logarithms.
Evaluate whether a dataset is representative.
Motivation
How do we understand how likely events are to occur?
Question
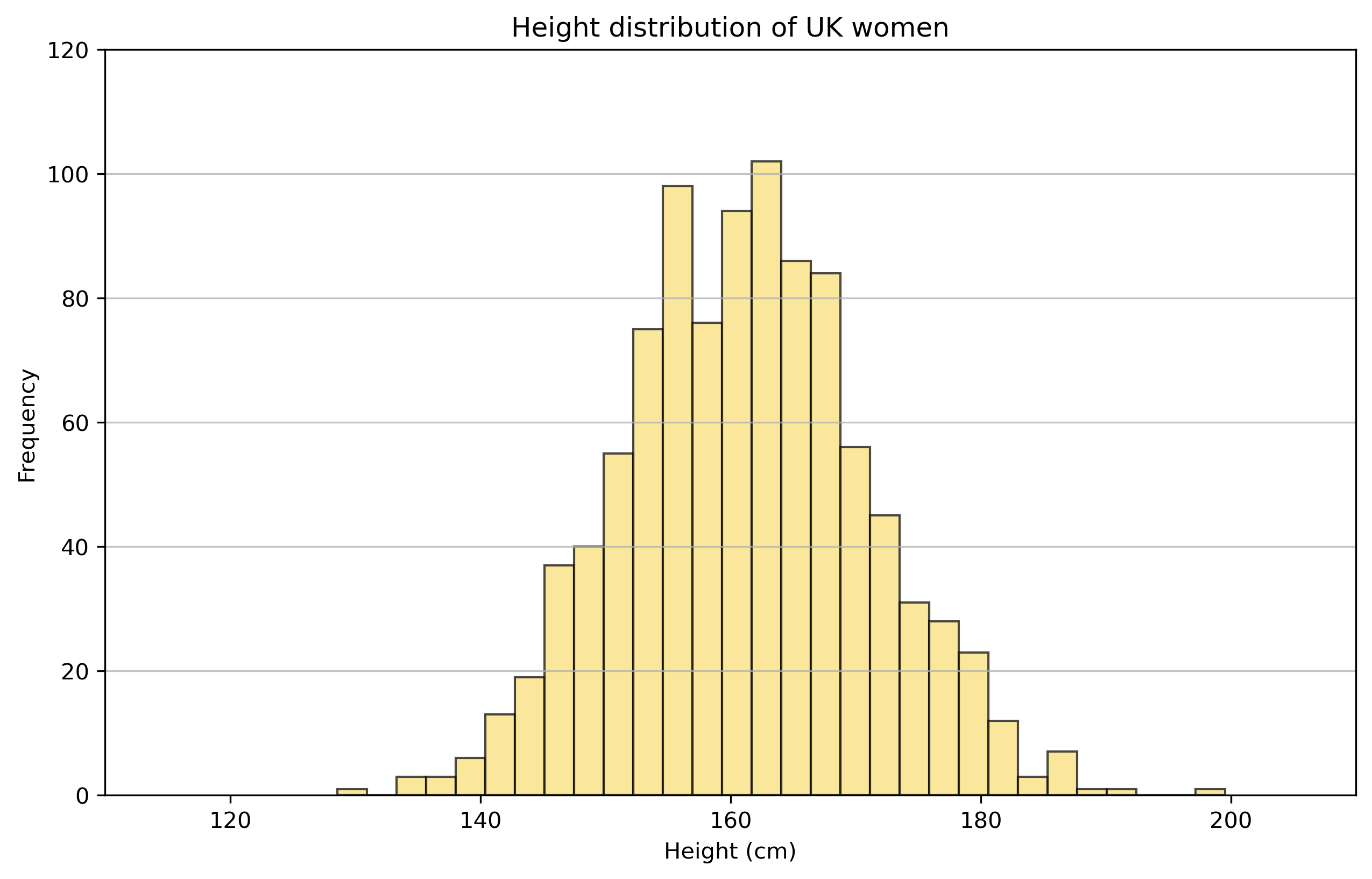
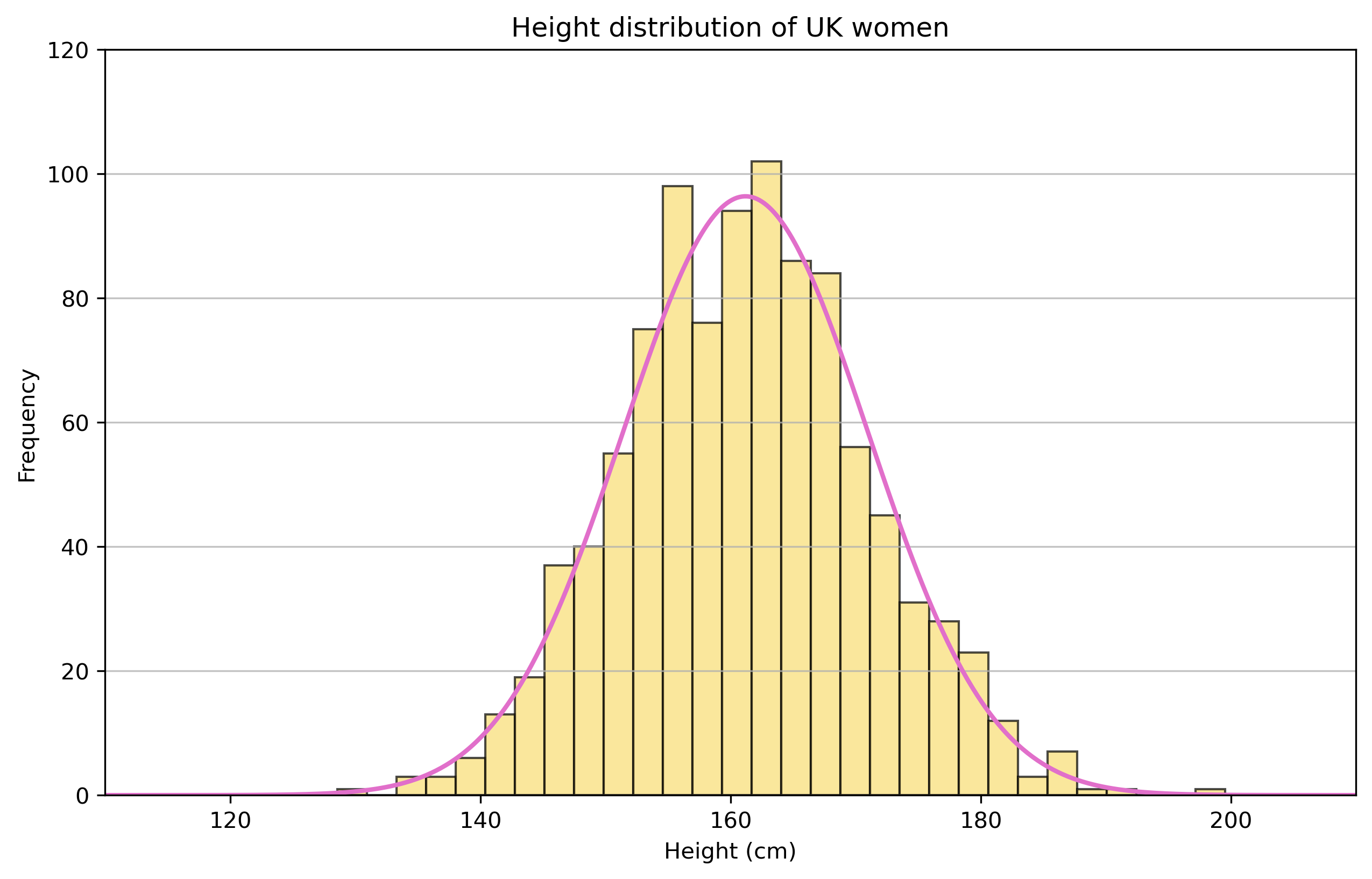
What is the probability of someone at UCL being over 190cm?
How can we try to answer this?
We could try and find someone on campus who is over 190cm.
Better idea is to try and understand the distribution of heights.
Representative data
Before we try to describe the data, it’s important to know where the data came from.
The dream vs reality
Ideally, we would like all the relevant data.
… in reality we normally only have some.
Approximating
Hence, we sample a subset of the data. We need to choose our sample carefully - we want what happens in the sample to approximate what happens in the whole population.
In practise we might try different sampling approaches such as:
random sampling
systematic sampling
Bias
It’s important to understand if your dataset is unrepresentative or biased.
Cognitive bias
Systematic patterns in how we think about, and perceive, the world.
Our cognitive biases can impact:
data collection
data selection
data processing
modelling choices
Why is this important?
If we’re not careful we can propagate bias to the research, and hence results.
This can lead to incorrect conclusions.
Dataset bias
Particularly important when thinking about analysing large datasets as there could be non-obvious patterns reflecting biases.
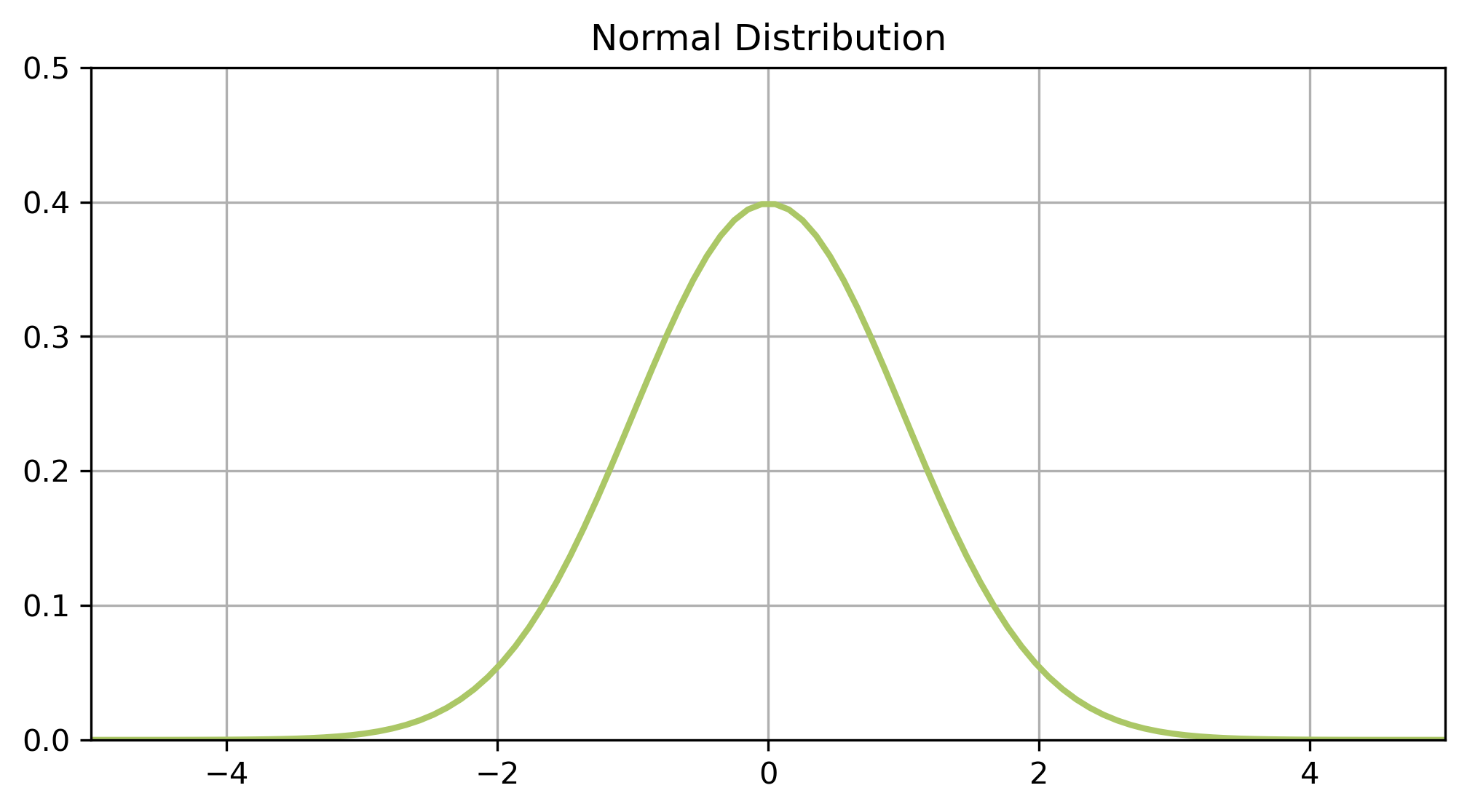
it is something you measure not something you count
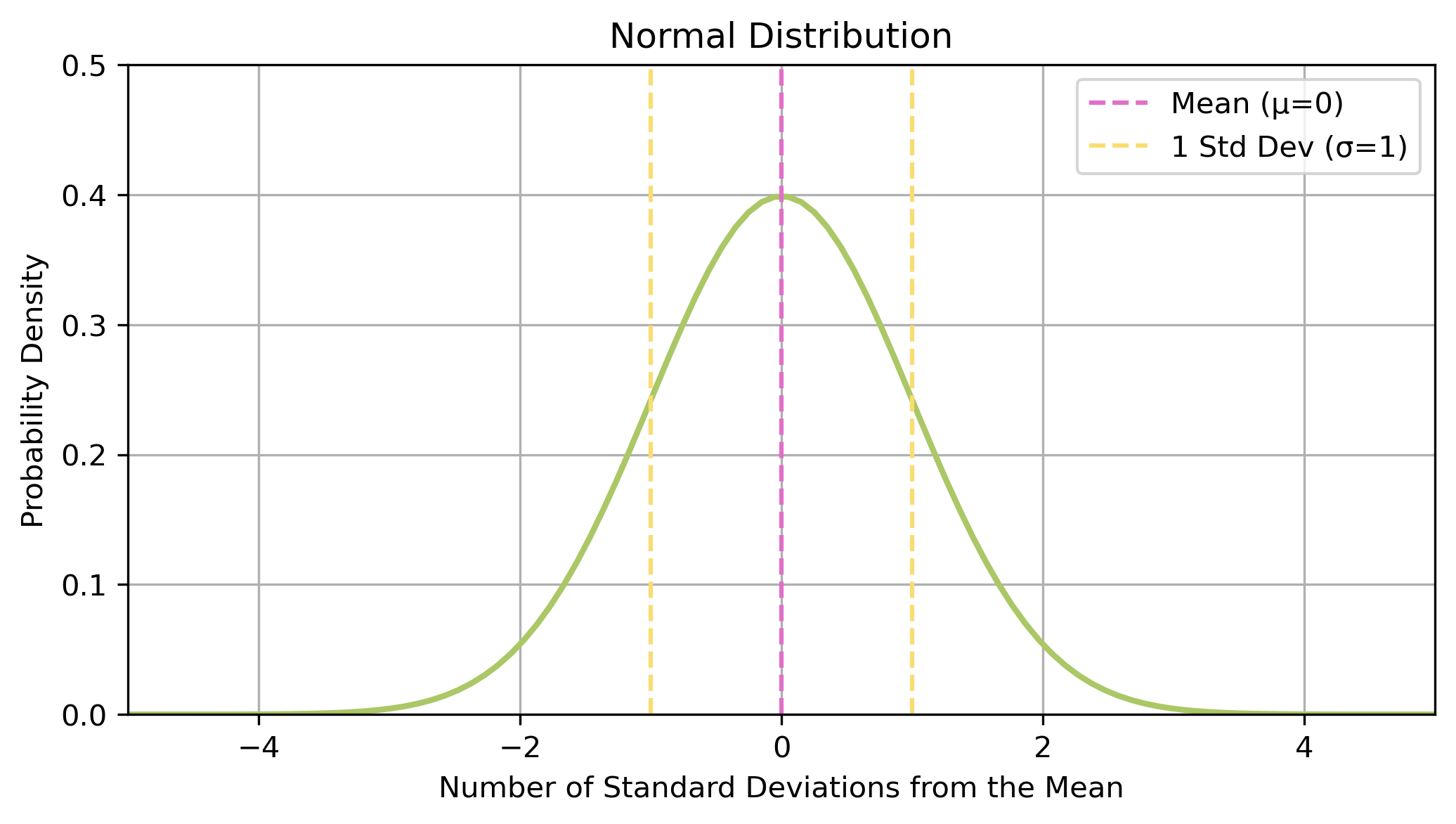
Data is equally likely to be larger or smaller than average
symmetric
Characteristic size, all data points are close to the mean
single peak
There is less data further away from the mean
smooth tails on both sides
Uniquely described by two variables…
…and a probability distribution function
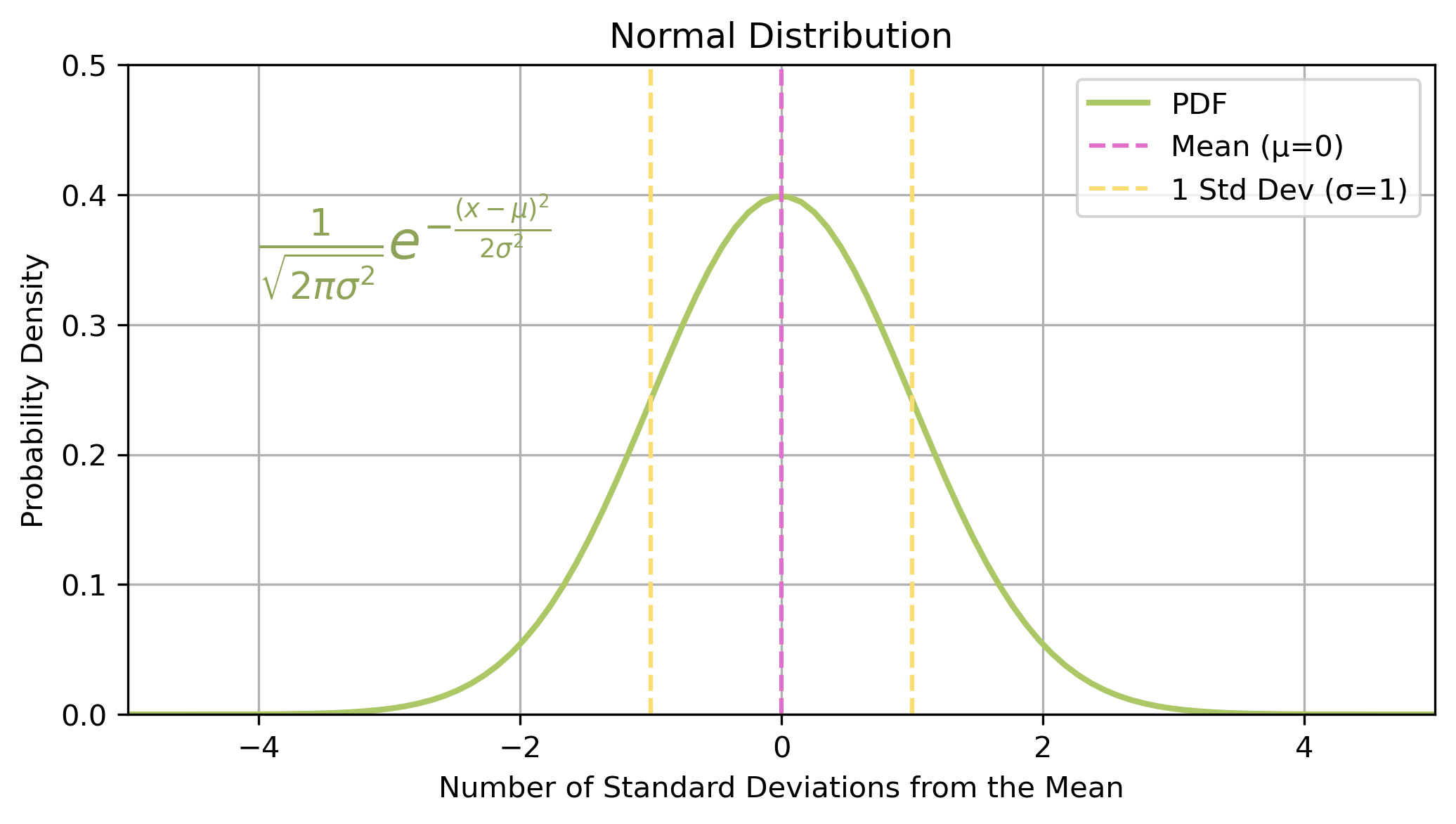
The probability density function (PDF) describes the likelihood of different outcomes for a continuous random variable
The distribution of the random variable
A random variable is a way to map the outcome of a random process to a probability.
In mathematical notation, a random variable \(X\) is approximately normally distributed about a mean of \(\mu\) with a standard deviation of \(\sigma\):
\[\begin{align}
X \sim N(\mu,\sigma)
\end{align}\]
Sampling distributions
The distribution of the random variable when derived from a random sample of size \(n\)
In the case of the normal distribution the standard deviation becomes:
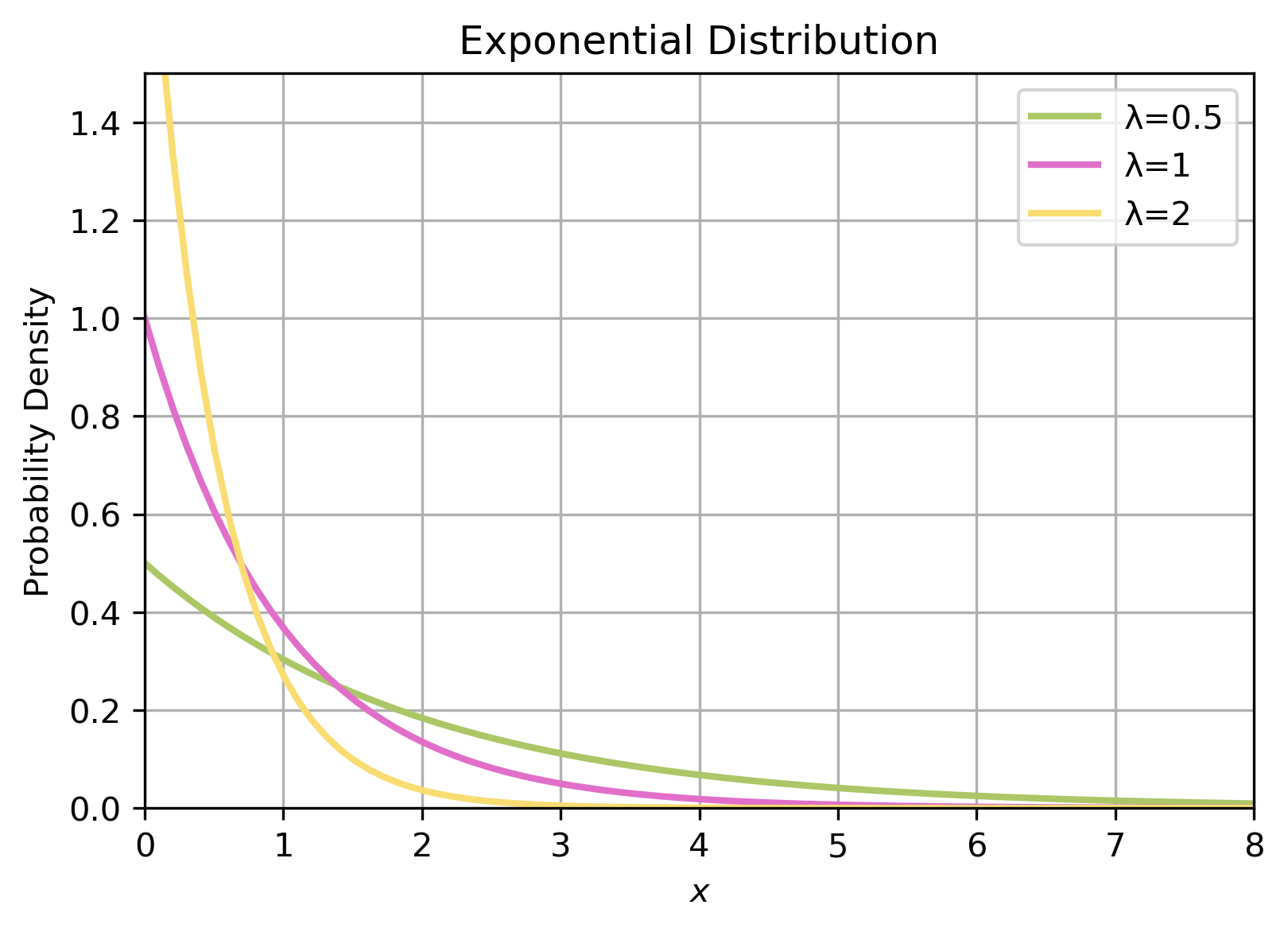
If the Poisson measures the probability of \(x\) events within a time period, then the exponential measures how long we are likely to wait between events.
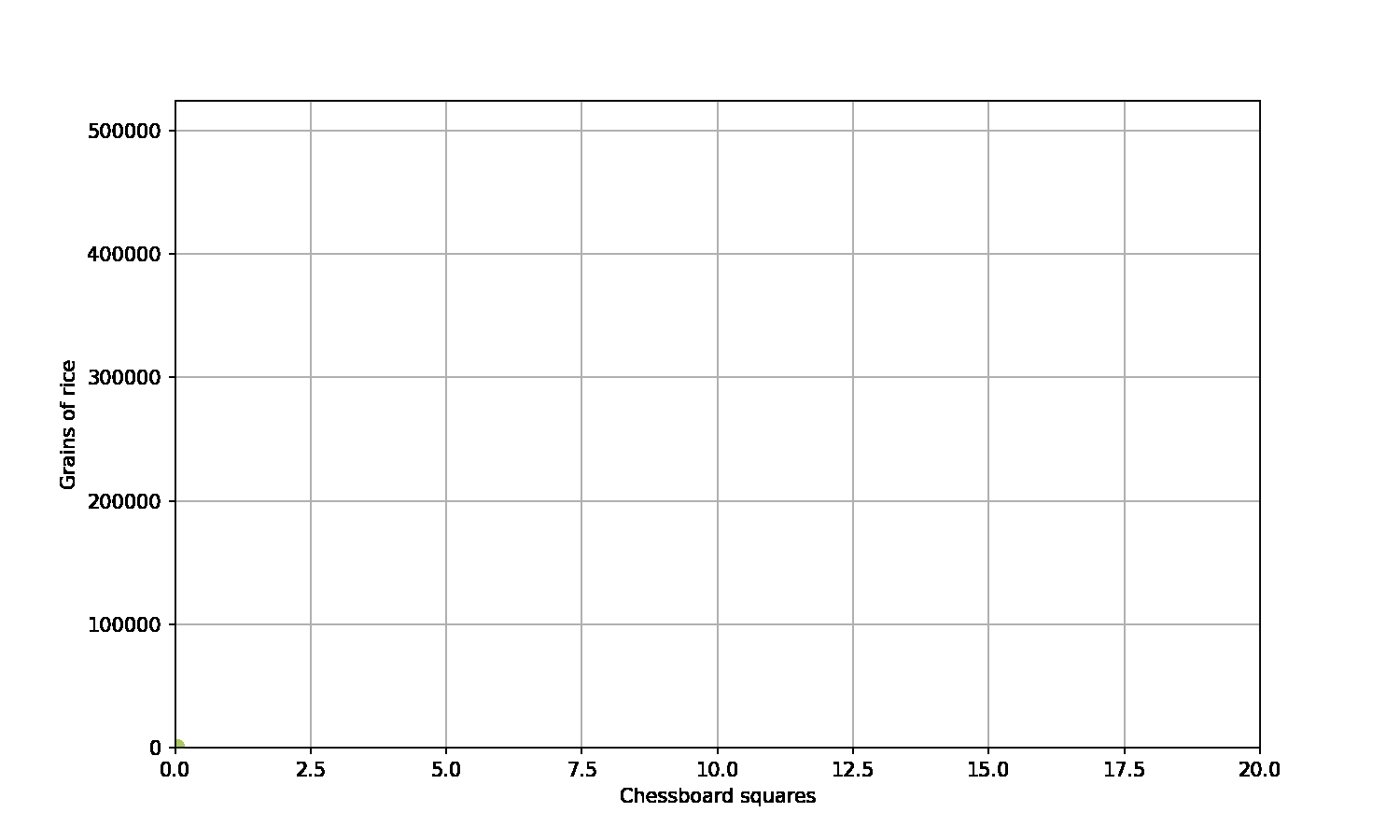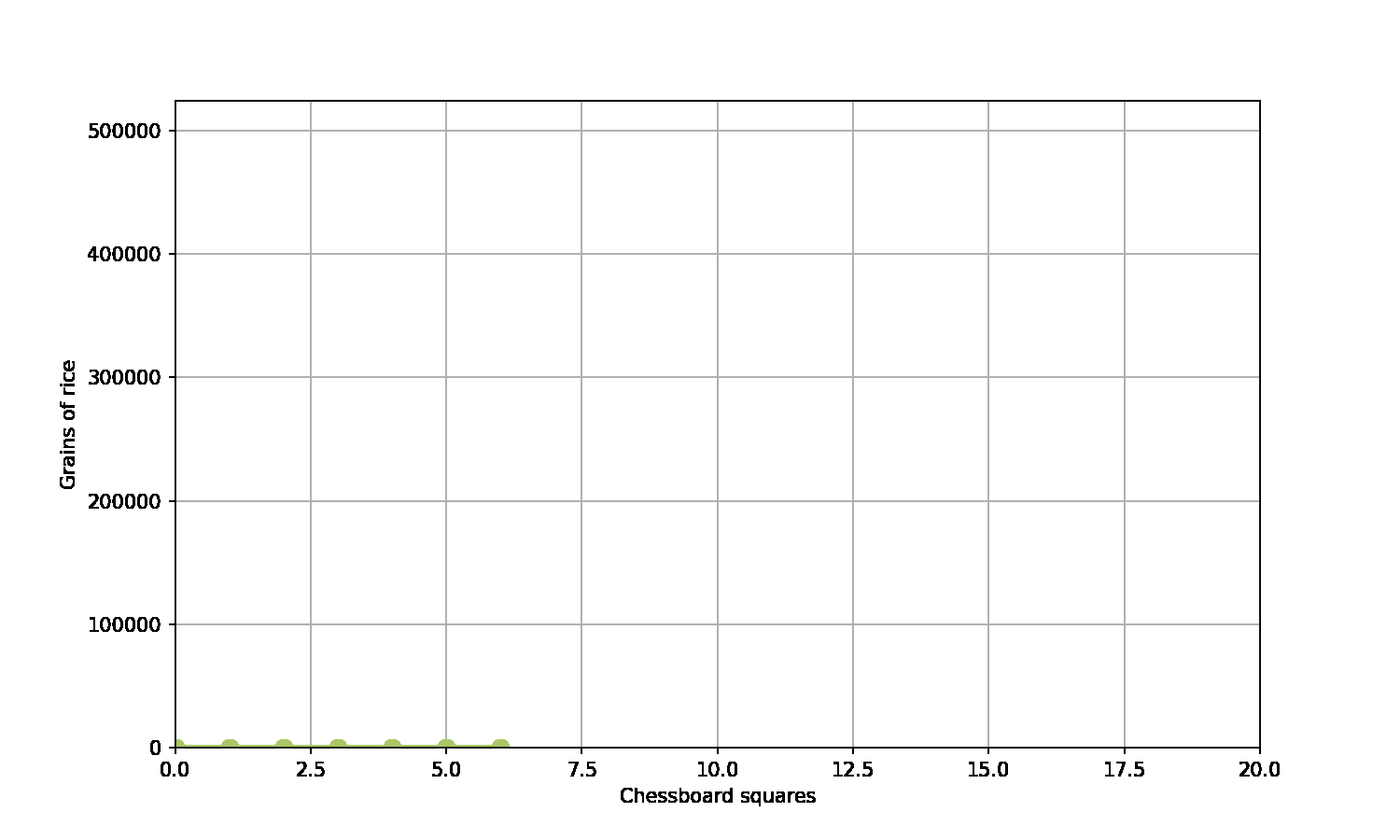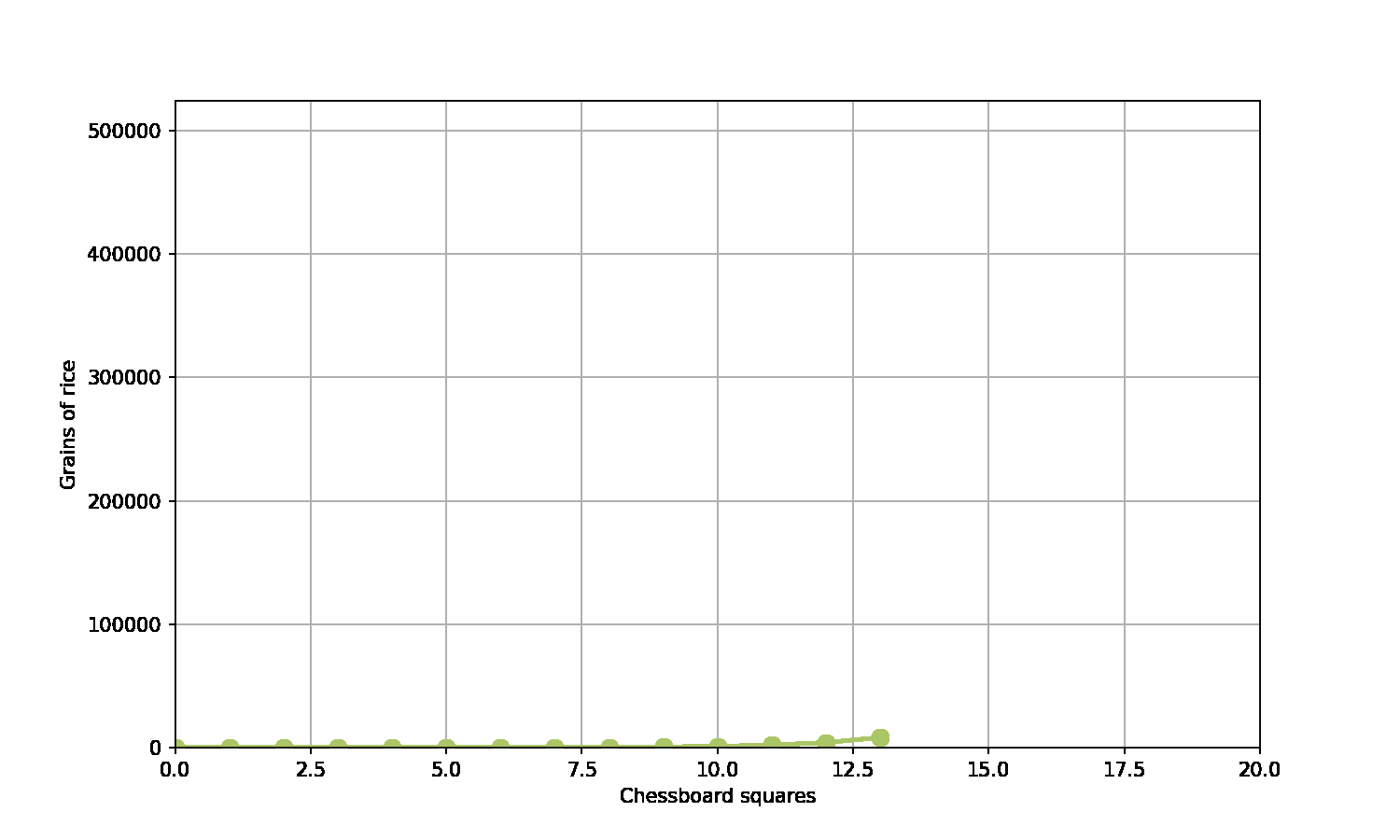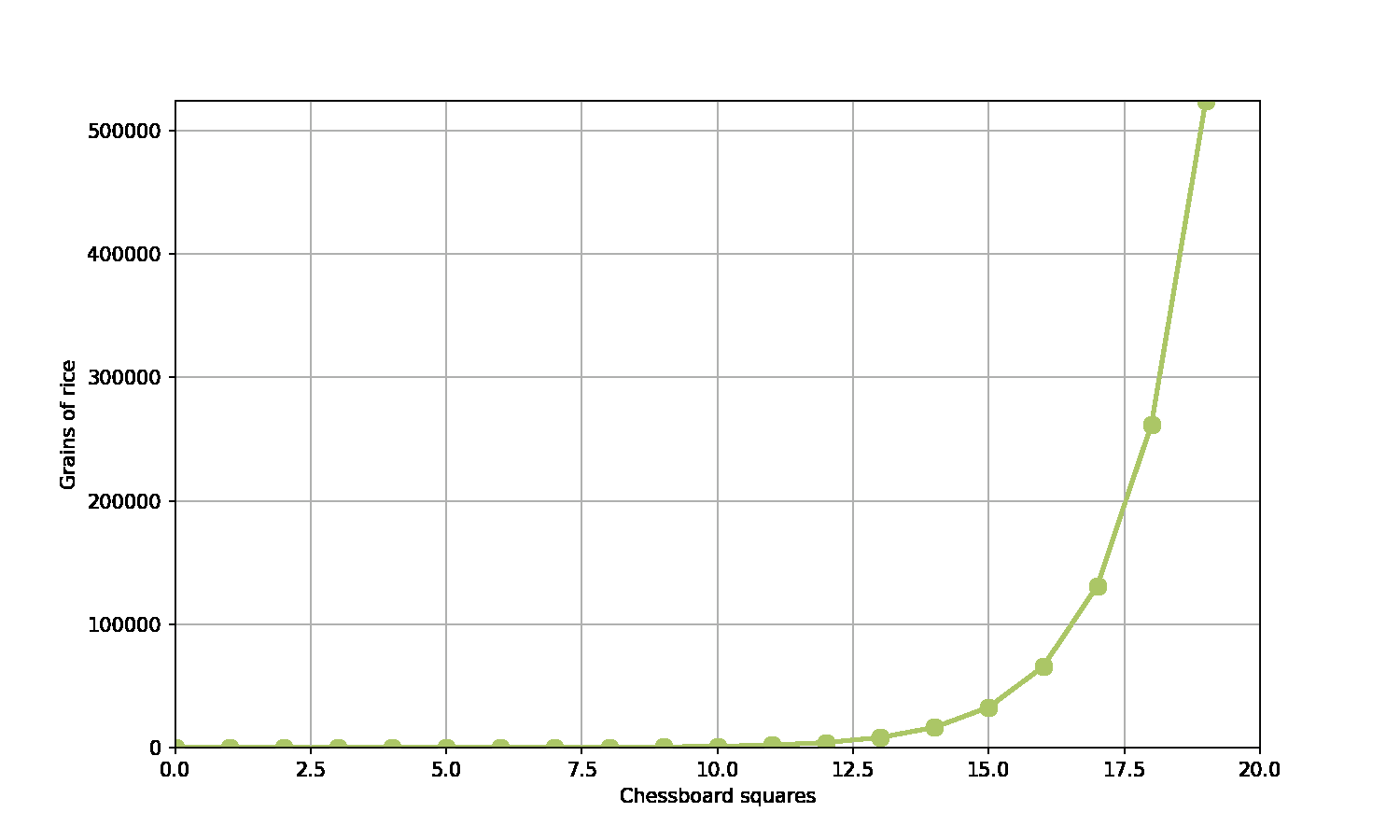
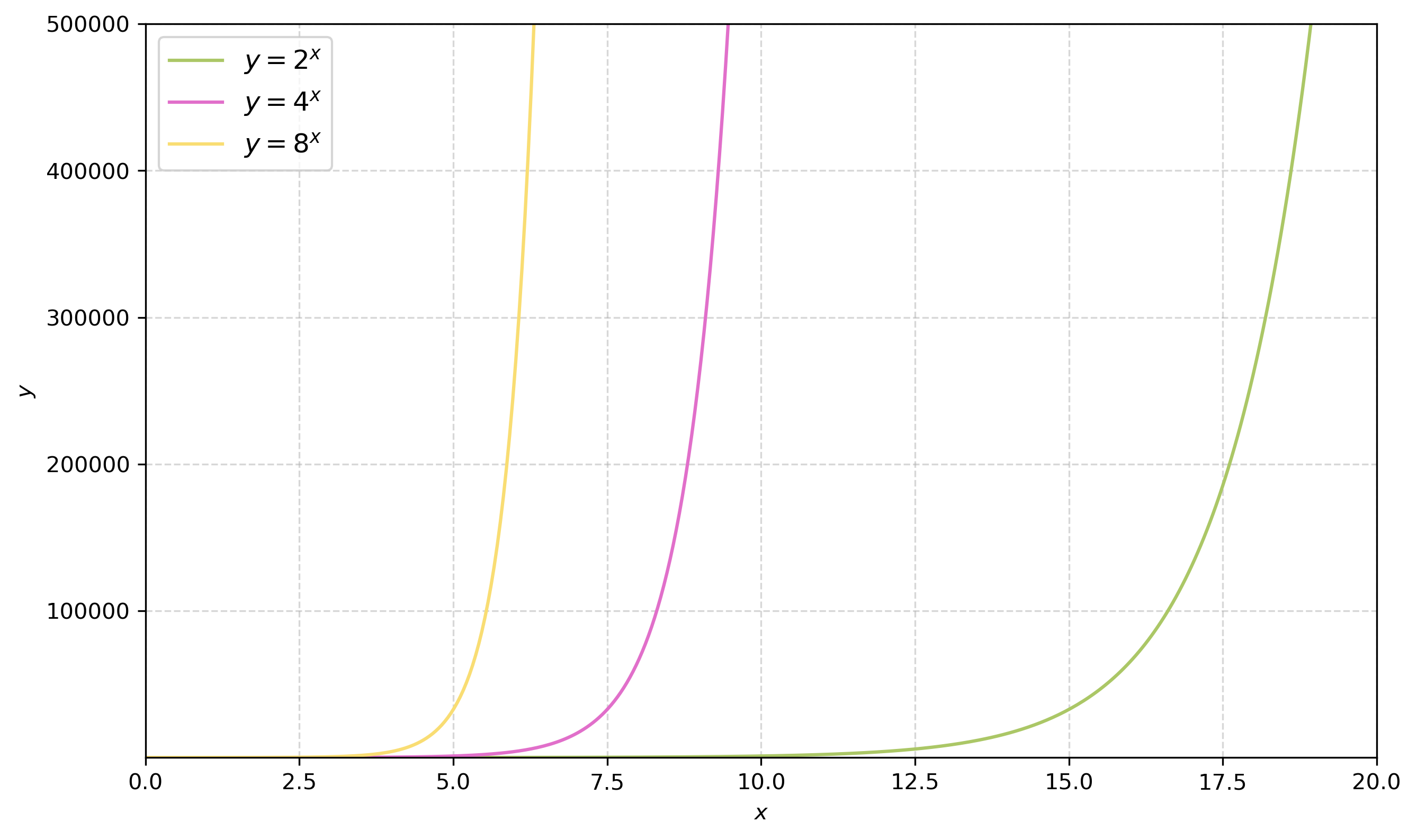
The greatest shortcoming of the human race is our inability to understand the exponential function – Albert Bartlett (physicist)
A game of chess…
A scholar has invented chess
The emperor is really grateful - and asks what gift the scholar would like in thanks
The scholar asks for grains of rice
Specifically, rice to fill the chessboard, such that the number of grains double on each square