Model Interpretation
- huanfa.chen@ucl.ac.uk
13/12/2025
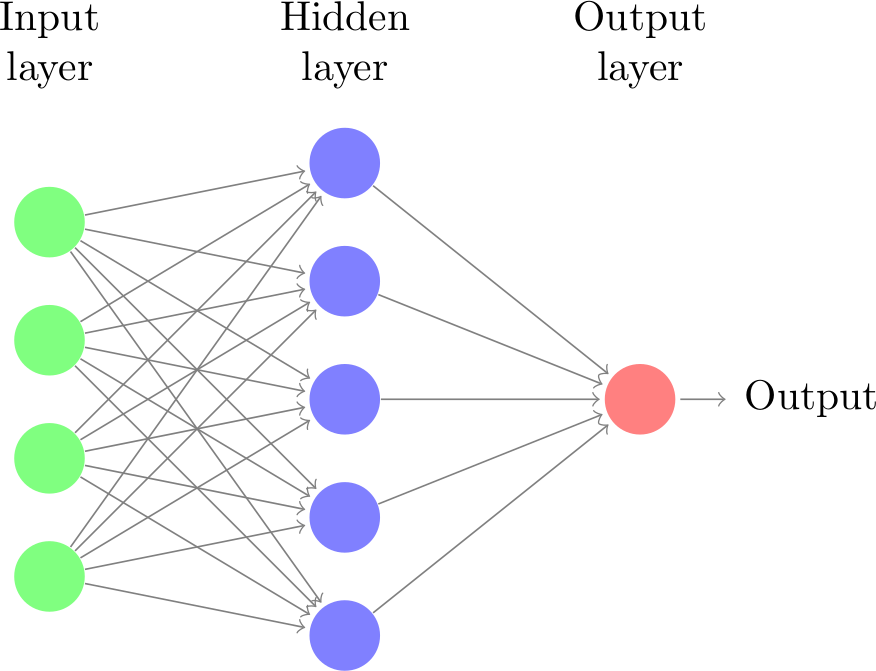
Recap: Neural Networks (or MLP)
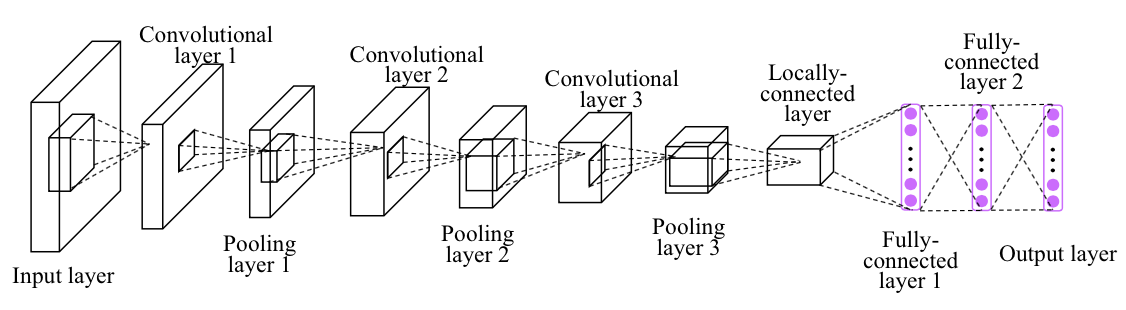
Recap: Convolutional Neural Networks (CNN)
- Local filter
- Translation invariance
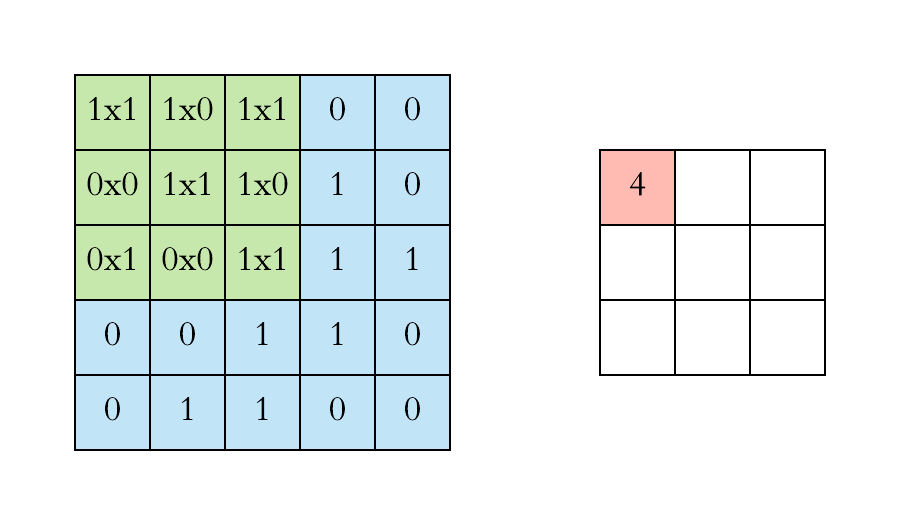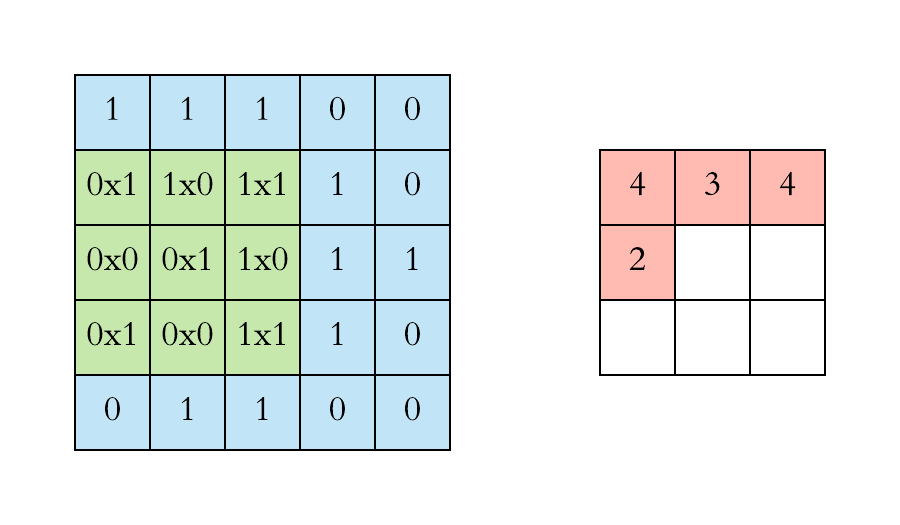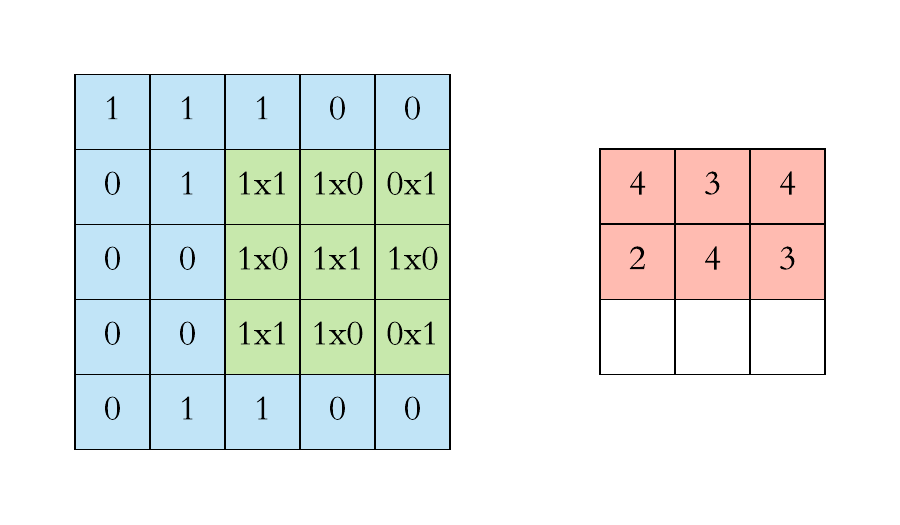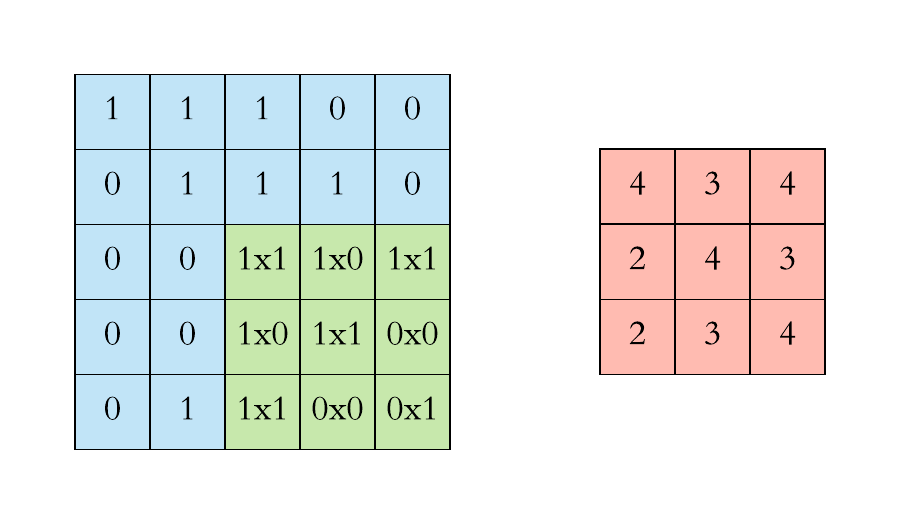
Recap: Graph Neural Networks (GNN)
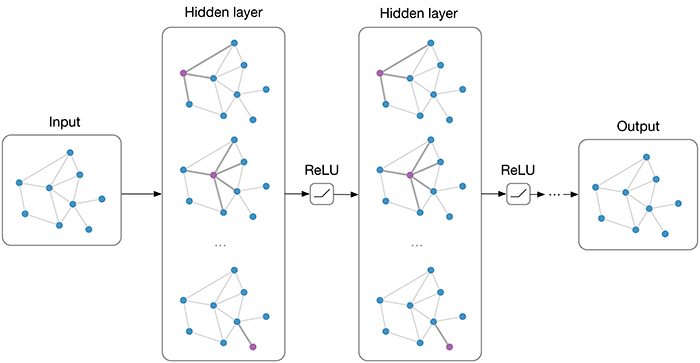
Permutation Importance
Idea: measure marginal influence of a feature by permuting it and measuring the drop in accuracy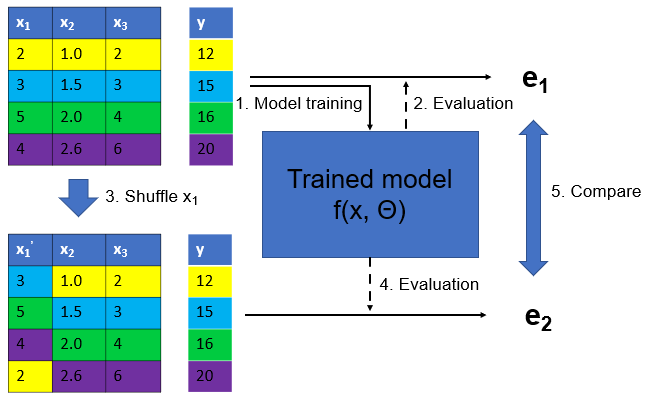
PDP
from sklearn.inspection import plot_partial_dependence
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target,random_state=0)
gbrt = GradientBoostingRegressor().fit(X_train, y_train)
fig, axs = plot_partial_dependence(gbrt, X_train, np.argsort(gbrt.feature_importances_)[-6:], feature_names=boston.feature_names)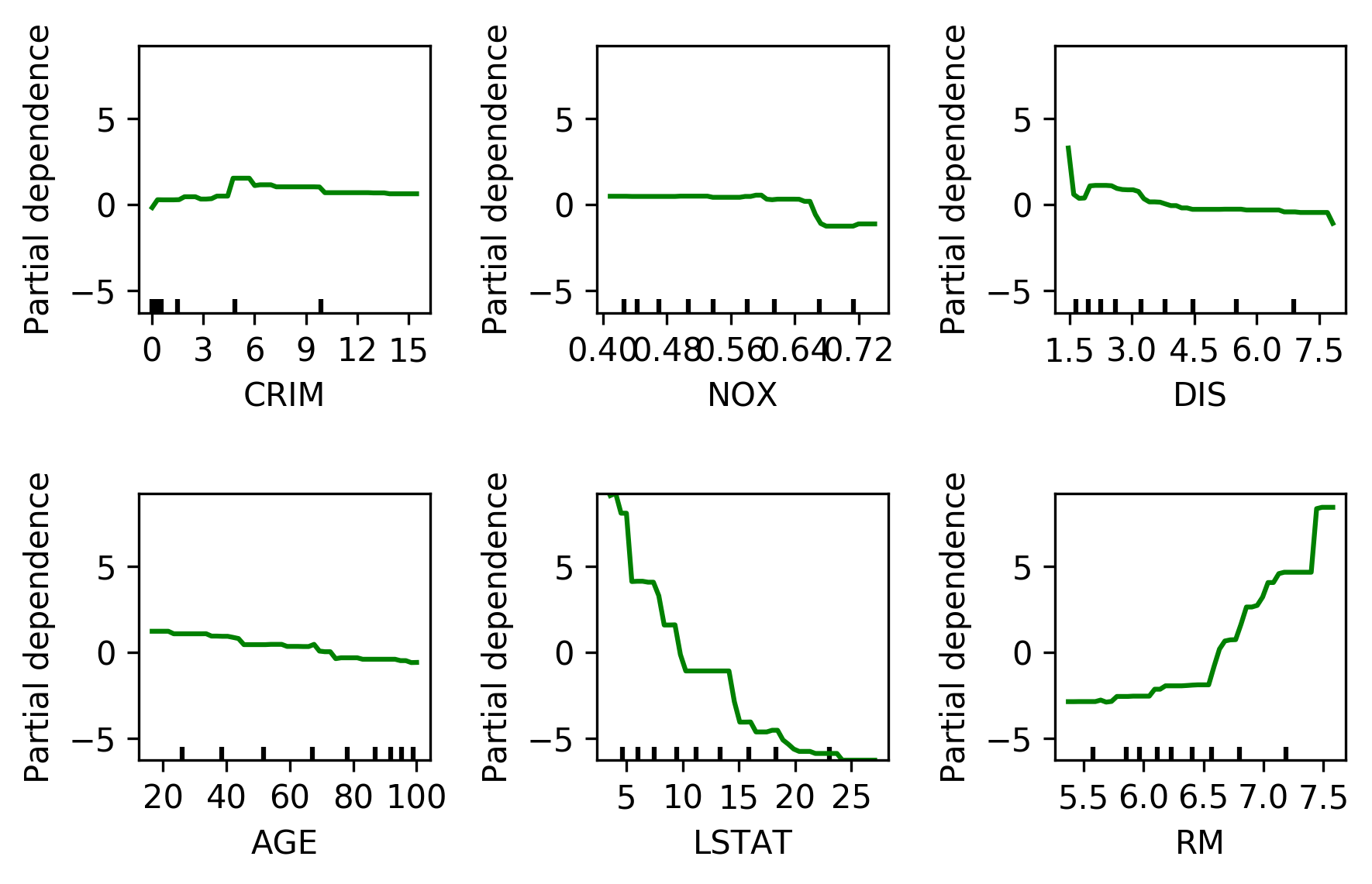
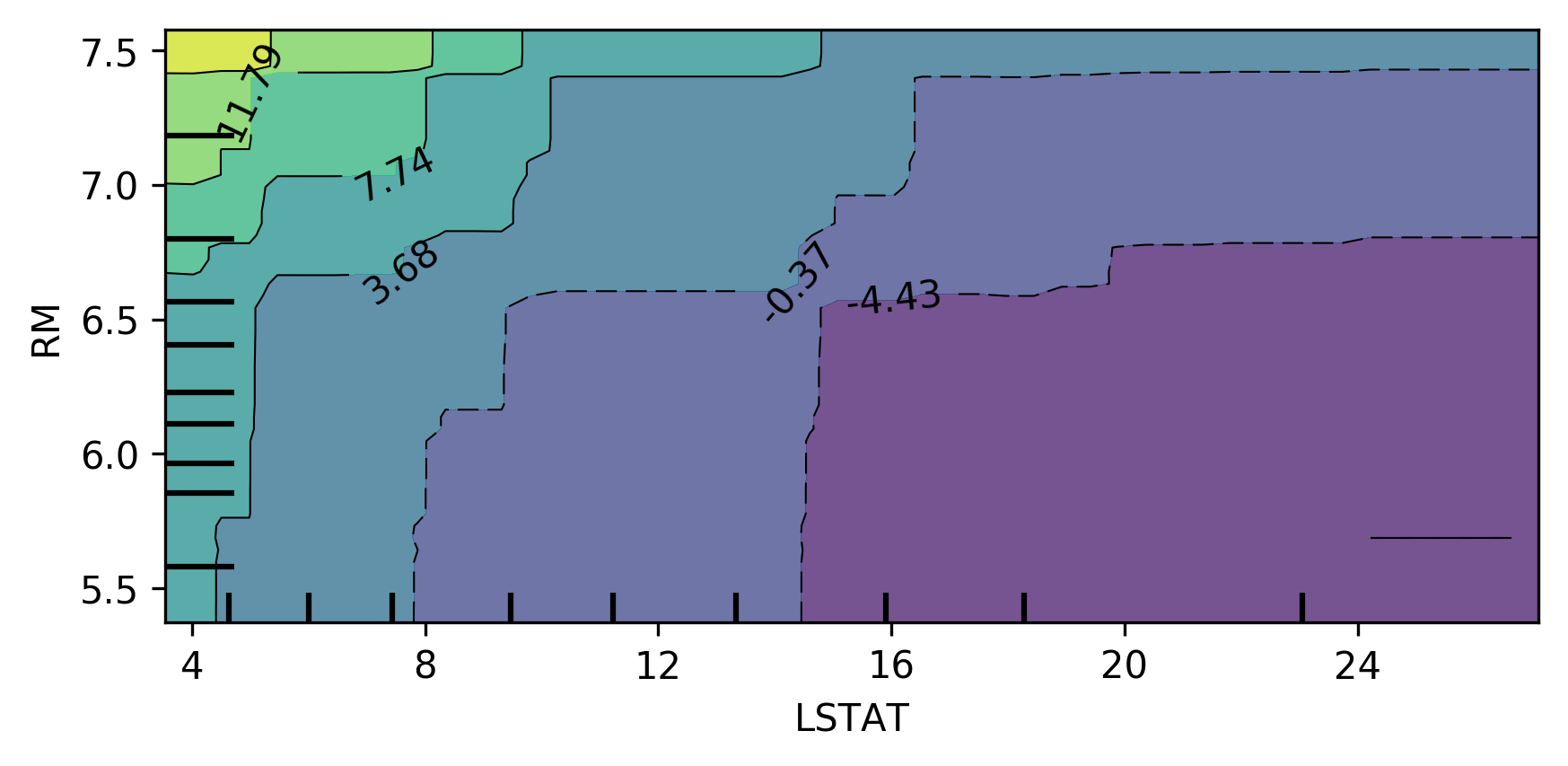
Bivariate Partial Dependence Plots
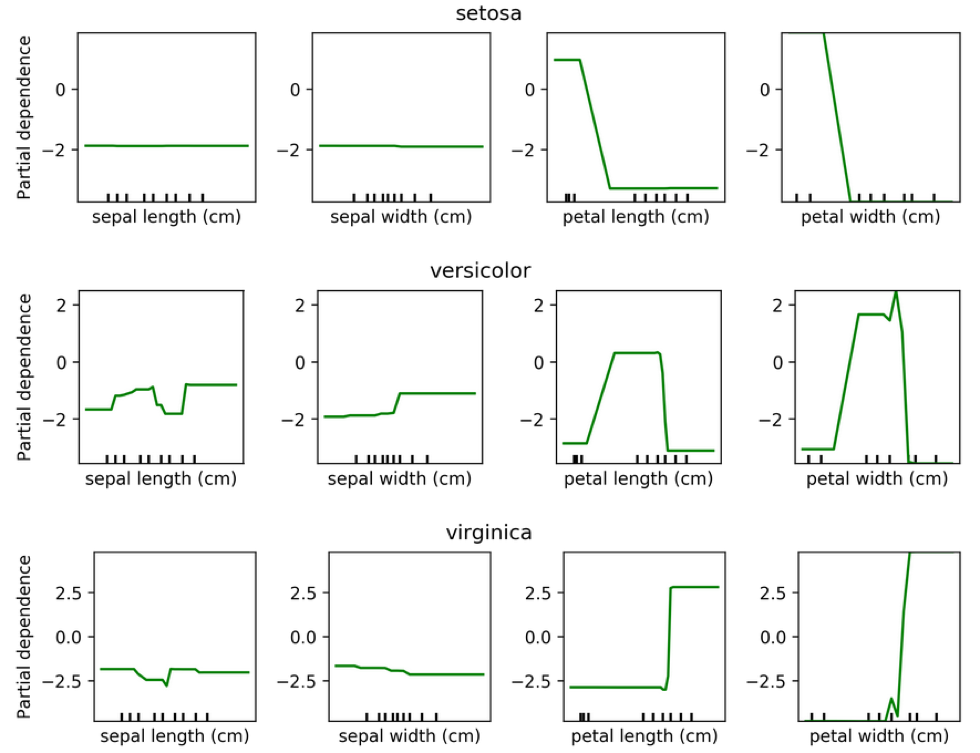
Partial Dependence for Classification
LIME
- Build sparse linear local model around each data point
- Explain prediction for each point locally
- Paper: “Why Should I Trust You?” Explaining the Predictions of Any Classifier
- Implementation: ELI5, https://github.com/marcotcr/lime
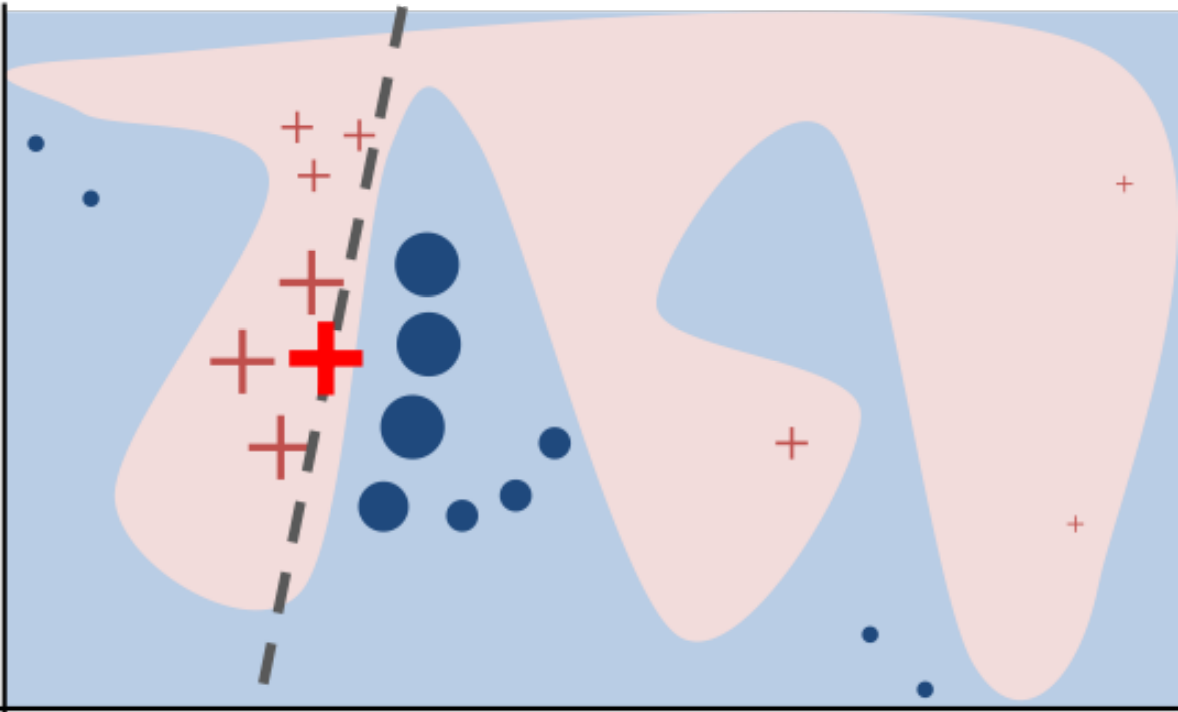
Shapley value
- A fair way to distribute “payout” among N players in a game
- Example in housing price: how much does each factor contribute to the house price?
- What we want to see: park-nearby contributed €30,000; area-50 contributed €10,000; floor-2nd contributed €0; cat-ban contributed -€50,000. But HOW?
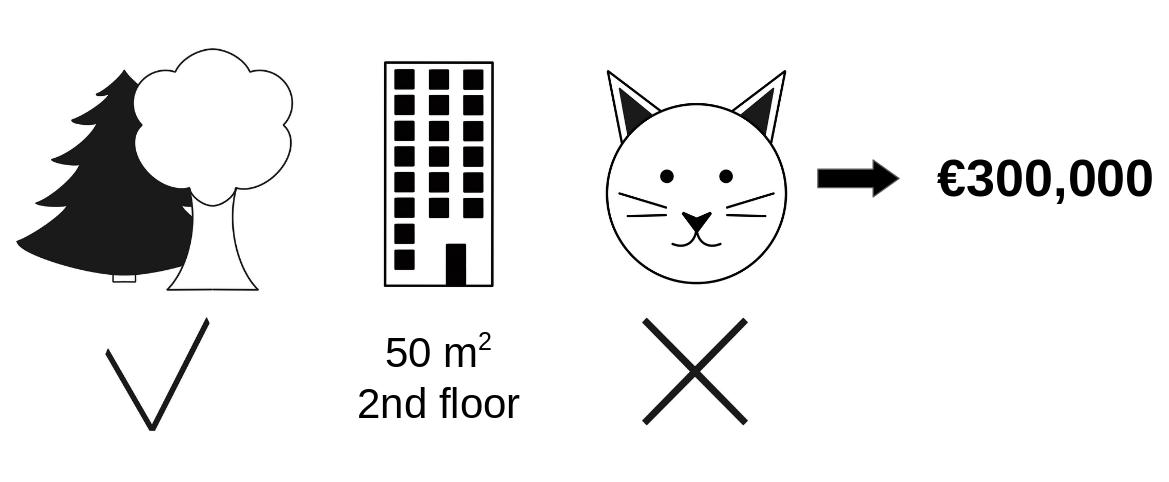
Shapley value (cont.)
- Checking all possible coalition …
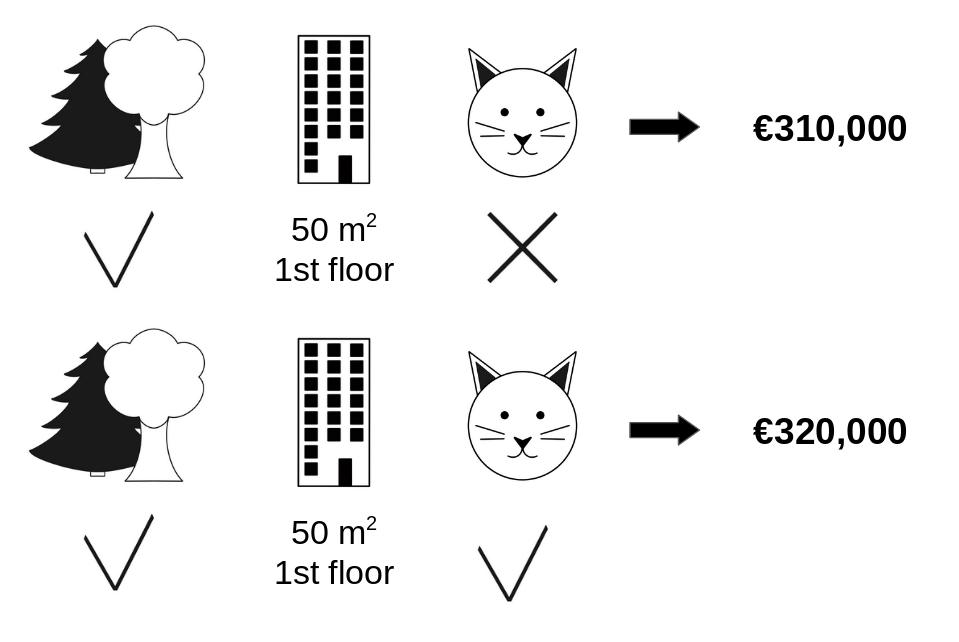
Shapley value
- Example of Shapley value for bike rental prediction
- The sum of Shapley values yields the difference of actual and average prediction (422).
- The temperature & humidity had the largest positive contributions.
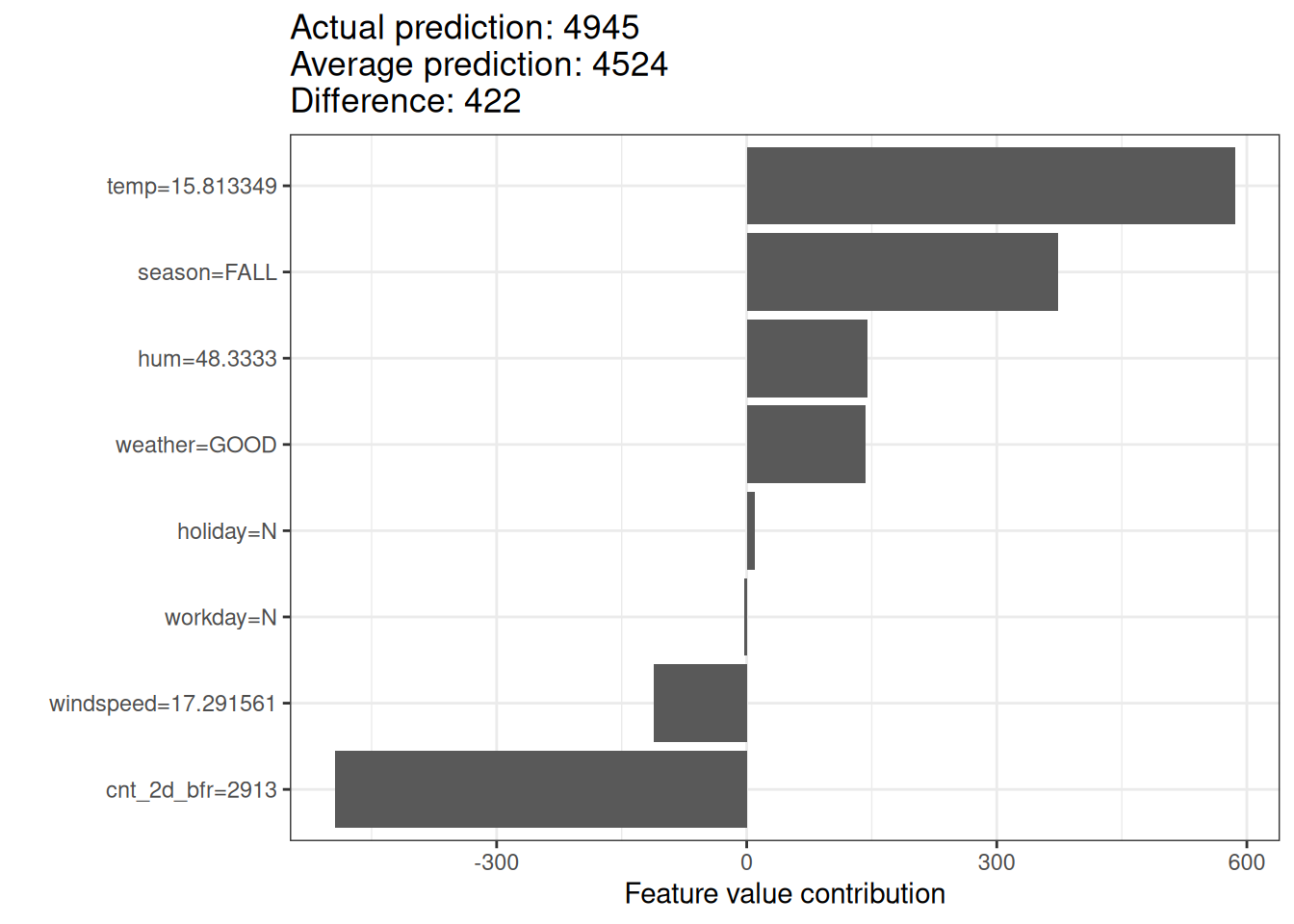
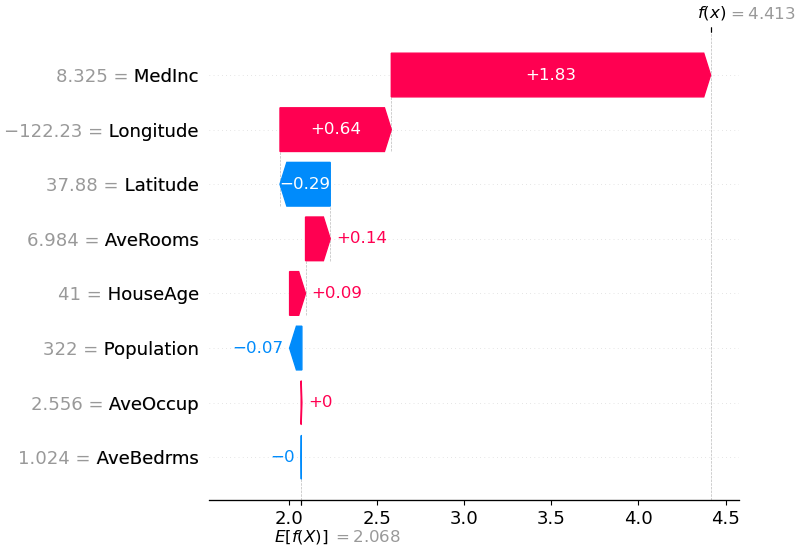
SHAP waterfall plot
SHAP force plots

SHAP force plots for multiple samples
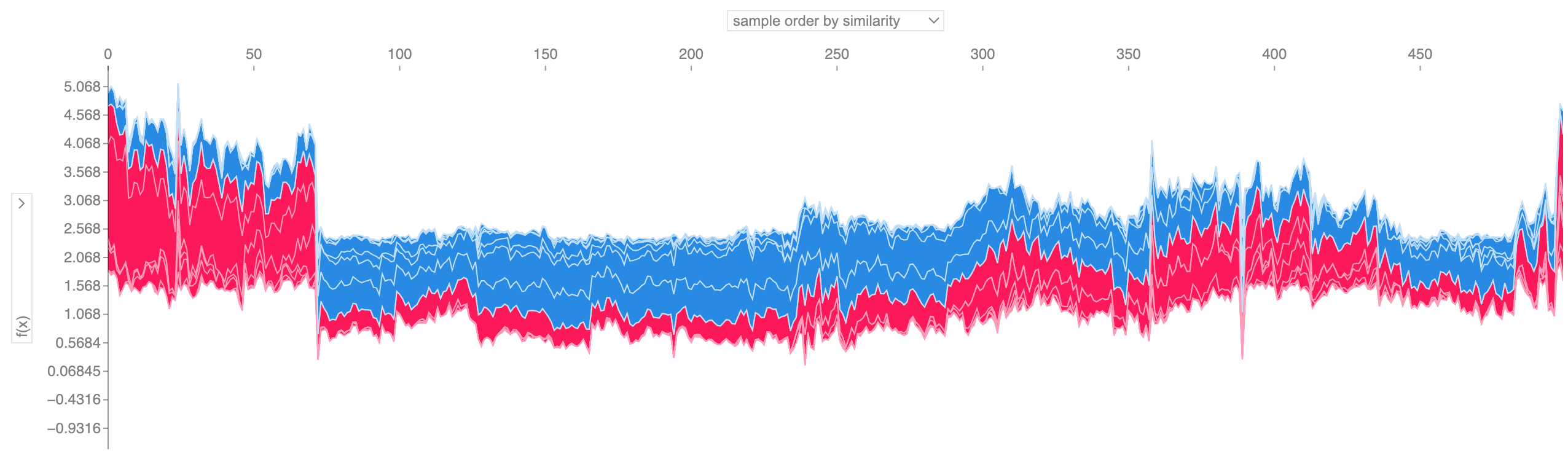
- Use with caution!
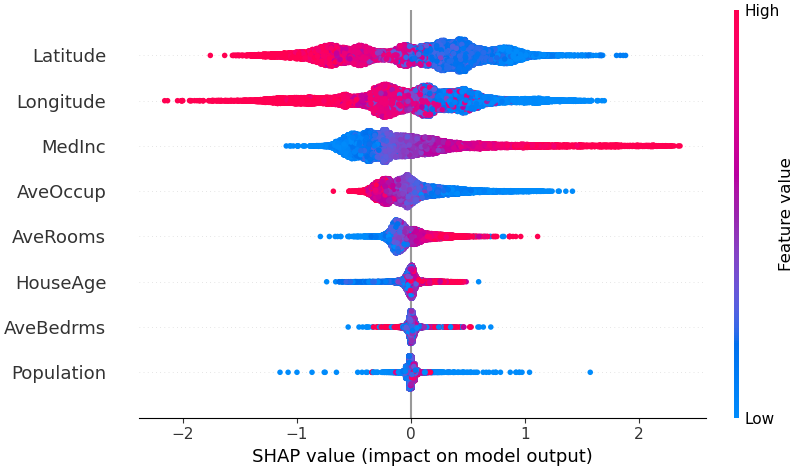
SHAP Summary Plot
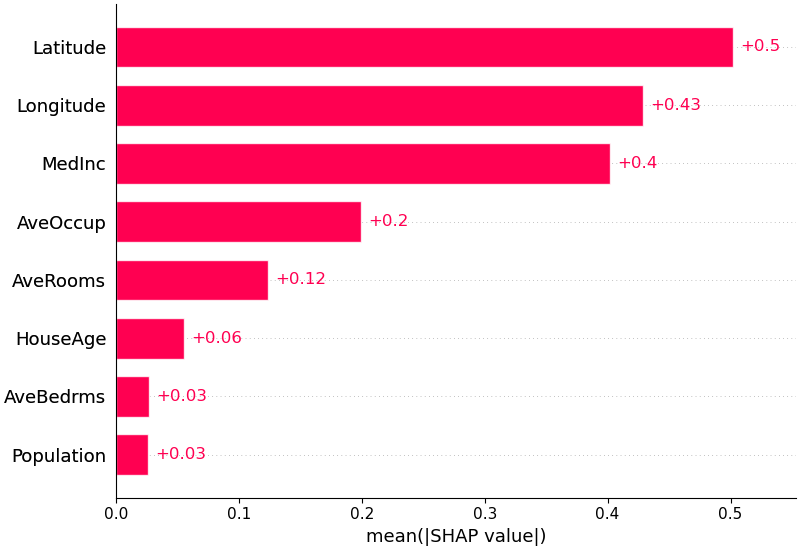
SHAP Feature Importance
- Defined as the mean absolute values of SHAP across all samples
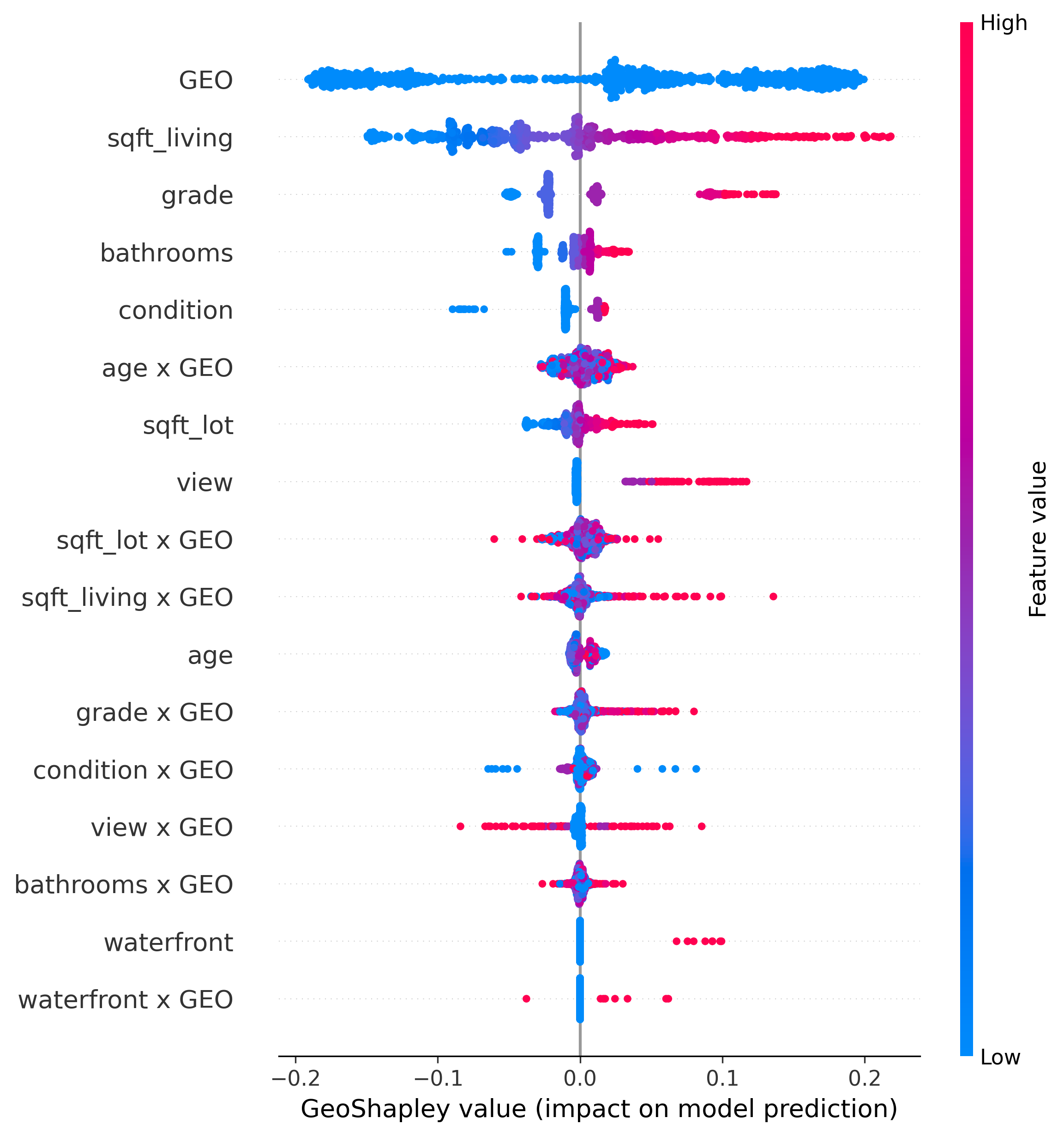
GeoShapley
- Explains any model that takes tabular data + spatial features (e.g., coordinates)
- Source: https://github.com/Ziqi-Li/geoshapley