Graph Neural Networks
Extending neural networks to graph-structured data
- huanfa.chen@ucl.ac.uk
13/12/2025
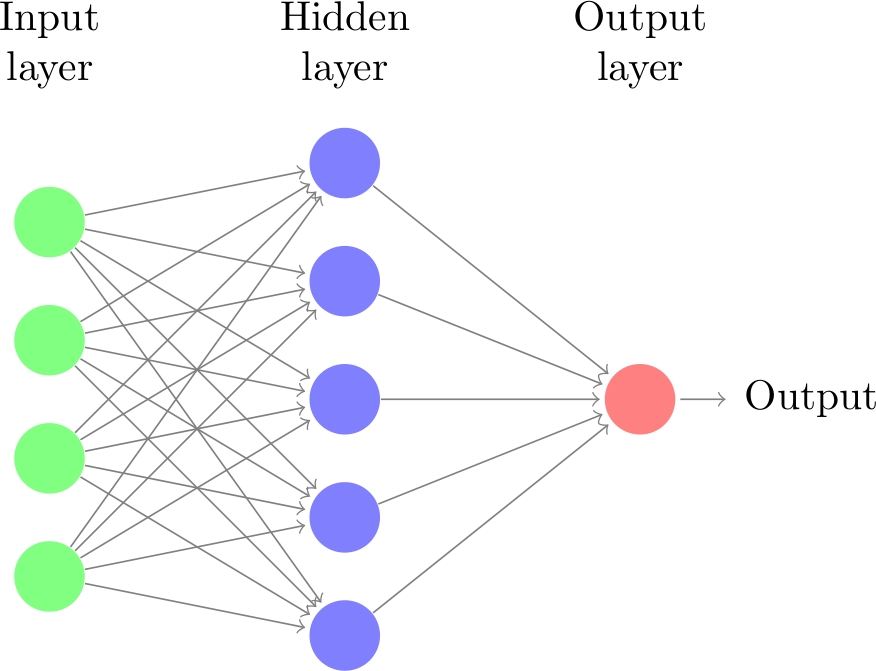
Recap: Neural Networks (or MLP)
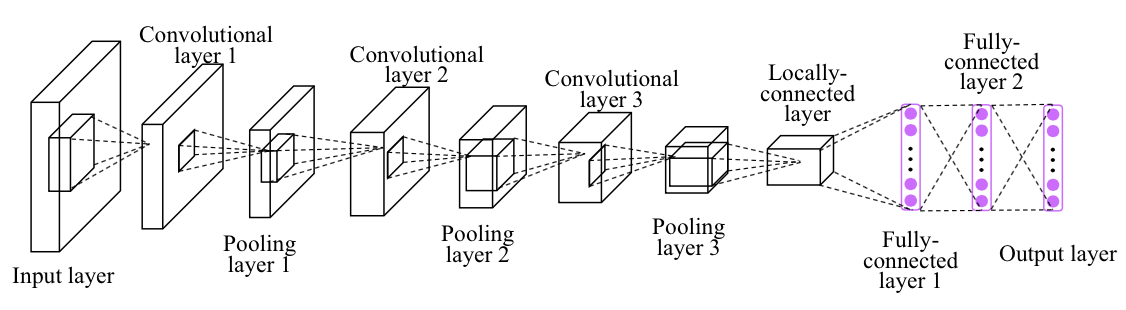
Recap: Convolutional Neural Networks (CNN)
- Local filter
- Translation invariance
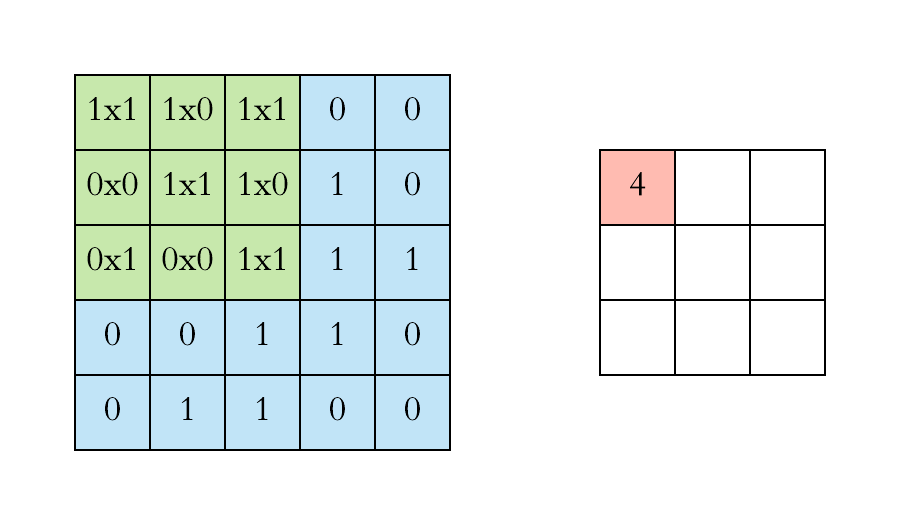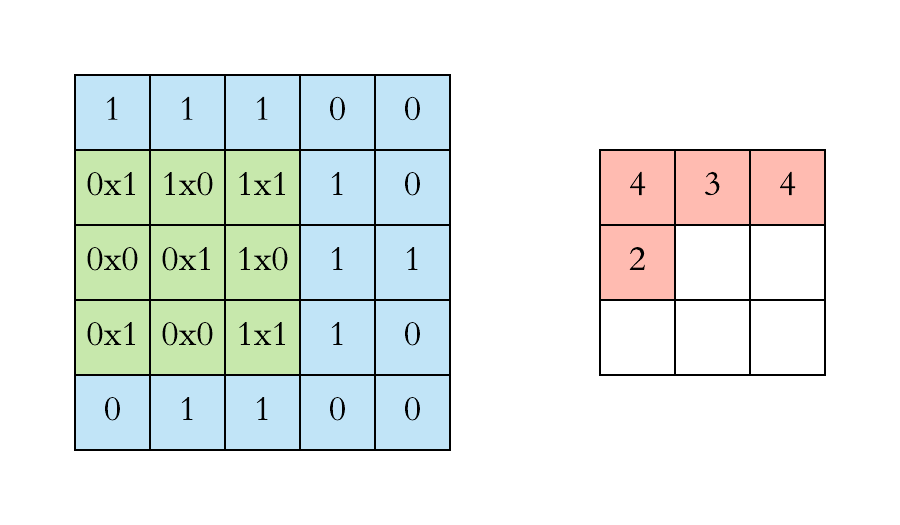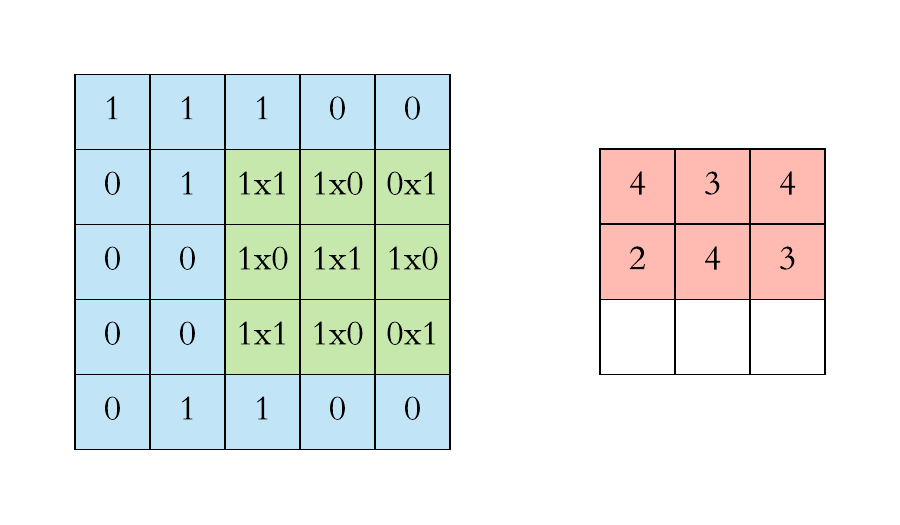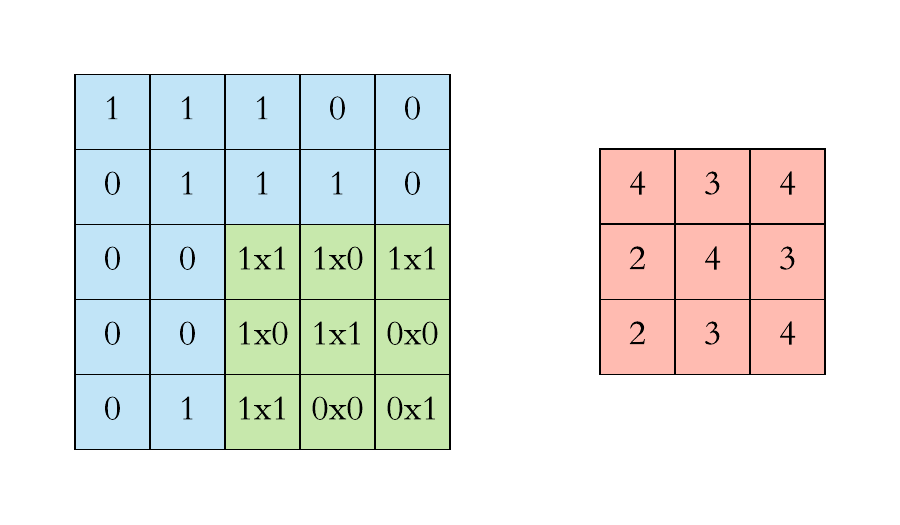
Graph Convolutional Networks (GCN)
Introduction: Graphs
- Graph = organised data representation
- Consists of vertices (nodes) V and edges E
- Edges can be weighted or binary
- Edges can be directed or undirected
Example graph:
\[V = \{A, B, C, D, E, F, G\}\] \[E = \{(A,B), (B,C), (C,E), ...\}\]
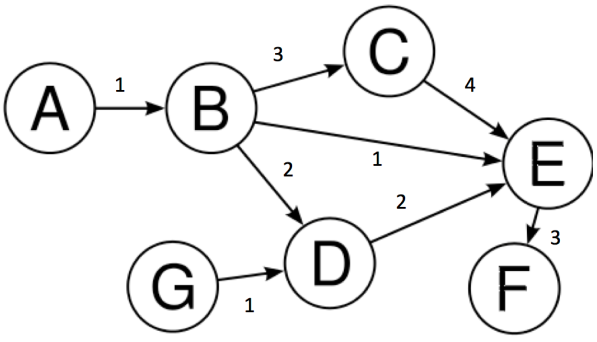
Graph Terminology
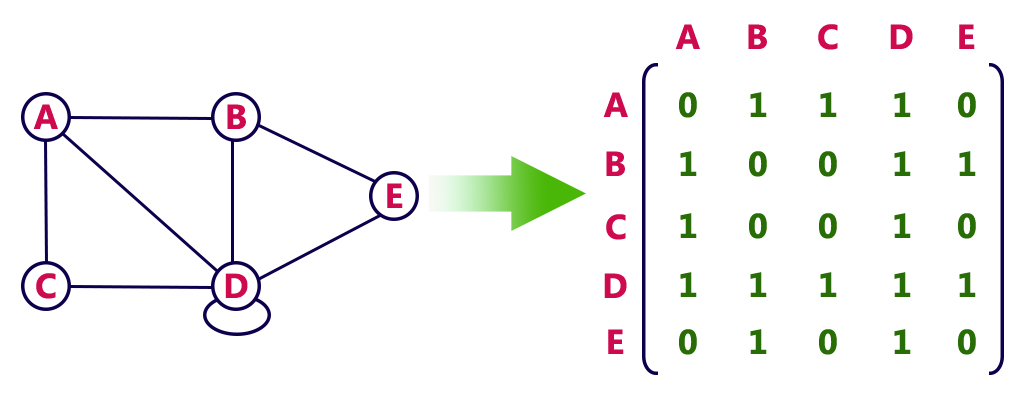
- Node: An entity in the graph (represented by circles)
- Edge: Line joining two nodes (represents relationships)
- Degree: Number of edges incident with a vertex
- Adjacency Matrix: N×N matrix representing graph structure
Why GCNs?
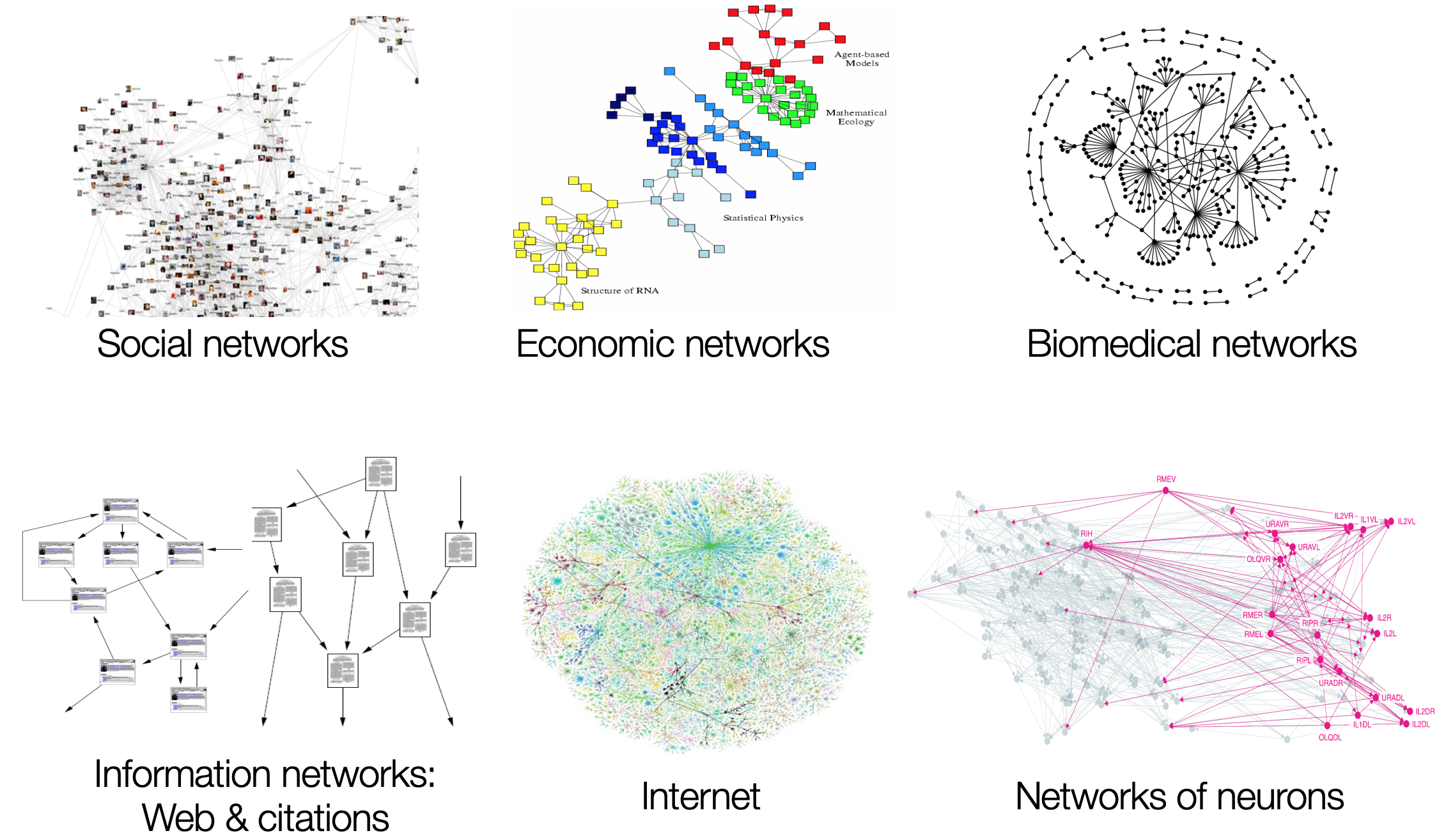
CNNs vs GCNs
CNN Key Properties:
- Locality
- Stationarity (Translation Invariance)
- Multi-scale hierarchies
Problem: Not all data lies on Euclidean space!
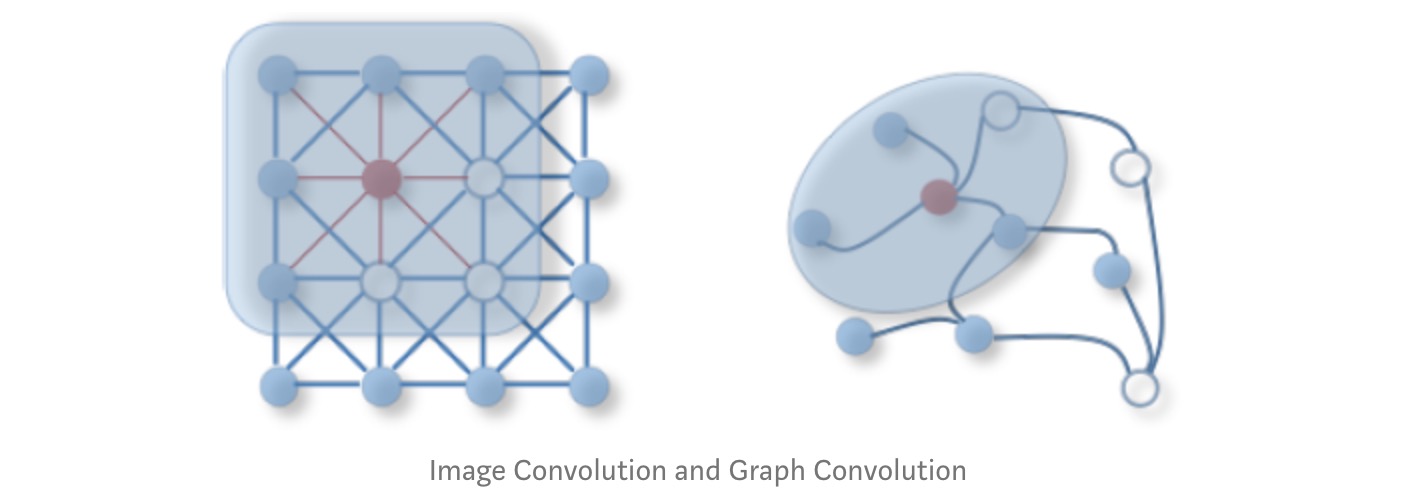
Applications of GCNs
Facebook Link Prediction for Suggesting Friends using Social Networks- Friend prediction algorithms
- Social network analysis
- Protein interaction prediction
- Knowledge graph completion
How GCNs Work? Friend Prediction
Task: Predict future friendships
- Edges = friendships
- More common friends → higher likelihood
- \((1,3)\) have 2 common friends
- \((1,5)\) have 0 common friends
- So, \((1,3)\) is more likely to become friends than \((1,5)\)

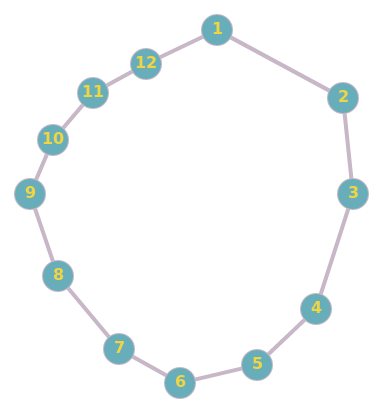
Try it again - Friend Prediction
Problem: Predict future friendships
- \((1,11)\) have 1 common friends and distance of 2
- \((3,11)\) have 0 common friends and distance of 4
- So, \((1,11)\) is more likely to become friends than \((3,11)\)
How to implement this idea MATHMATICALLY?
- Using filtering, from CNN?
- In CNN, we apply a filter on an image to get representation of next layer
- In a graph, we apply a filter to create the next layer representation, by aggregating the features of neighbours
- Note: in each layer, the graph structure is fixed, but the features of each node are updated.
Adjacency matrix & feature matrix
Adjacency matrix \[ A = \begin{pmatrix} 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 \\ 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 \\ 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 \end{pmatrix} \]
Feature matrix (Randomly initialised. Can be age, hobby, etc) \[ H^0 = \left( \begin{array}{ccc} 1 & 0 & 1 \\ 1 & 1 & 0 \\ 0 & 1 & 1 \\ 1 & 1 & 1 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 0 \\ 1 & 1 & 0 \end{array} \right) \]
Layer 1: \(H^1 = A H^0\)
- Node 1 (Neighbours: 2, 4):\(h_1^1 = h_2^0 + h_4^0 = [1, 1, 0] + [1, 1, 1] = \mathbf{[2, 2, 1]}\)
- Node 3 (Neighbours: 2, 4):\(h_3^1 = h_2^0 + h_4^0 = [1, 1, 0] + [1, 1, 1] = \mathbf{[2, 2, 1]}\)
- Node 5 (Neighbour: 6):\(h_5^1 = h_6^0 = \mathbf{[0, 1, 0]}\)
- Note: Node 1 and 3 have identifical features after one layer, due to same set of neighbours.
- \((1,3)\) is more similar than \((1,5)\)
Layer 2: \(H^2 = A H^1\). Friend-of-friend
- Node 1 (Neighbours: 2, 4):\(h_1^2 = h_2^1 + h_4^1 = [1, 1, 2] + [1, 1, 2] = \mathbf{[2, 2, 4]}\)
- Node 3 (Neighbours: 2, 4):\(h_3^2 = h_2^1 + h_4^1\)\(h_3^2 = [1, 1, 2] + [1, 1, 2] = \mathbf{[2, 2, 4]}\)
- Node 5 (Neighbour: 6):\(h_5^2 = h_6^1\)\(h_6^1 = h_5^0 + h_7^0 + h_8^0 = [2, 1, 1] = \mathbf{[2, 1, 1]}\)
- \((1,3)\) is more similar than \((1,5)\)
Problem 1: No self-representation
- New features don’t include node’s own features
- Node 1 and 3 become identical after one layer, despite different initial features
- Node 1 (Neighbours: 2, 4):\(h_1^1 = h_2^0 + h_4^0 = [1, 1, 0] + [1, 1, 1] = \mathbf{[2, 2, 1]}\)
- Node 3 (Neighbours: 2, 4):\(h_3^1 = h_2^0 + h_4^0 = [1, 1, 0] + [1, 1, 1] = \mathbf{[2, 2, 1]}\)
- Solution: Add self-loops
- Add identity: \(\hat{A} = A + I\)
- Node 1: \(h_1^1 = h_1^0 + h_2^0 + h_4^0 = [1,0,1] + [1,1,0] + [1,1,1] = \mathbf{[3, 2, 2]}\)
- Node 3: \(h_3^1 = h_2^0 + h_3^0 + h_4^0 = [1,1,0] + [0,1,1] + [1,1,1] = \mathbf{[2, 3, 2]}\)
- Now, they are different due to self-loops
Problem 2: Degree scaling
- High-degree nodes get larger values; low-degree nodes get smaller values
- Node 5 (Self + 6):\(h_5^1 = h_5^0 + h_6^0 = [0, 0, 1] + [0, 1, 0] = \mathbf{[0, 1, 1]}\)
- Node 6 (Self + 5, 7, 8):\(h_6^1 = h_6^0 + h_5^0 + h_7^0 + h_8^0 = [0, 1, 0] + [0, 0, 1] + [1, 0, 0] + [1, 1, 0] = \mathbf{[2, 2, 1]}\)
GCN Network Architecture
Case Study: Zachary’s Karate Club
Context (1970-1972):
- Observed local karate club
- Conflict between administrator “John A” and instructor “Mr. Hi” led to club split into two groups
- Based on this graph, aim to predict which members join which group

Training the model
- What parameters are trained? Weight matrix W and a bias vector for each layer (intercept)
- Layer 1 (conv1): A matrix of size (nfeat, nhid)
- Layer 2 (conv2): A matrix of size (nhid, nout)
\[f(H^{(l)}, A) = \sigma\left( \hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}\right)\]
Training Visualisation
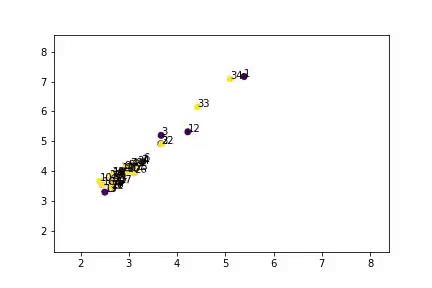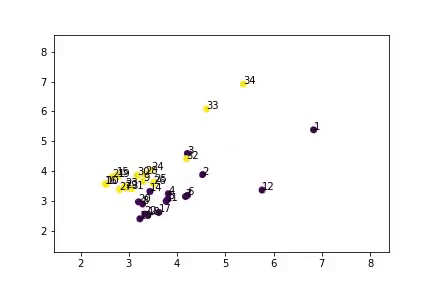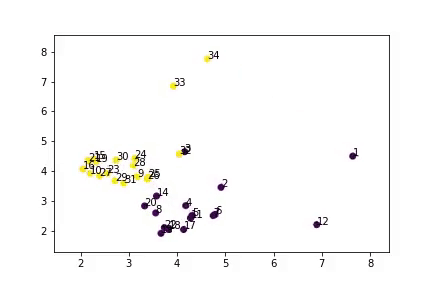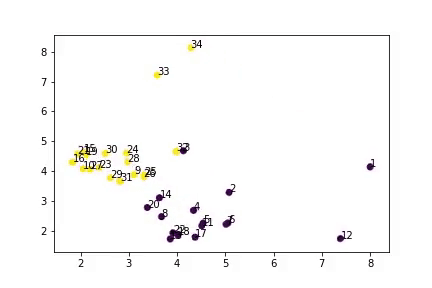
Node embeddings learned during training- Model successfully separates two groups
- Close to actual predictions (except node 9)
- Semi-supervised learning works!
Why GraphSAGE (Sample and Aggregate)?
- GCNs are transductive: requires full graph structure; can’t generalise to unseen nodes/graphs
- GraphSAGE is inductive: learns aggregation functions that can be applied to unseen nodes/graphs
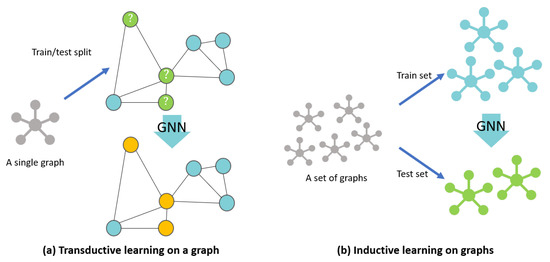
Transductive vs inductive learning on graph. Source: https://www.mdpi.com/2220-9964/10/2/97GraphSAGE Aggregators
- Mean aggregator: elementwise mean over neighbors
- Pool aggregator: transform neighbor features using a MLP, then max-pool
- LSTM aggregator: sequence model over randomly ordered neighbors
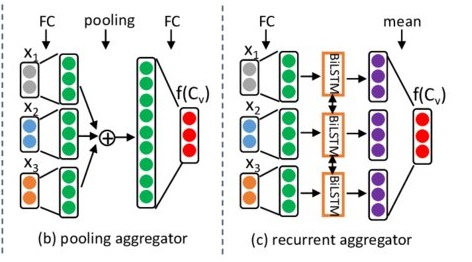
Example of GraphSAGE update rules
- Step 1: Initial Features (\(H^0\))
- Node 6: \(h_6^0 = [0, 1]\)
- Neighbours (5, 7, 8): \(h_5^0 = [0, 0]\), \(h_7^0 = [1, 0]\), \(h_8^0 = [1, 1]\)
Step 2: Aggregate the Neighbours
\[\text{AGG}_{\text{neigh}} = \text{mean}([0, 0], [1, 0], [1, 1]) = [0.66, 0.33]\]
Step 3: Concatenation
- Join the self-vector and the neighbour-vector (increase dimension from 2 to 4) \[\text{CONCAT}(h_6^0, \text{AGG}_{neigh}) = [ \underbrace{0, 1}_{\text{Self}}, \underbrace{0.66, 0.33}_{\text{Neighbours}} ]\]
What is ATTENTION in GAT?
- Attention weight \(\alpha_{i,j}\) measures the importance of neighbor \(j\) to node \(i\)
\(h_i^{(l+1)} = \sigma \left( \sum_{j \in \mathcal{N}_i} \alpha_{ij}^{(l)} \mathbf{W}^{(l)} h_j^{(l)} \right)\)
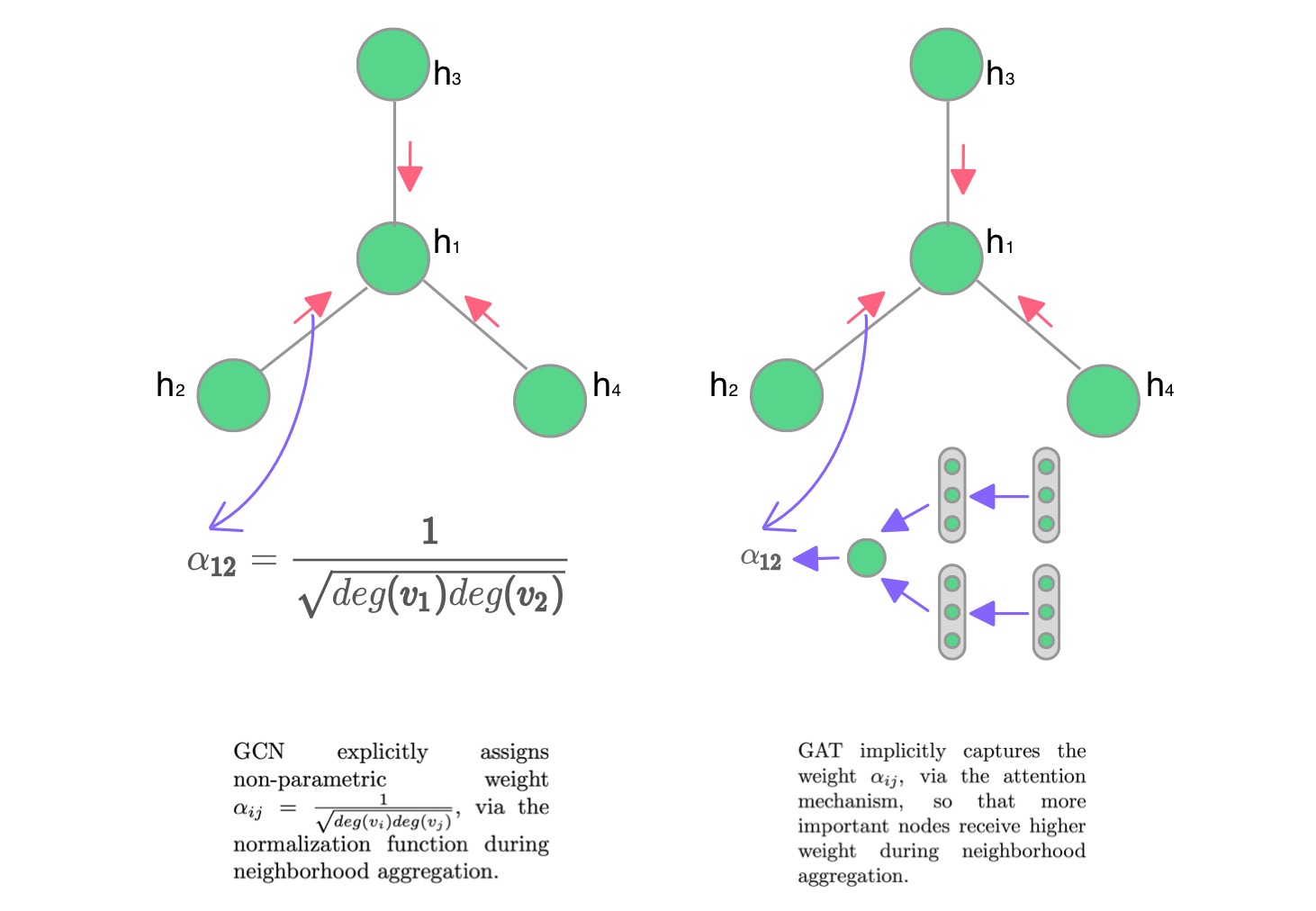
Attention weight
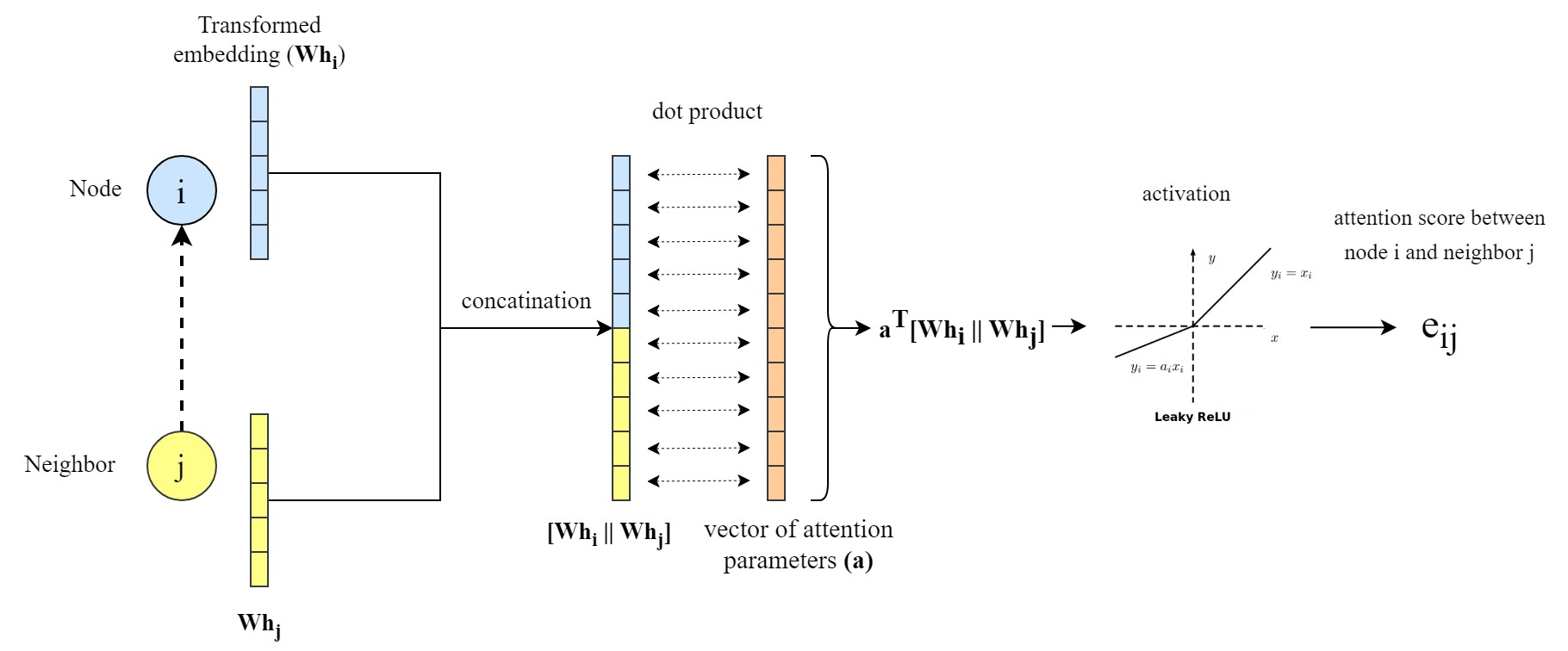
- A clear explanation: https://epichka.com/blog/2023/gat-paper-explained/
Masked Attention
- Only weights for neighbors are computed, others masked
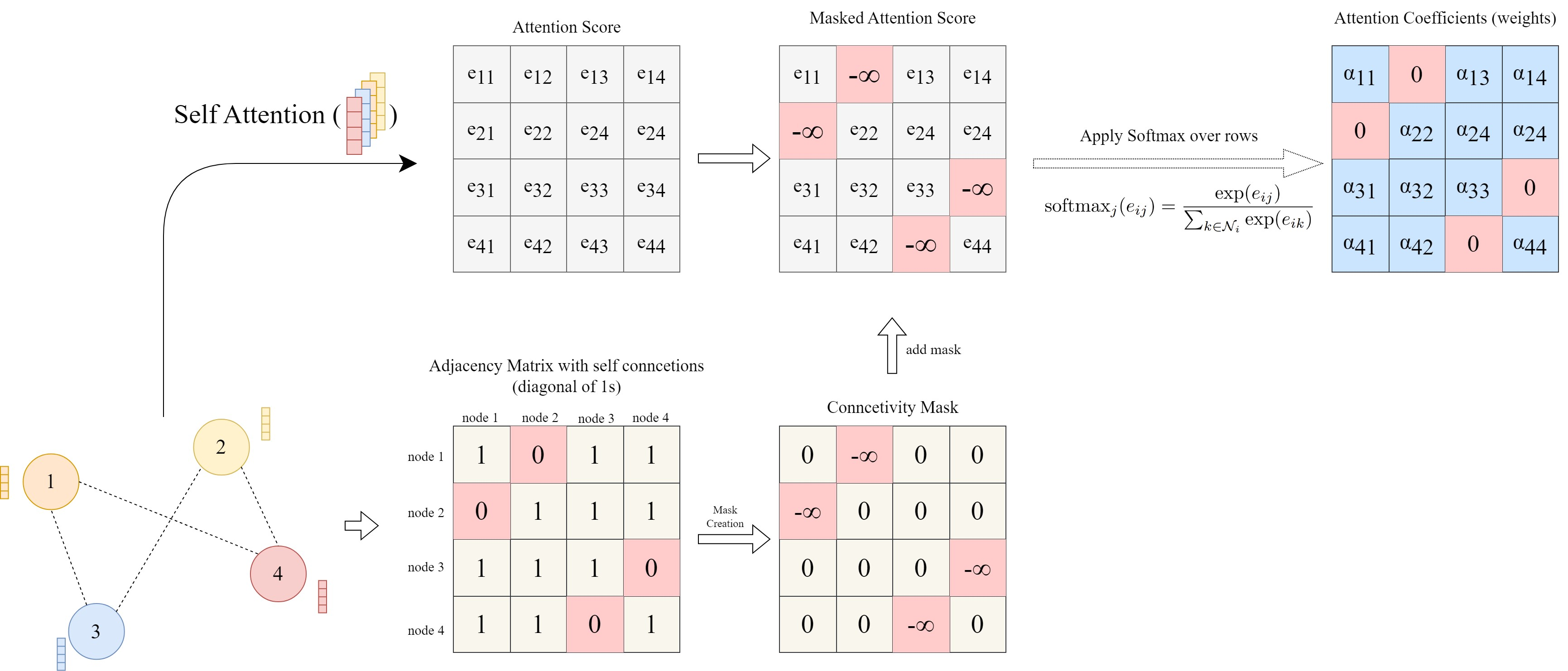
Multi-head Attention to stabilise learning
- To mitigate randomness in calculating attention weights, e.g. random initialisation
\[h_i^{(l+1)} = \sigma \left( \frac{1}{K} \sum_{k=1}^{K} \sum_{j \in \mathcal{N}_i} \alpha_{ij}^{k} \mathbf{W}^{k} h_j^{(l)} \right)\]
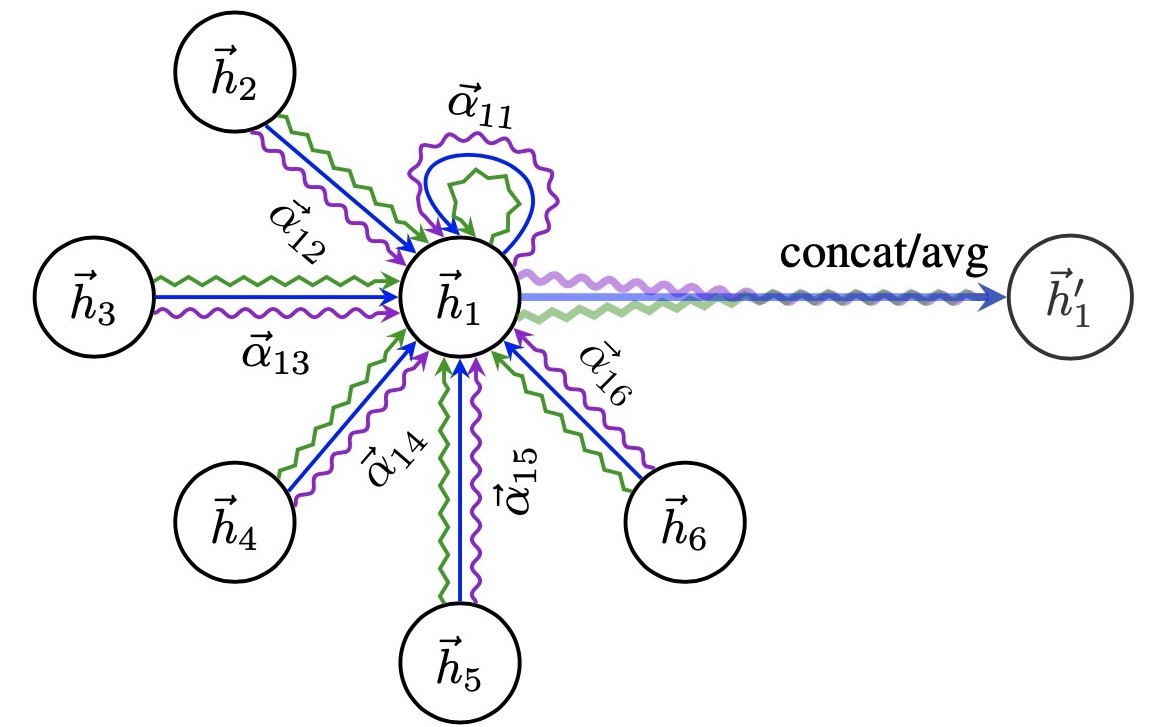
Concatenate intermediate heads; average at final layerAttention visualisation for interpretability
- To understand which neighbors are most influential for a node

https://www.dgl.ai/blog/2019/02/17/gat.html