Tree-Based Methods
Tree, Forest, and Gradient Boosting
- huanfa.chen@ucl.ac.uk
13/12/2025
Decision Trees for Classification
- Ask a sequence of binary questions on features
- A split with a threshold on a single feature divides data into two parts
- Leaves store class distributions
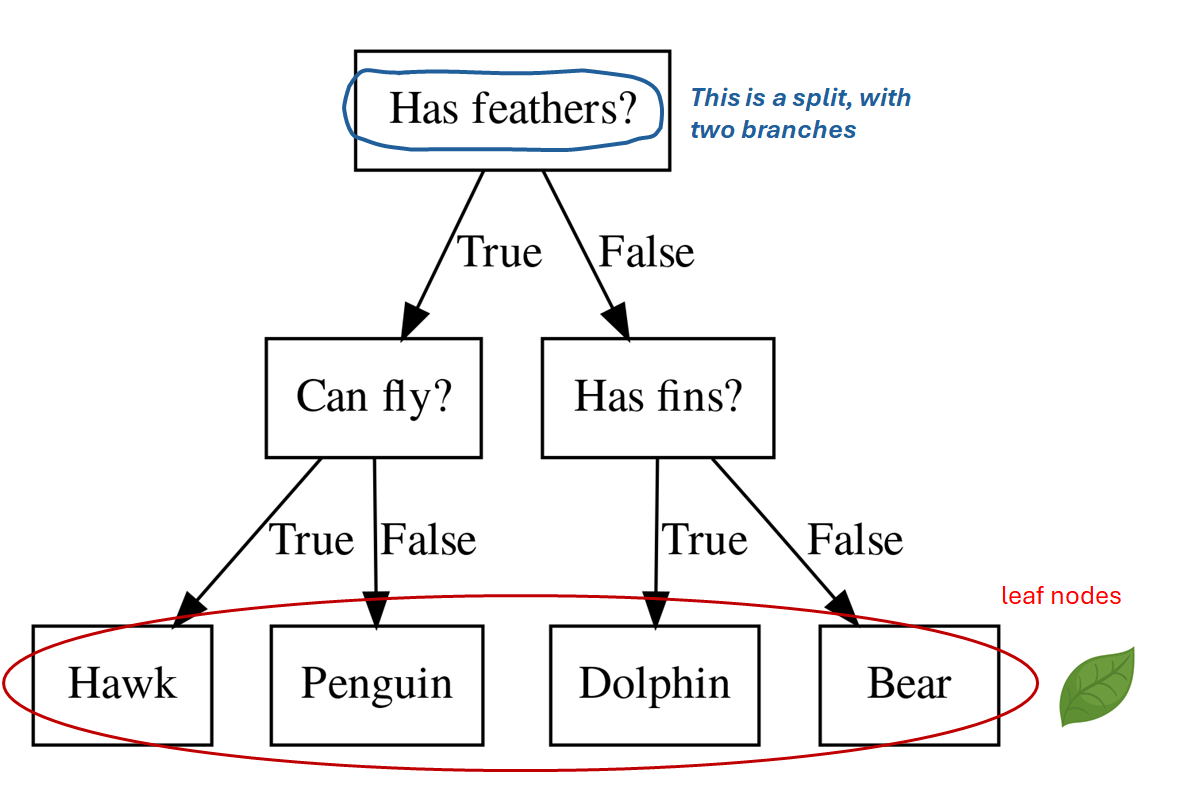
Building Trees
- Search all features and thresholds
- Choose split that most reduces impurity of data on a node
- Recurse on each child until stopping rule
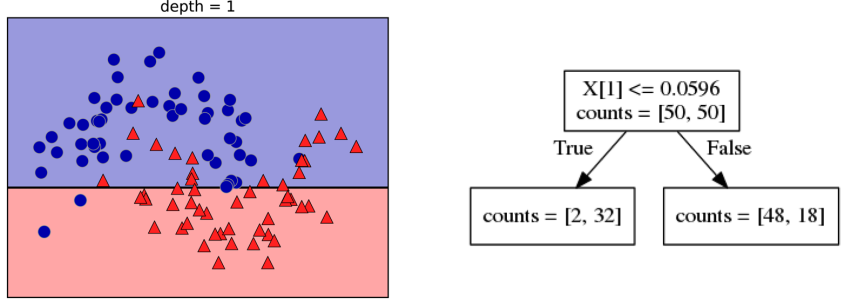
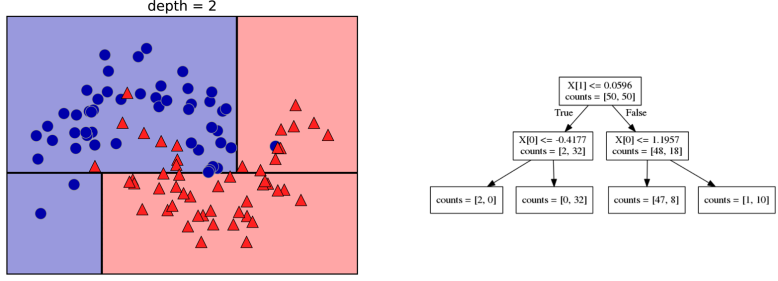
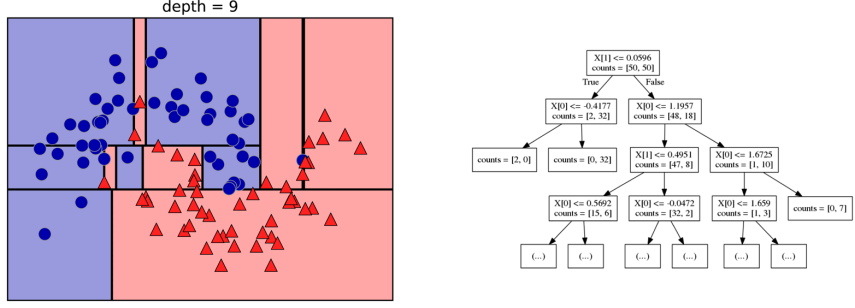
Prediction
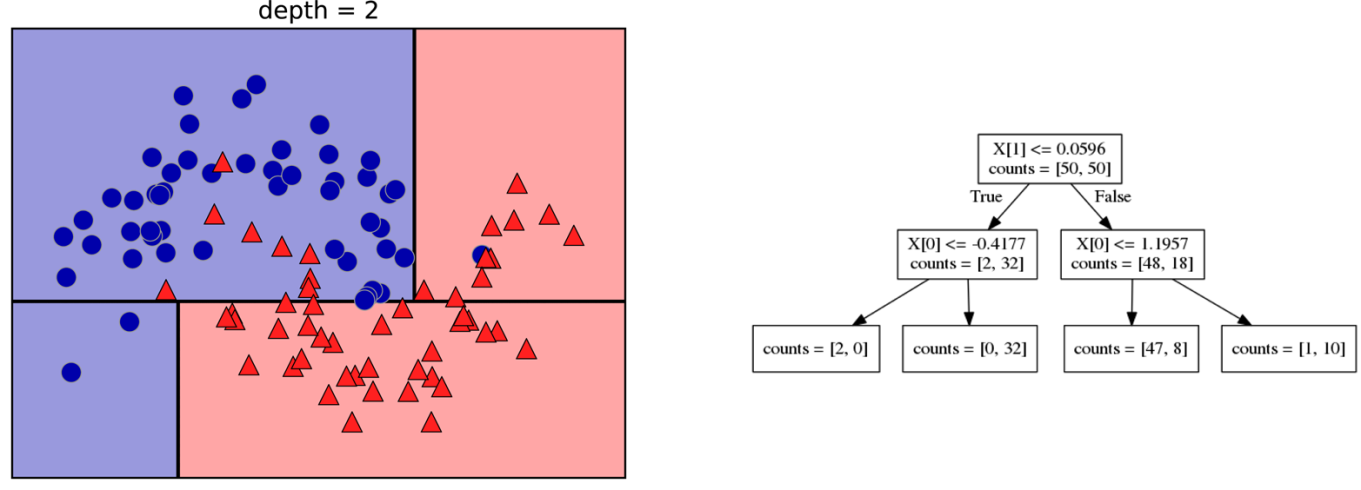
- Given a new sample, start from the top
- Traverse splits; follow feature tests
- Predict majority class in the reached leaf
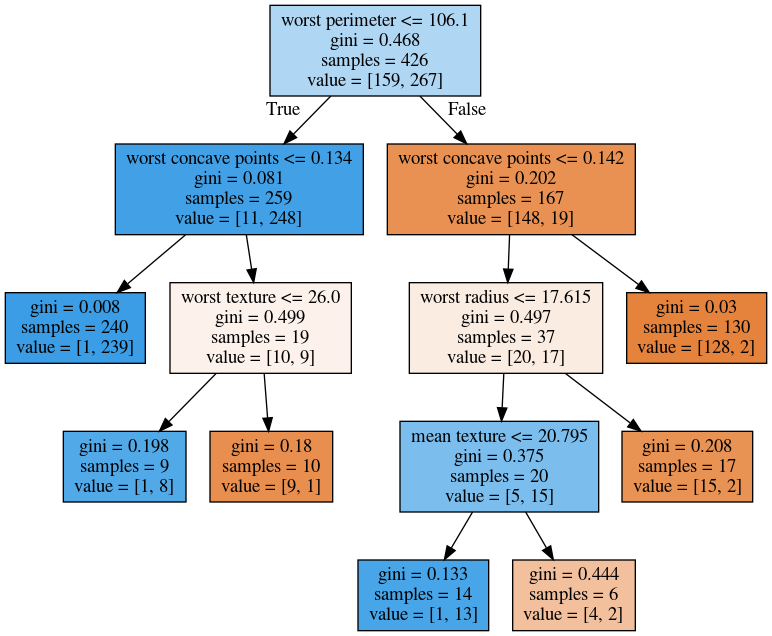
Visualising Trees (plot_tree)
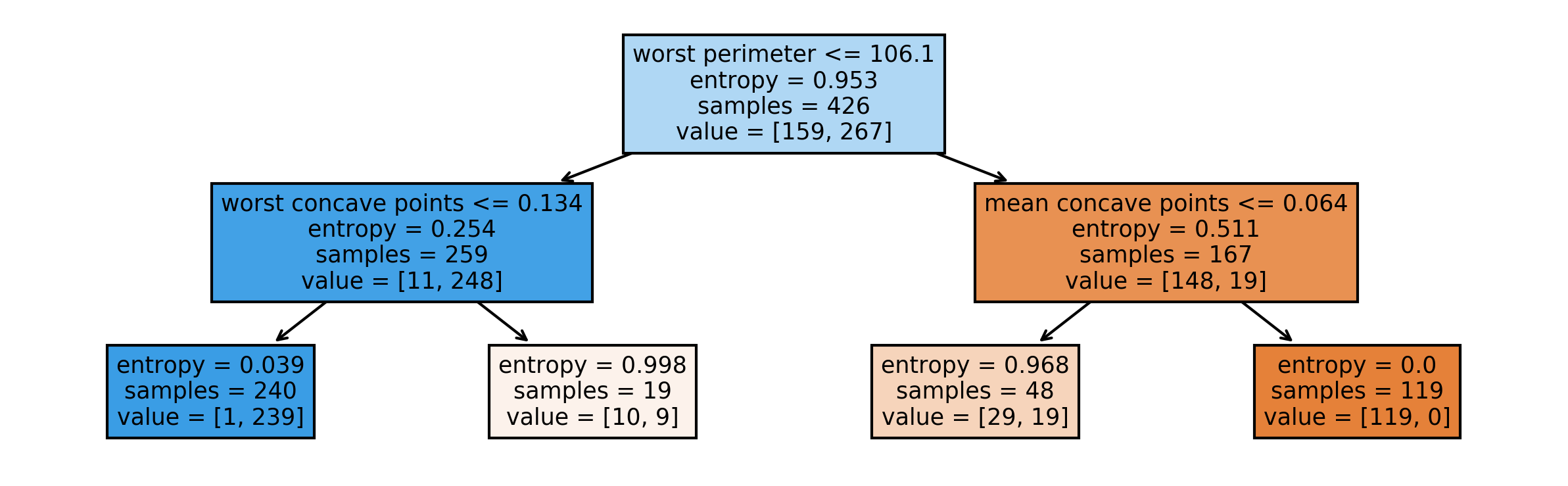
No Pruning
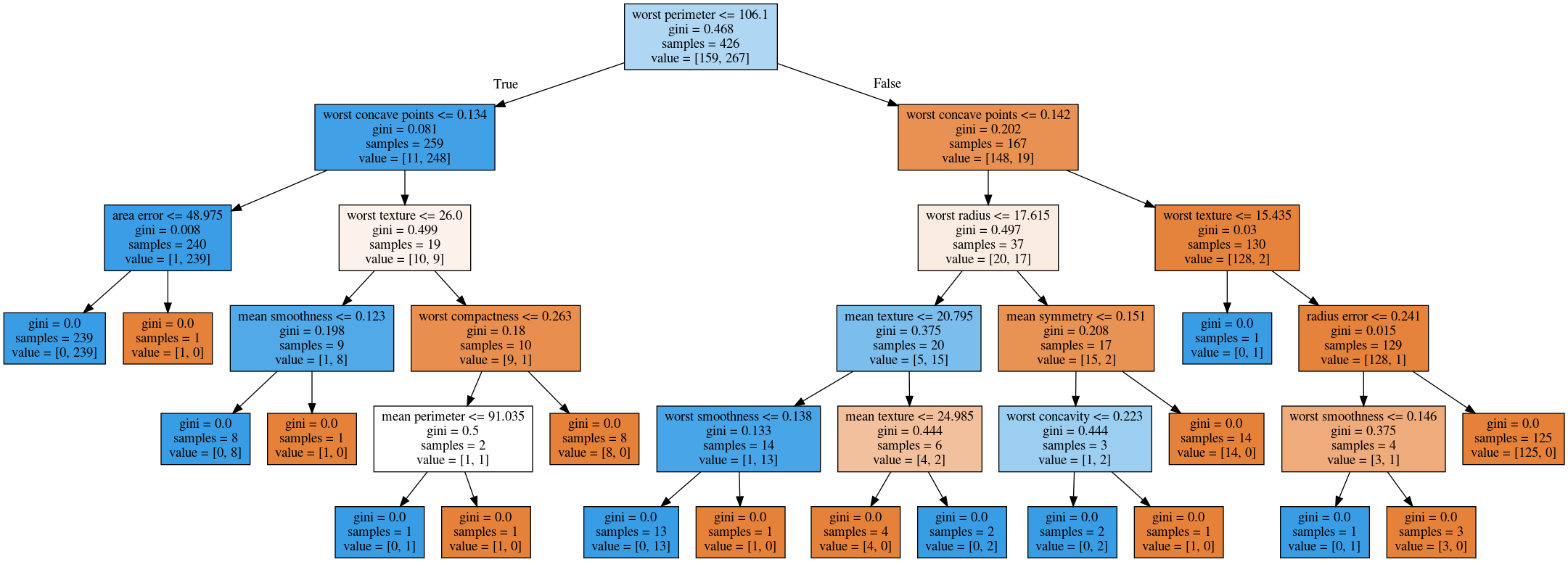
max_depth = 4
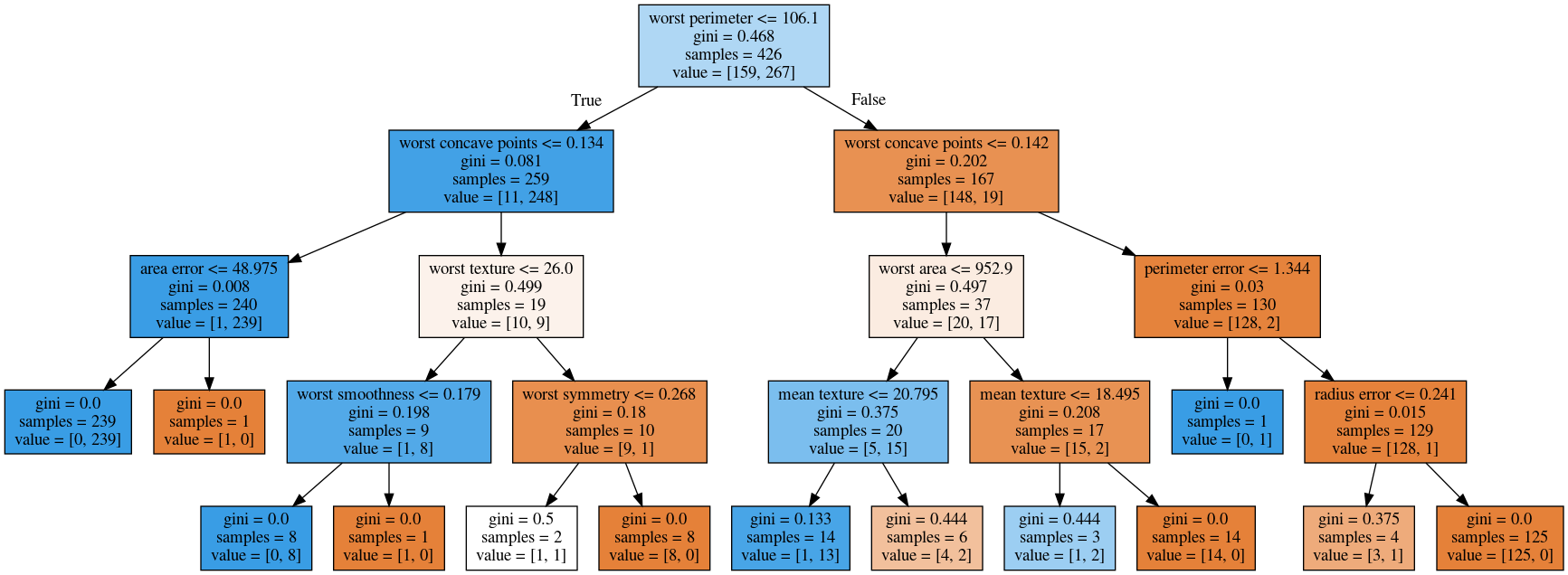
max_leaf_nodes = 8
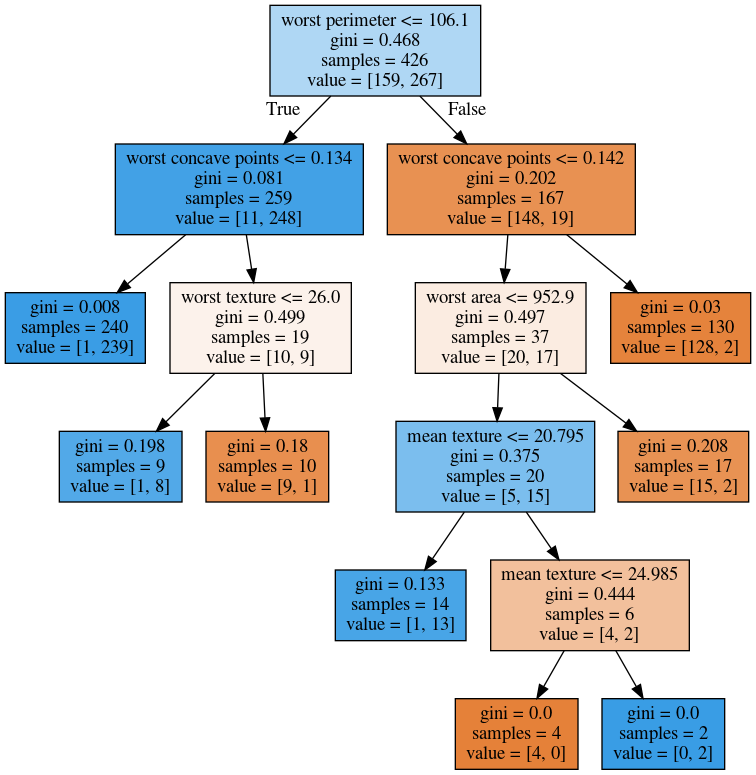
min_samples_split = 50
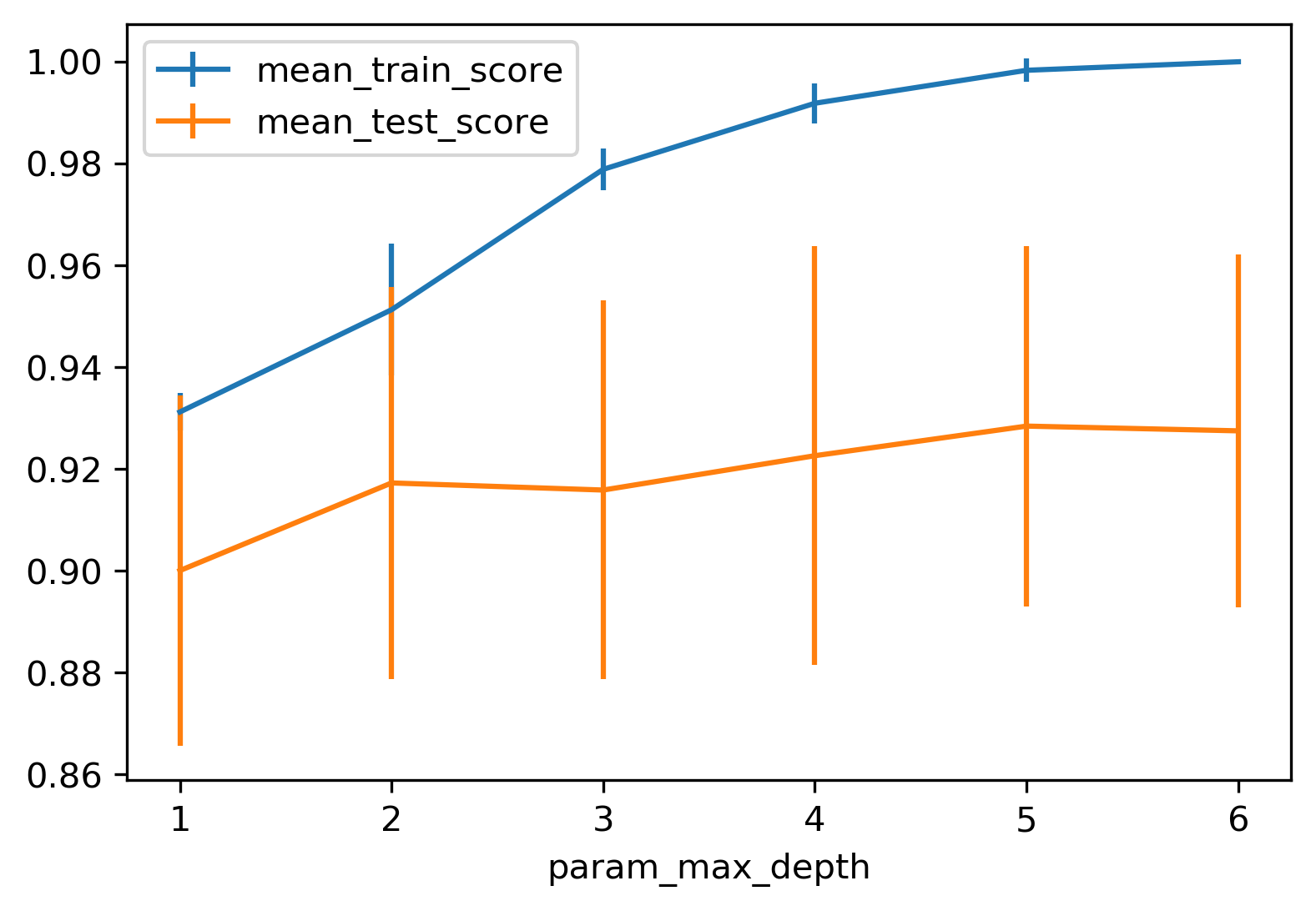
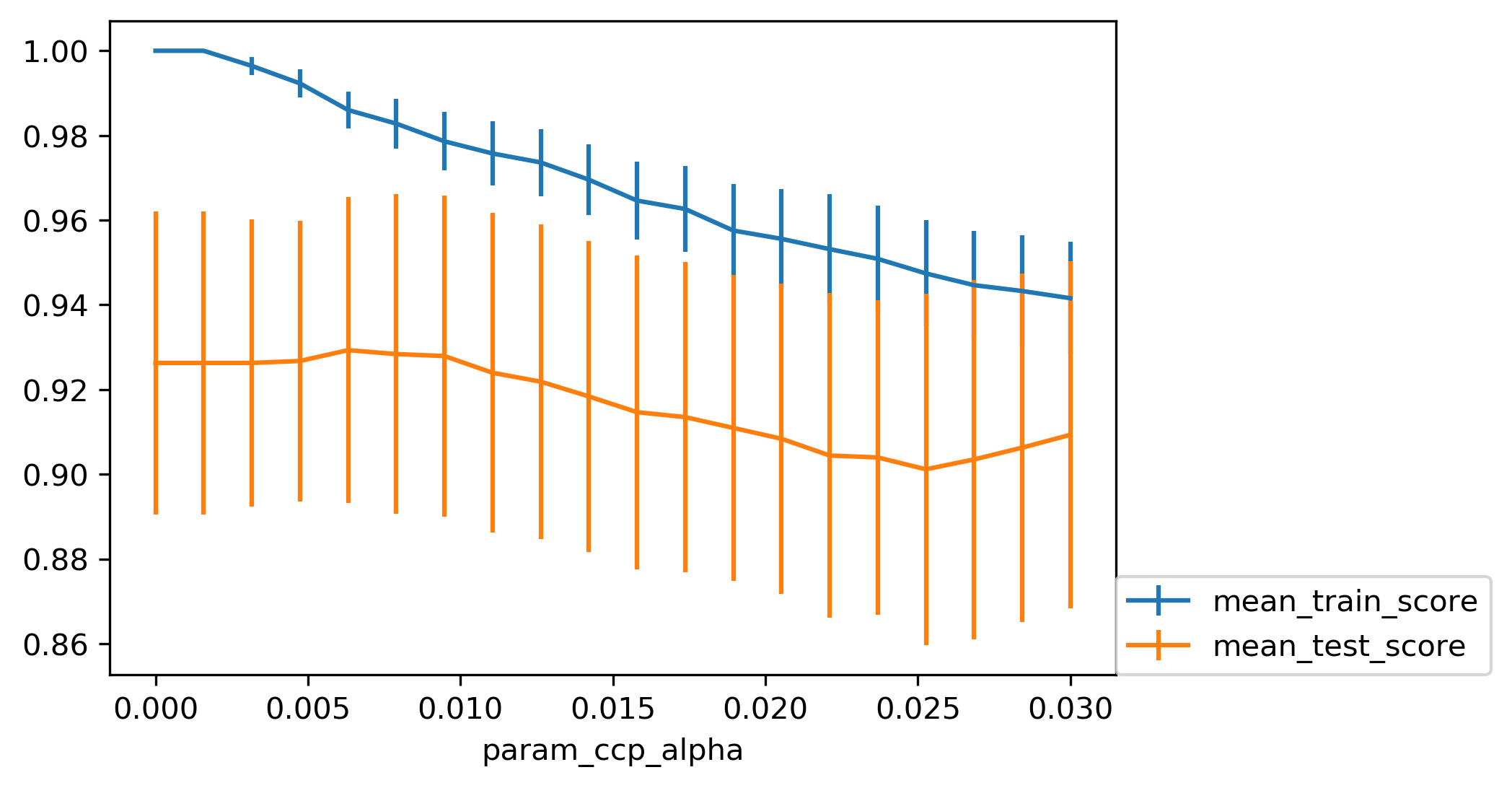
Grid Search: max_depth
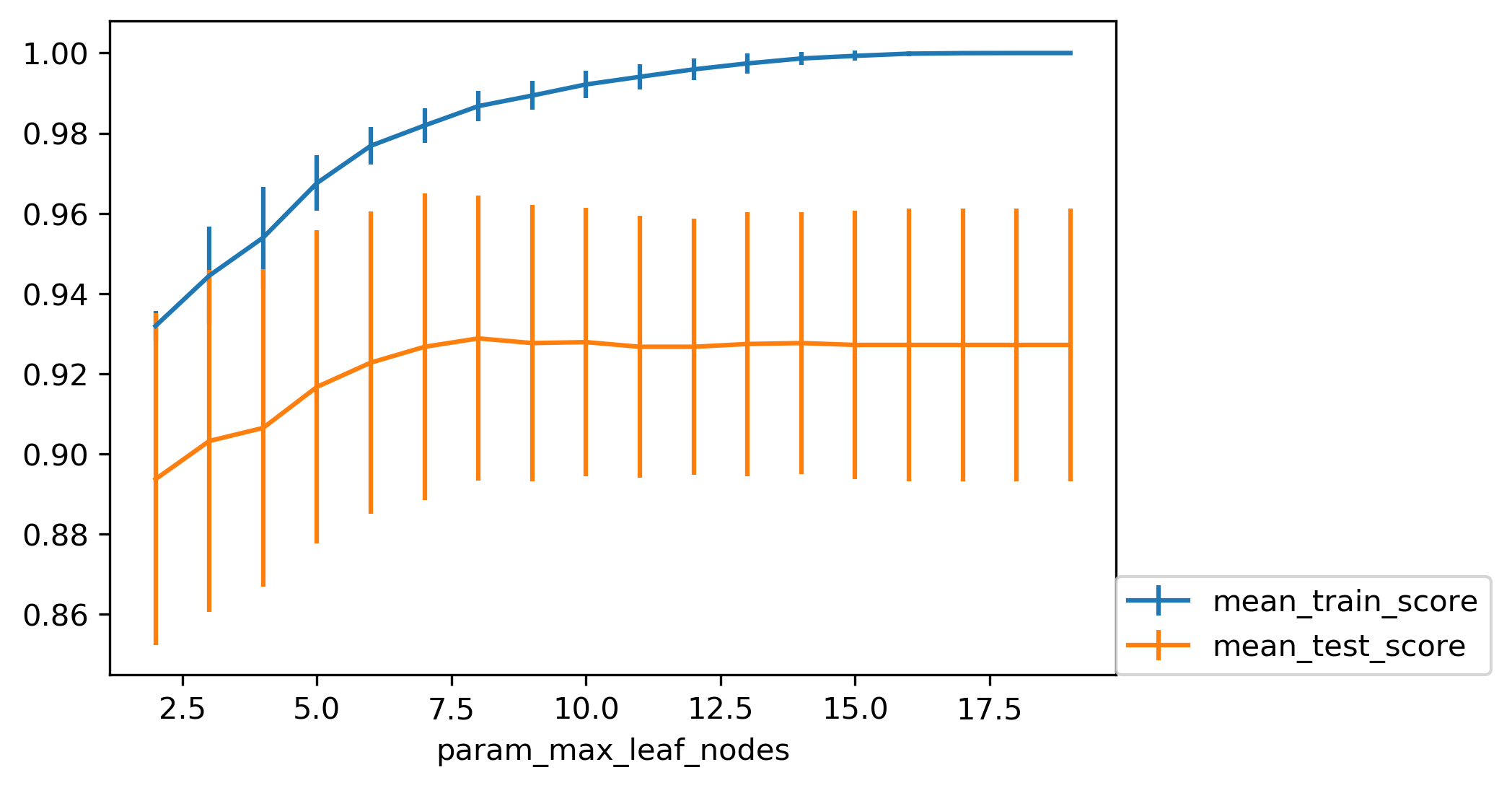
Grid Search: max_leaf_nodes
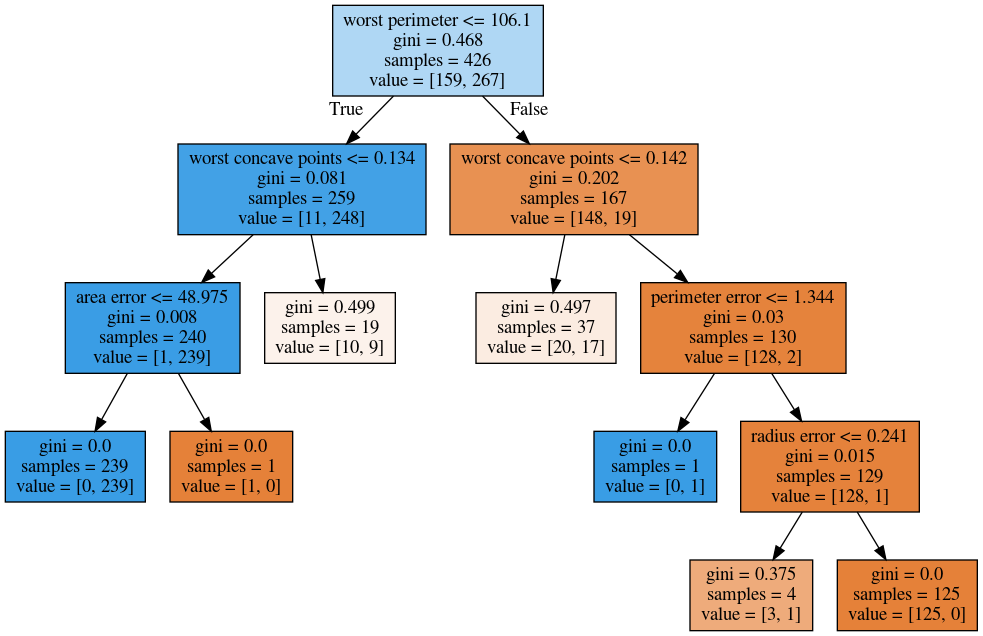
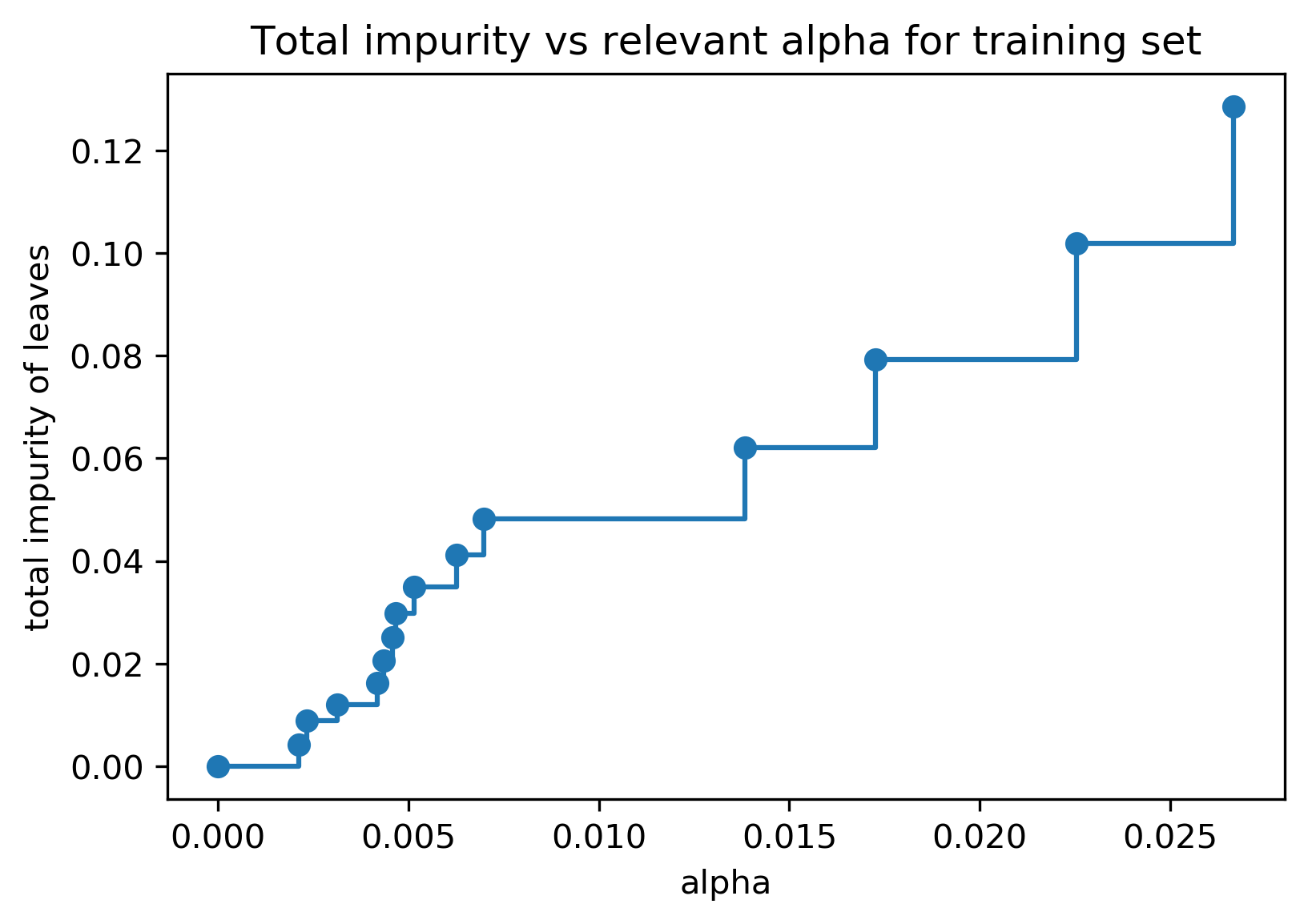
Cost Complexity Pruning
- Objective: \(R_\alpha(T) = R(T) + \alpha |T|\)
- \(R(T)\) = total leaf impurity; \(|T|\) = number of leaves; tune \(\alpha\)
Efficient Pruning Path
Post- vs Pre-Pruning
- Cost-complexity pruning result
- max_leaf_nodes search result
Feature Importance
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, stratify=iris.target, random_state=0)
tree = DecisionTreeClassifier(max_leaf_nodes=6).fit(X_train, y_train)
tree.feature_importances_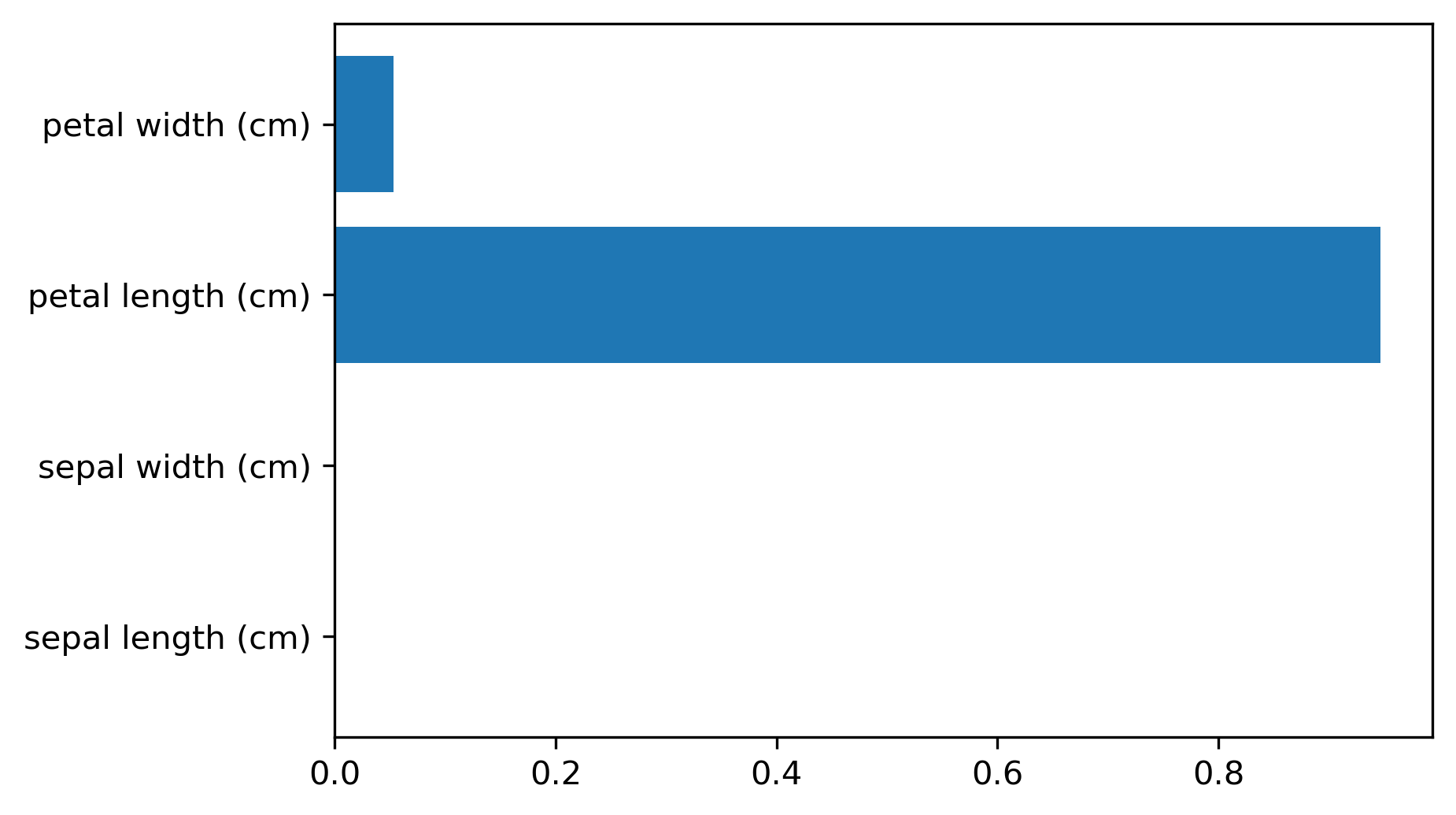
- Sum of impurity decreases per feature; magnitude only (no sign)
- Unstable with correlated features or different splits
Instability
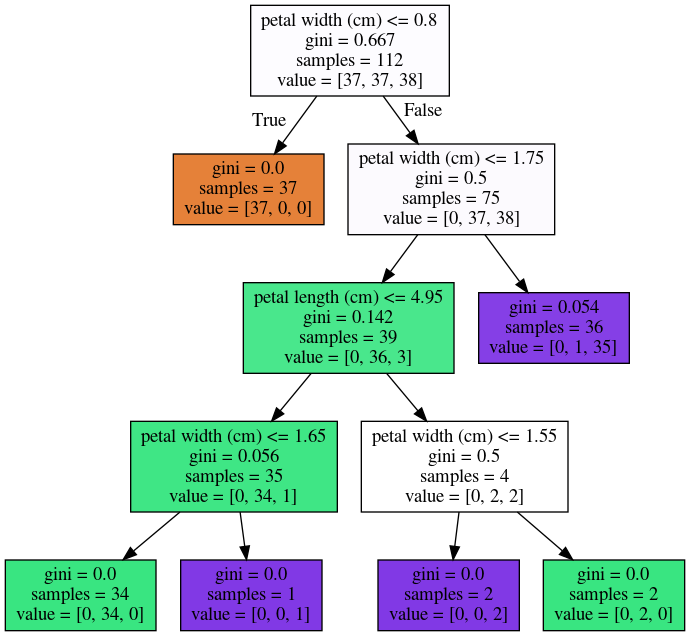
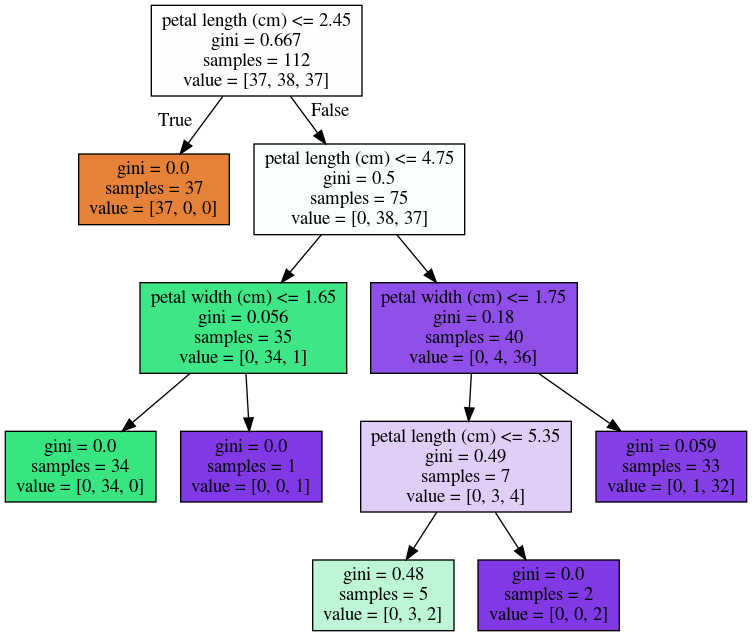
- Small data changes can alter splits
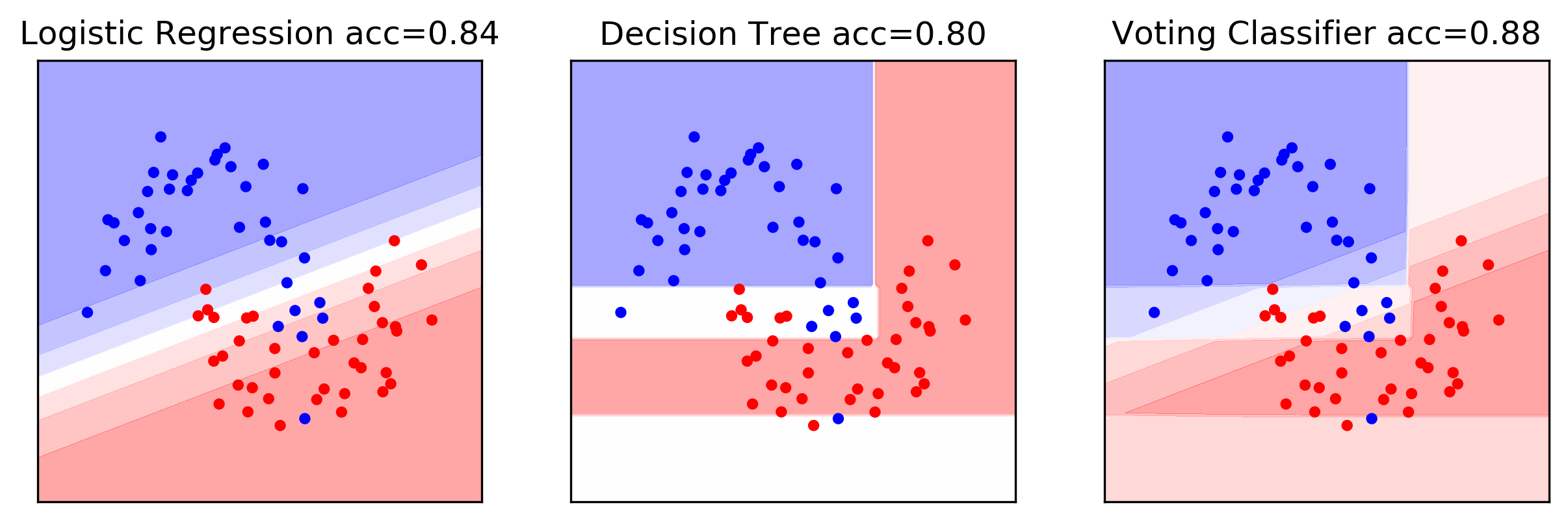
VotingClassifier Example
Bagging (Bootstrap Aggregation)
- Sample with replacement (same size as dataset)
- Train a model on each bootstrap sample
- Average predictions to cut variance
Bias and Variance
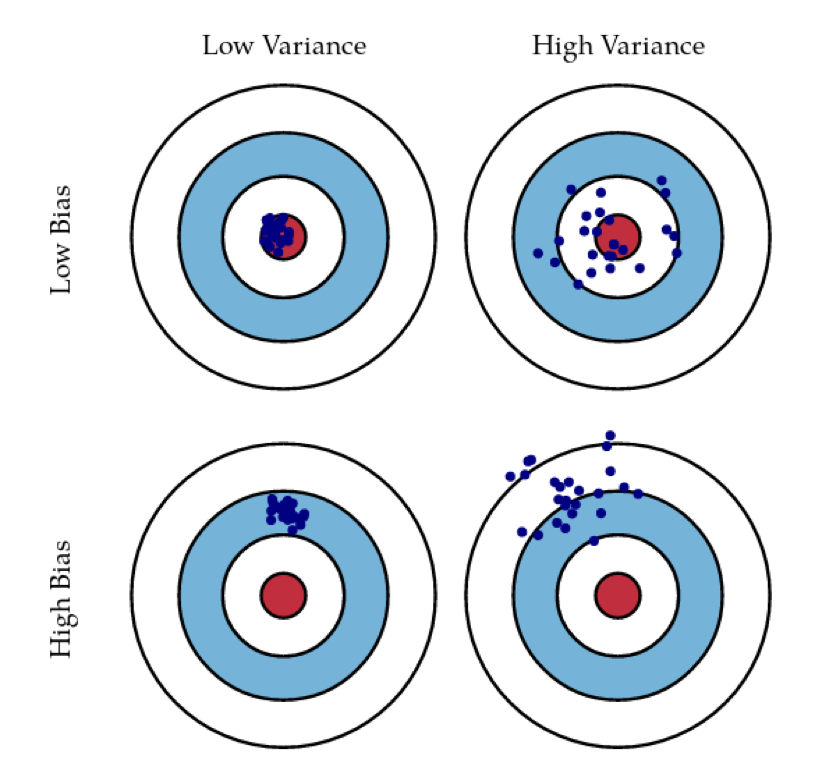
- Aim for low bias + low variance
- Averaging high-variance models can lower variance
Random Forests
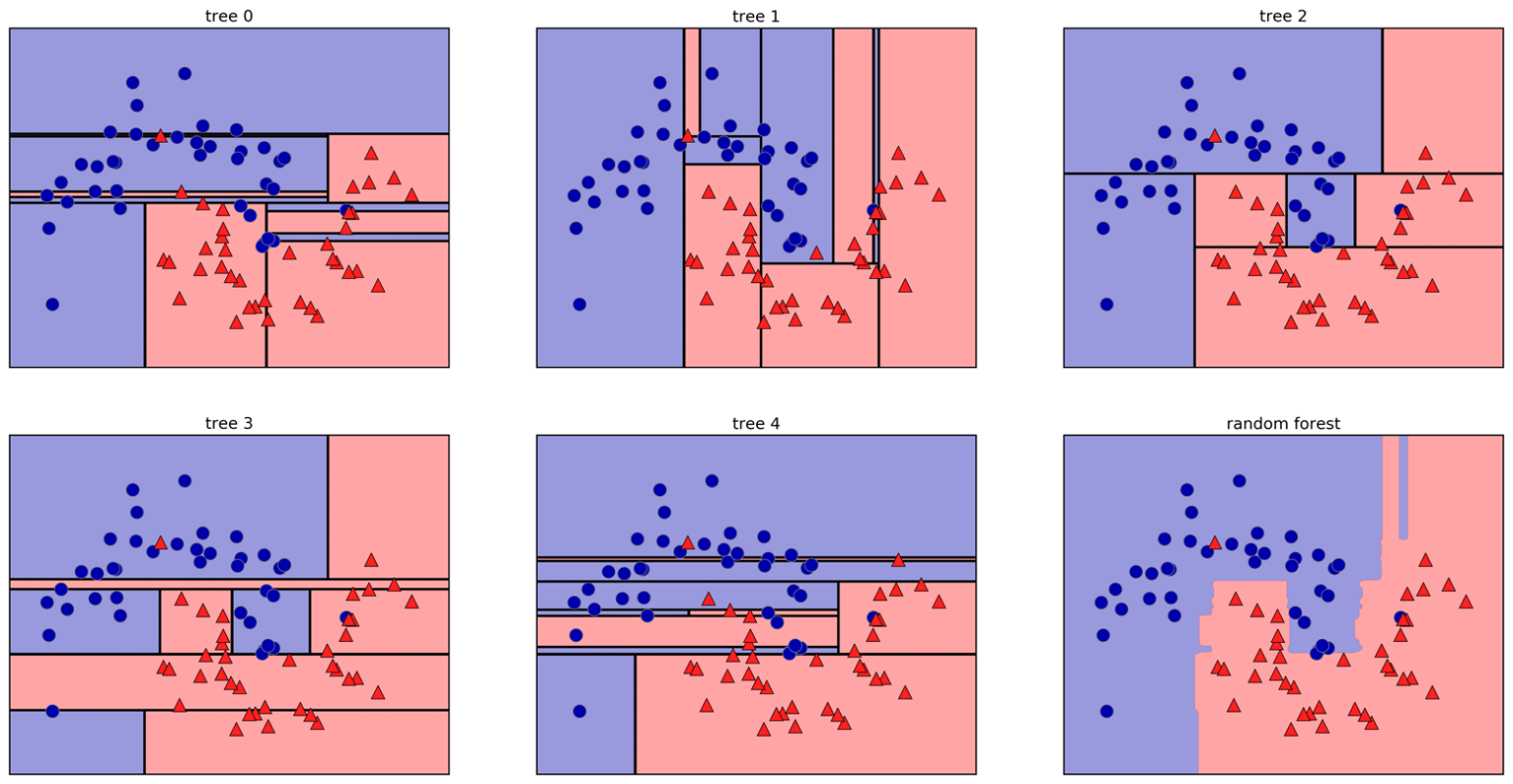
- Bagging + feature subsampling at each split
Randomise in Two Ways
- For each tree: bootstrap sample of rows
- For each split: sample features without replacement
- More trees → lower variance (diminishing returns)
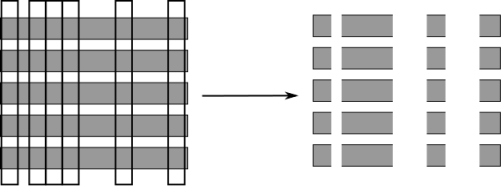
Warm-Starts
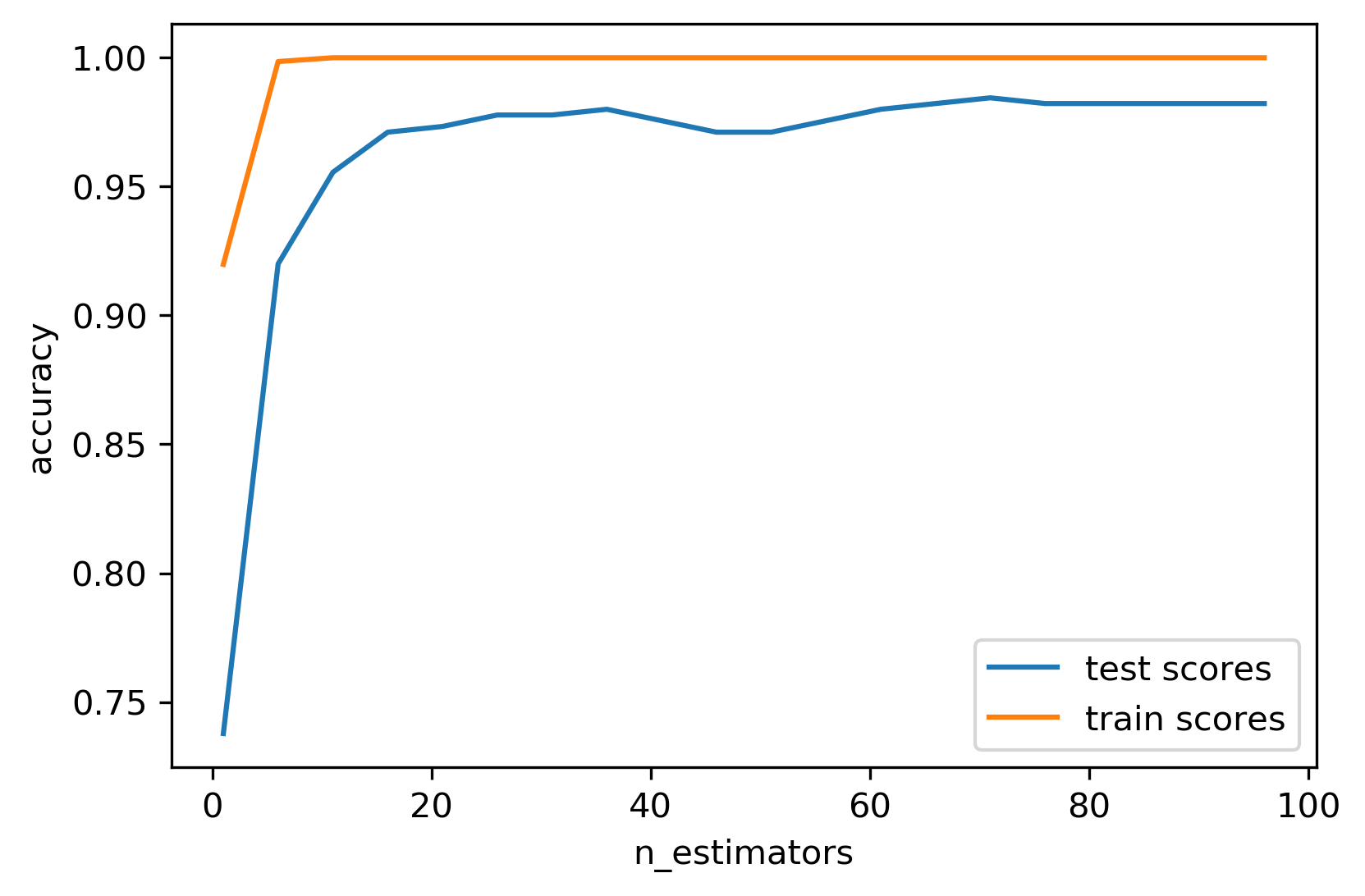
- Increase trees incrementally; stop when scores stabilise
Out-of-Bag Estimates (optional)
- Each tree trains on ~66% of data; predict remaining ~34%
- Average OOB predictions as a free validation score
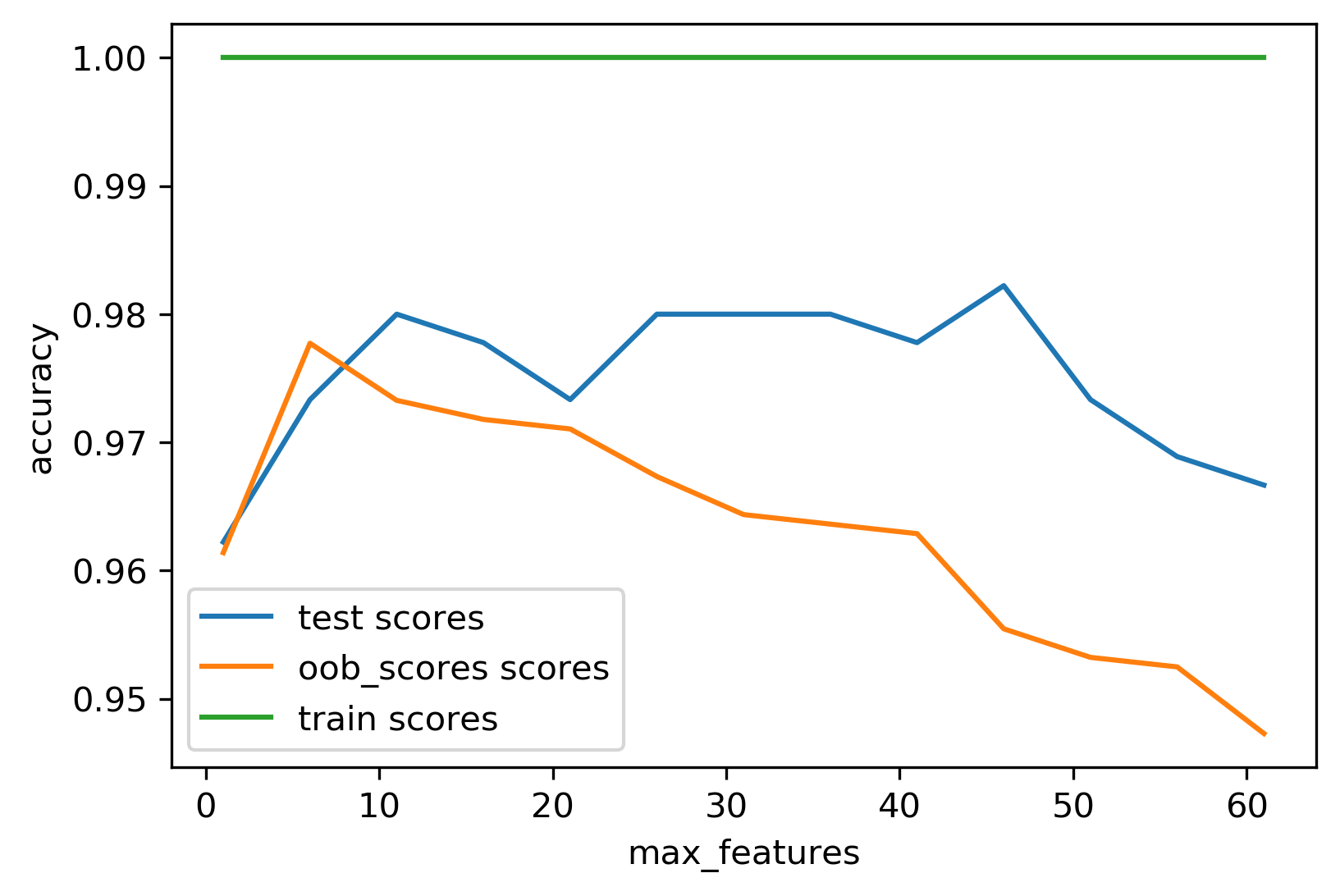
Variable Importance (RF)

- More stable than single-tree importances; still magnitude-only
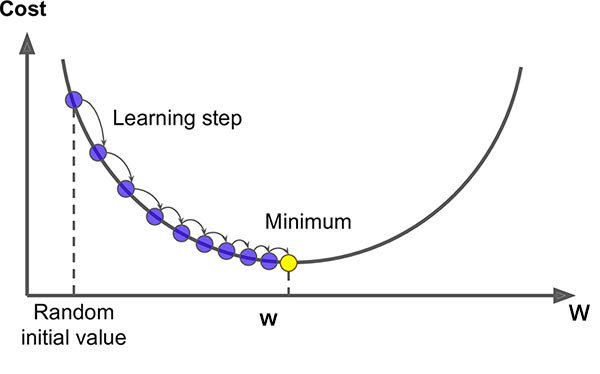
Gradient Descent
- Optimise \(\arg\min_w F(w)\) by stepping along \(-\nabla F(w)\)
- Update: \(w_{i+1} = w_i - \eta_i \nabla F(w_i)\)
- Converges to a local minimum (global for convex losses)
Regression Example
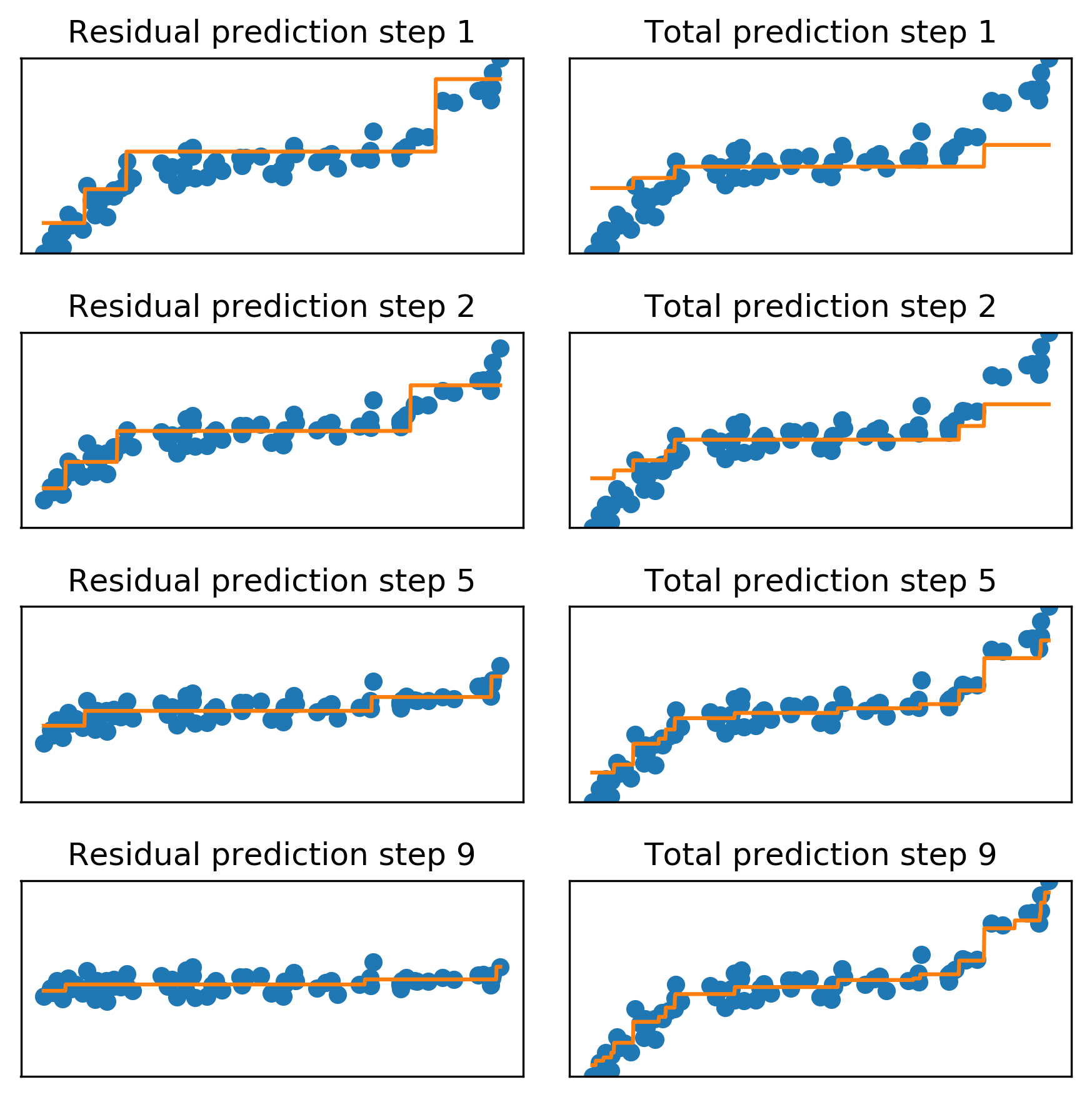
- Shallow trees fit residuals sequentially until residuals shrink
Classification Example
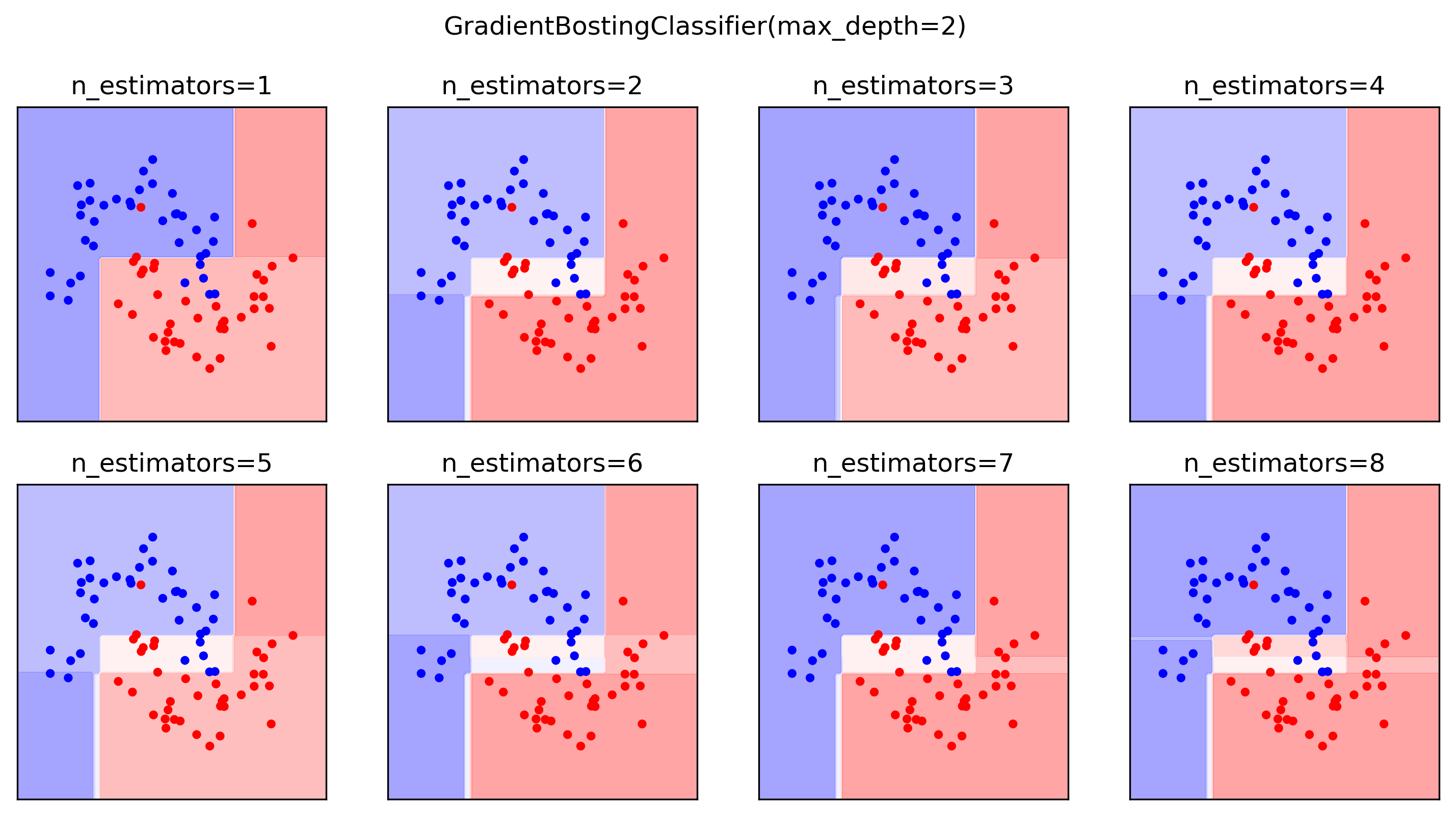
- Probability surfaces become sharper as trees accumulate
- Multiclass: one regression tree per class per step