random_seed best_validation_score best_k test_set_score
0 0 0.7 5 0.846154
1 1 0.7 1 0.538462
2 2 1.0 13 0.692308
3 3 0.7 1 0.846154
4 4 0.9 5 0.769231
5 5 0.8 11 0.769231Supervised learning workflow
Model training and selection
- huanfa.chen@ucl.ac.uk
13/12/2025
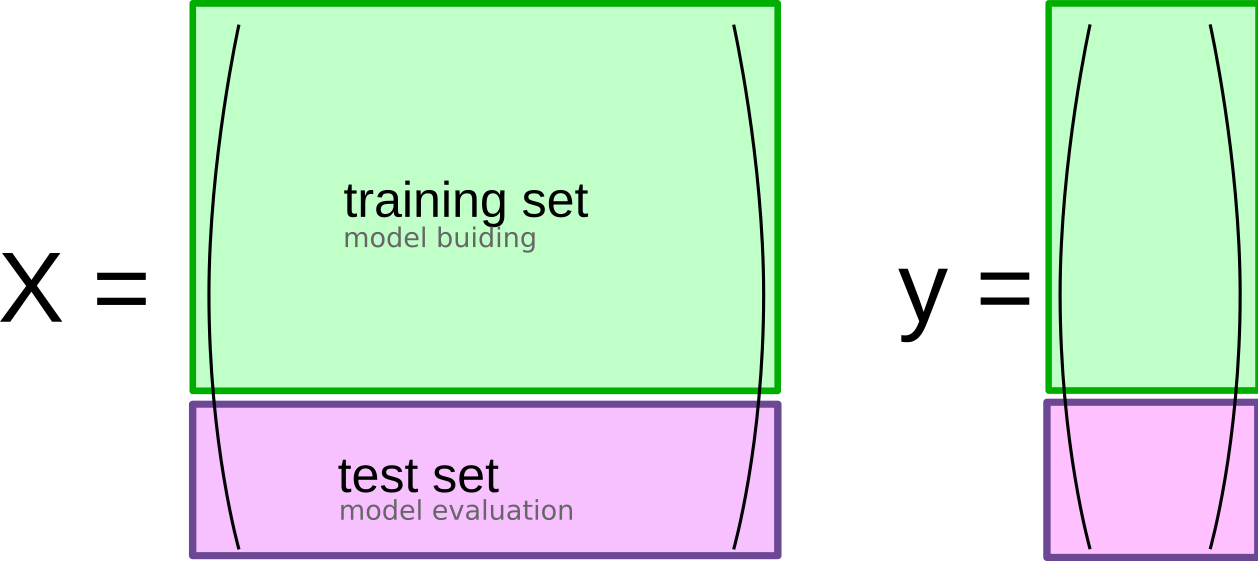
Train-Test Split (usually 75/25)
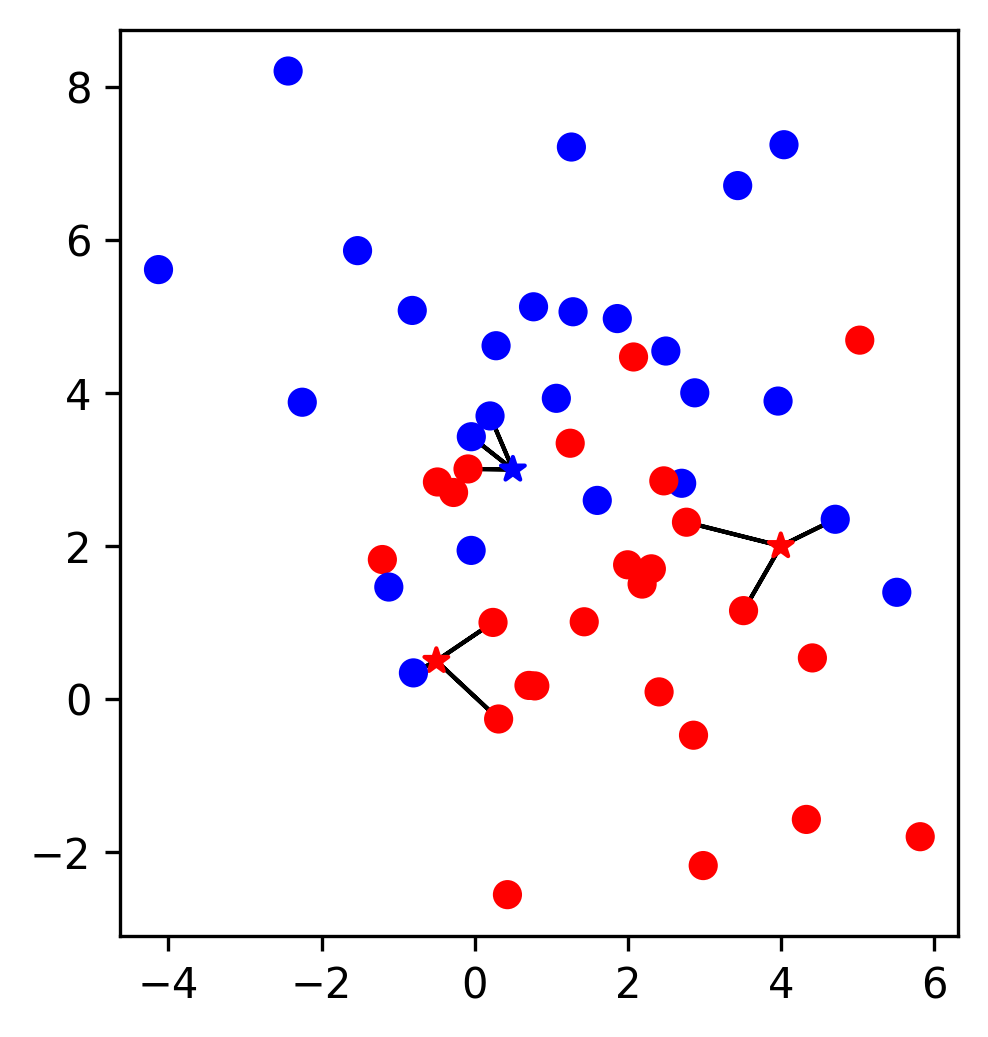
Example - K Nearest Neighbors (KNN)
- With a trained KNN, a new data point is classified by the majority label of its k nearest neighbours in the training set
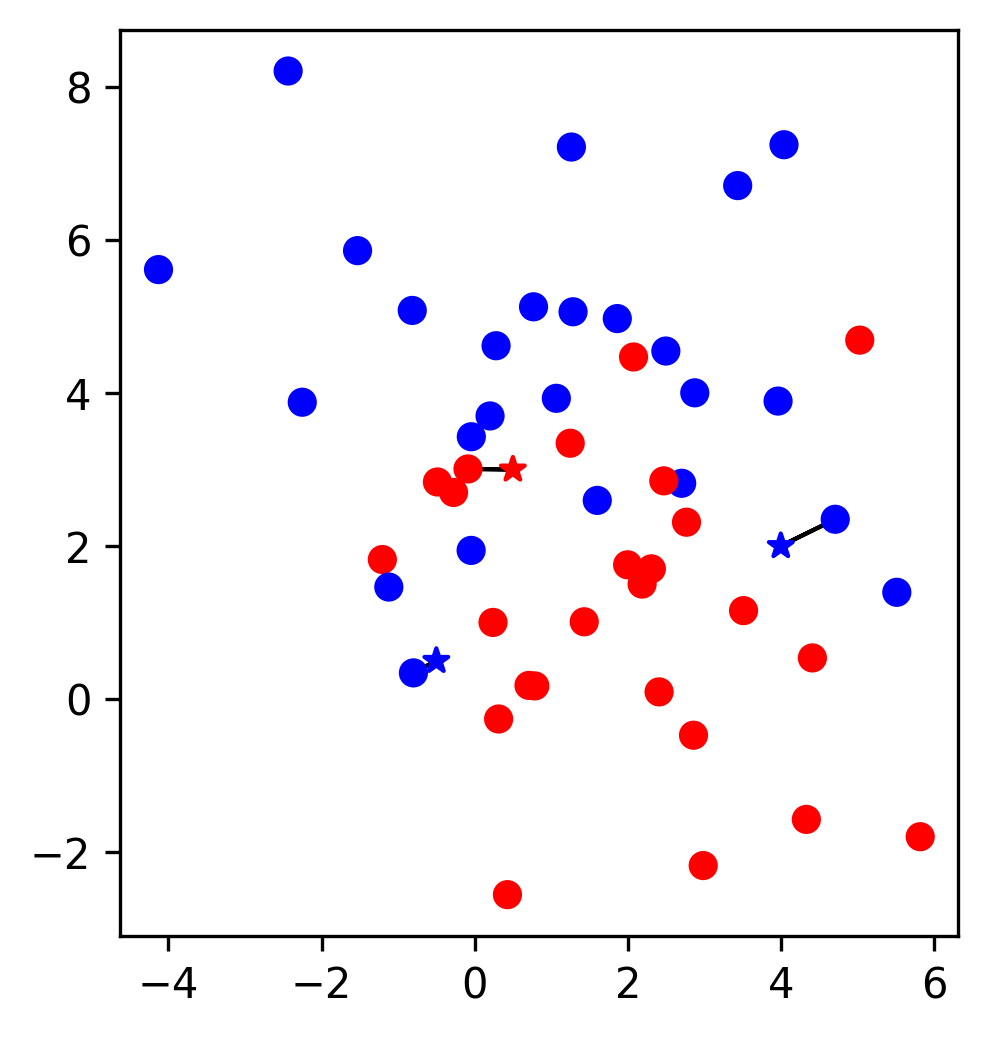
KNN (k=1)
- When k=1, a new data point is labelled by its nearest neighbour
- Sensitive/Complex decision boundary
KNN (k=3)
- The label of a new data point is the majority vote of its 3 nearest neighbours
- The decision boundary is less complex and less sensitive to training data
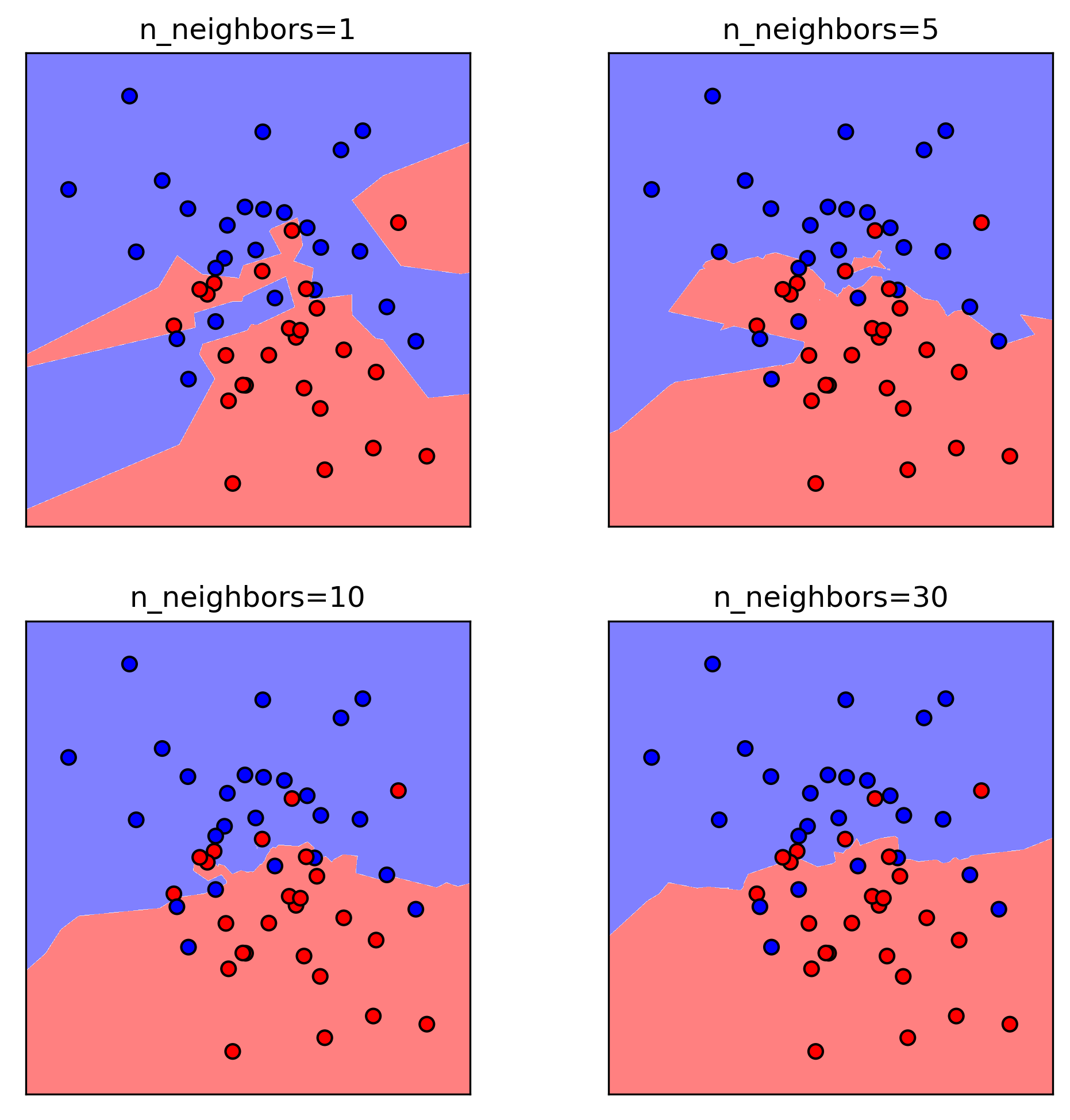
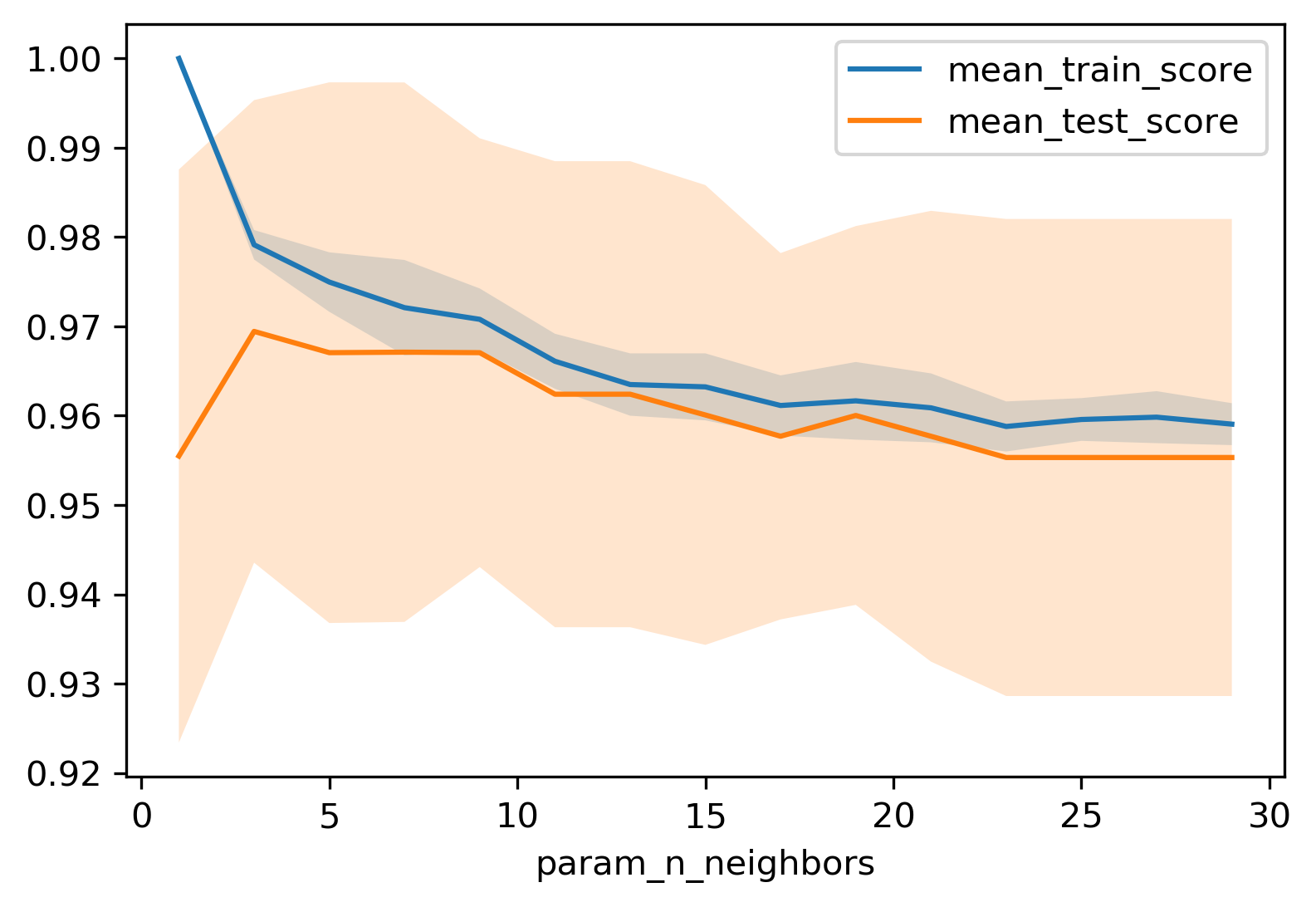
Influence of n_neighbors
- Trade-off between complexity and generalisation
- Smaller k → complex boundary, higher model complexity, lower generalisation
Model Complexity
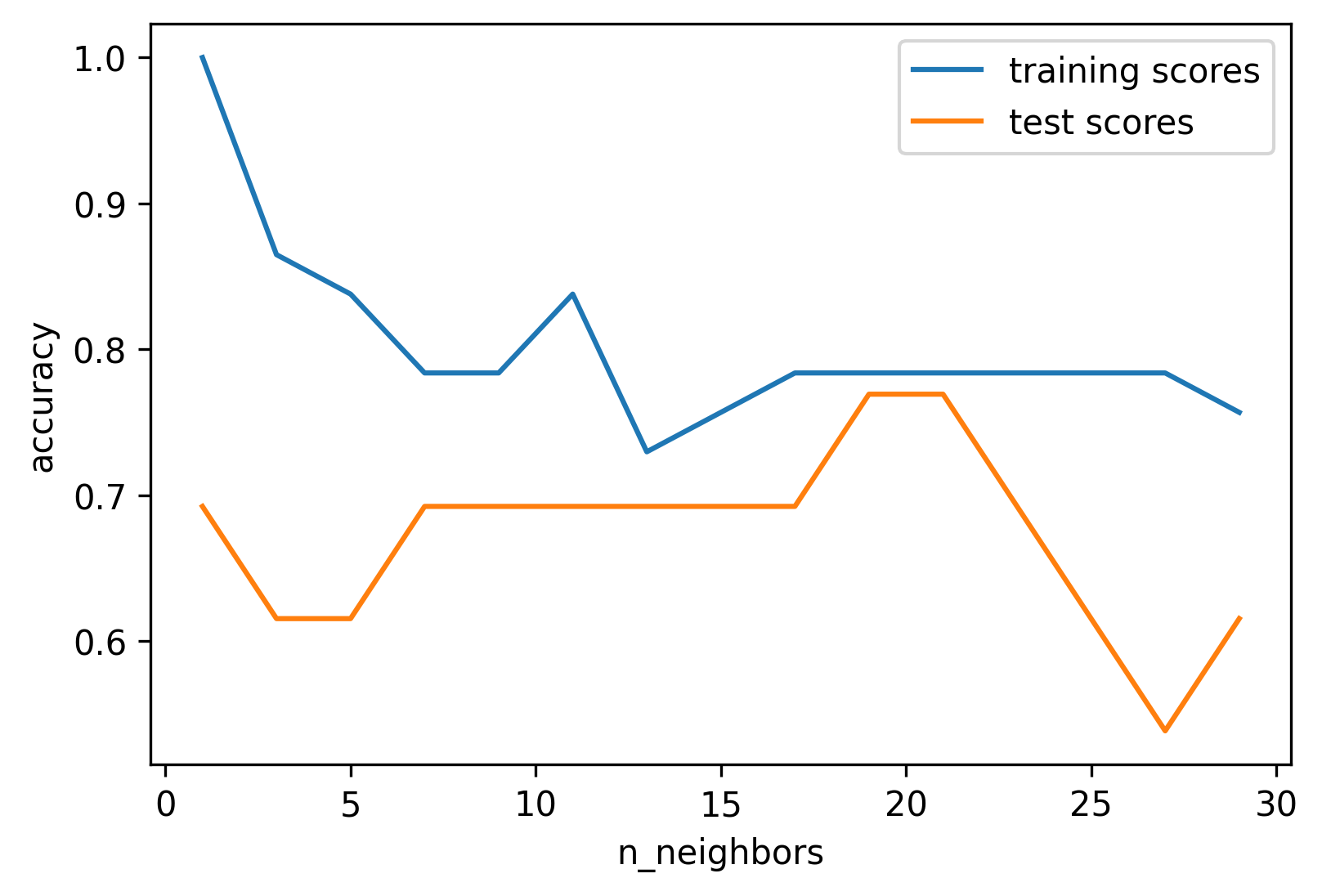
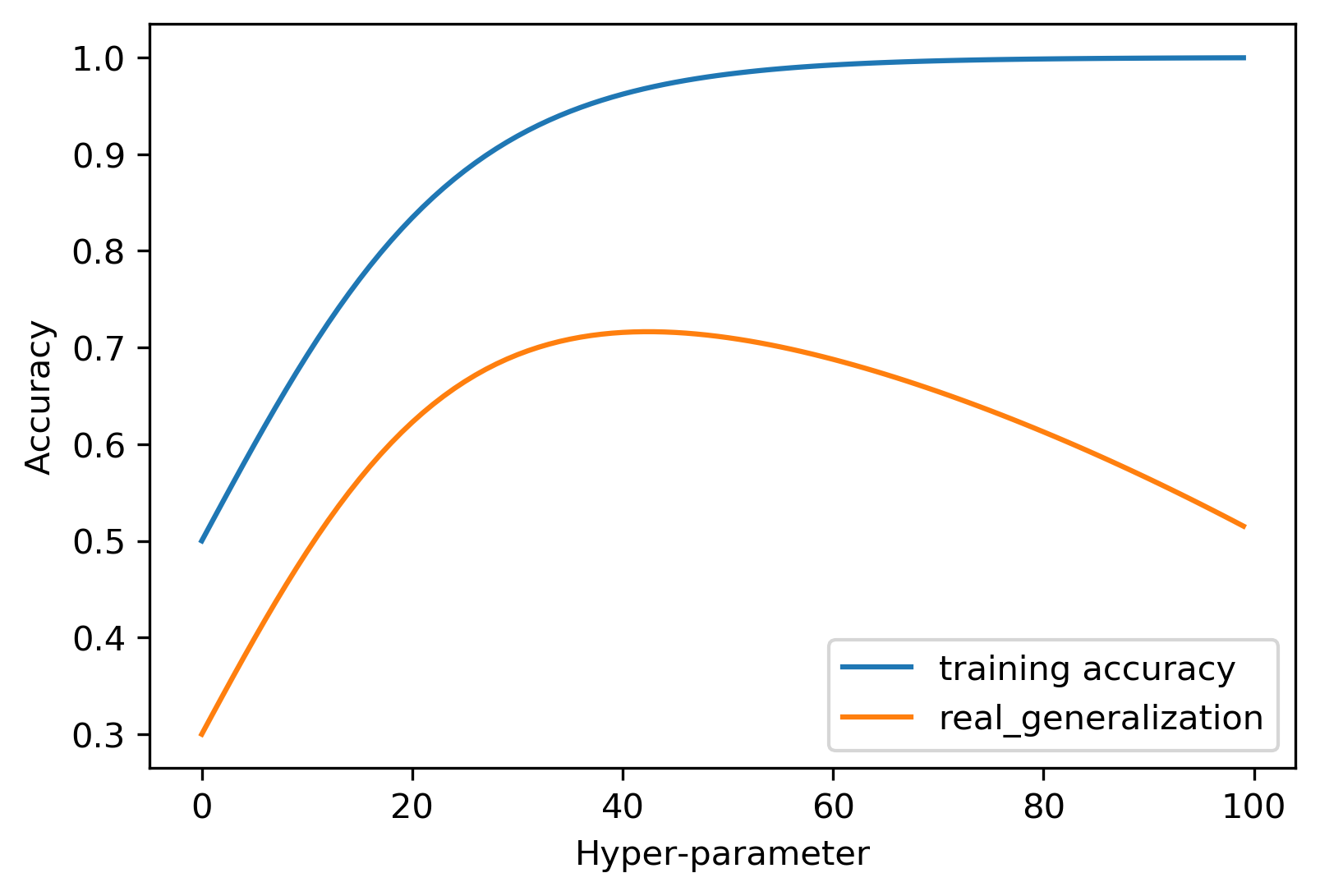
- Train score ↓ as k increases
- Test score peaks at intermediate k
Overfitting vs Underfitting
- Performance on training data generally increases with model complexity
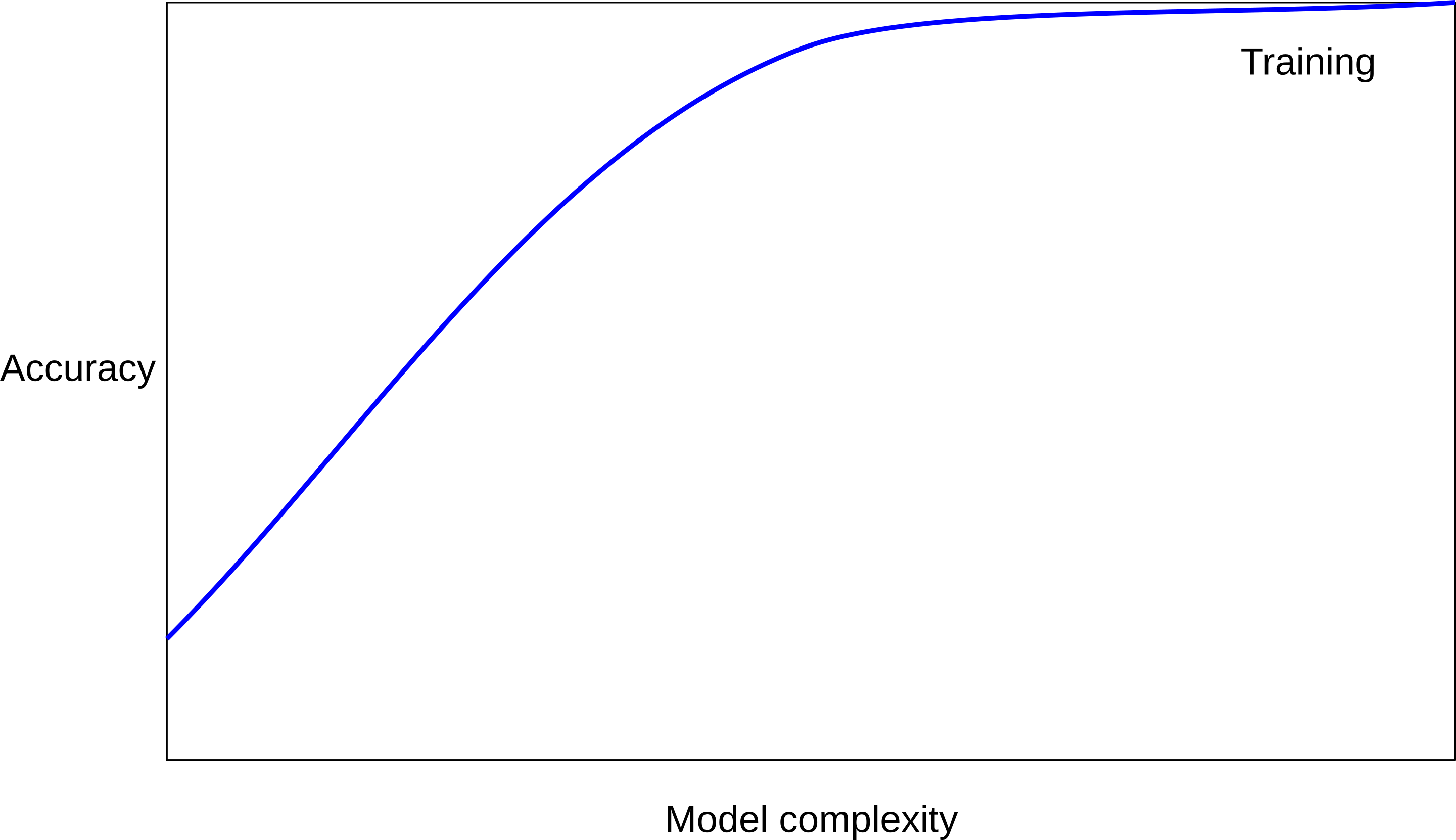
Overfitting vs Underfitting
- Performance on testing data firstly increases with model complexity, and then decreases due to overfitting on training data
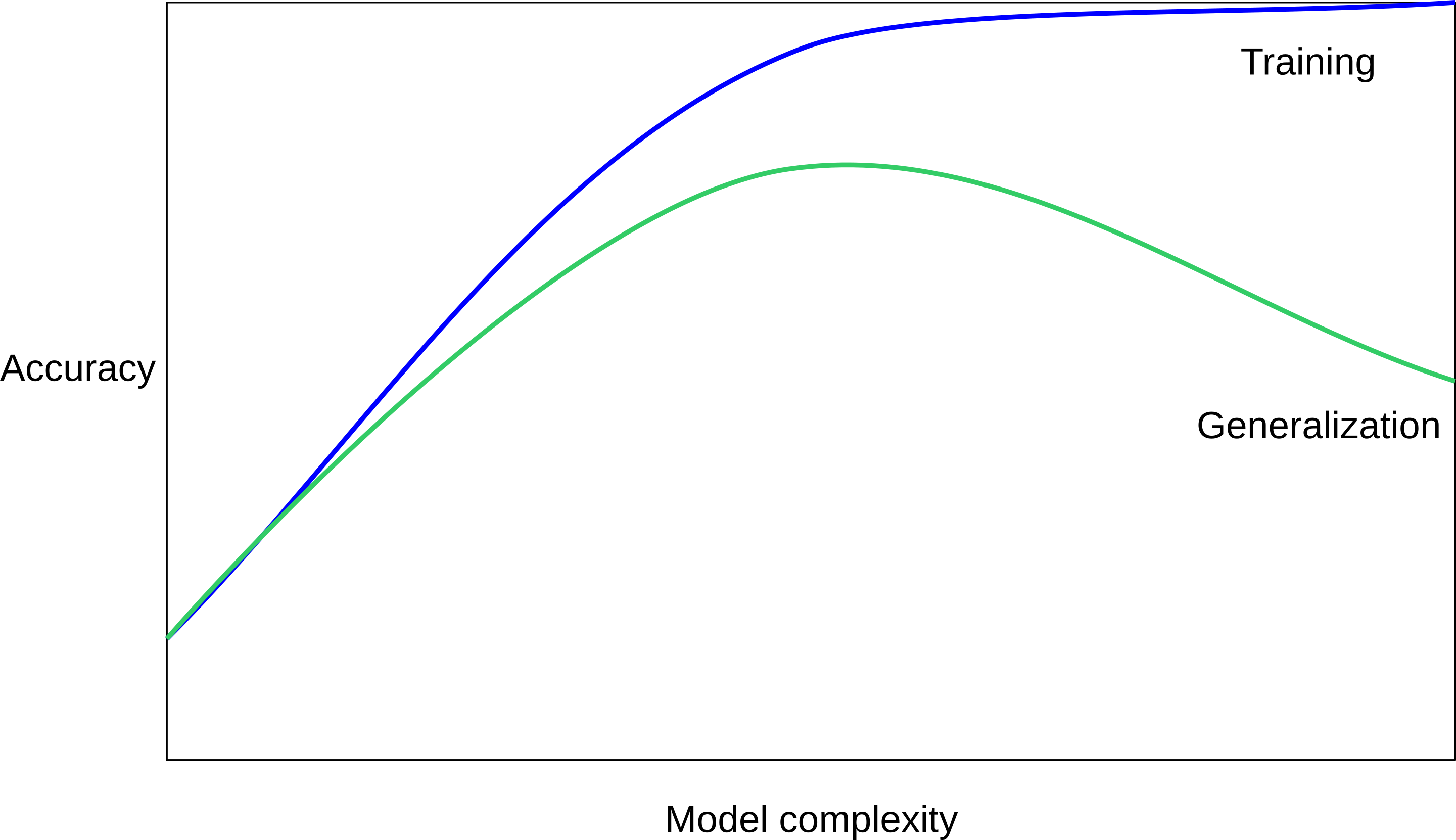
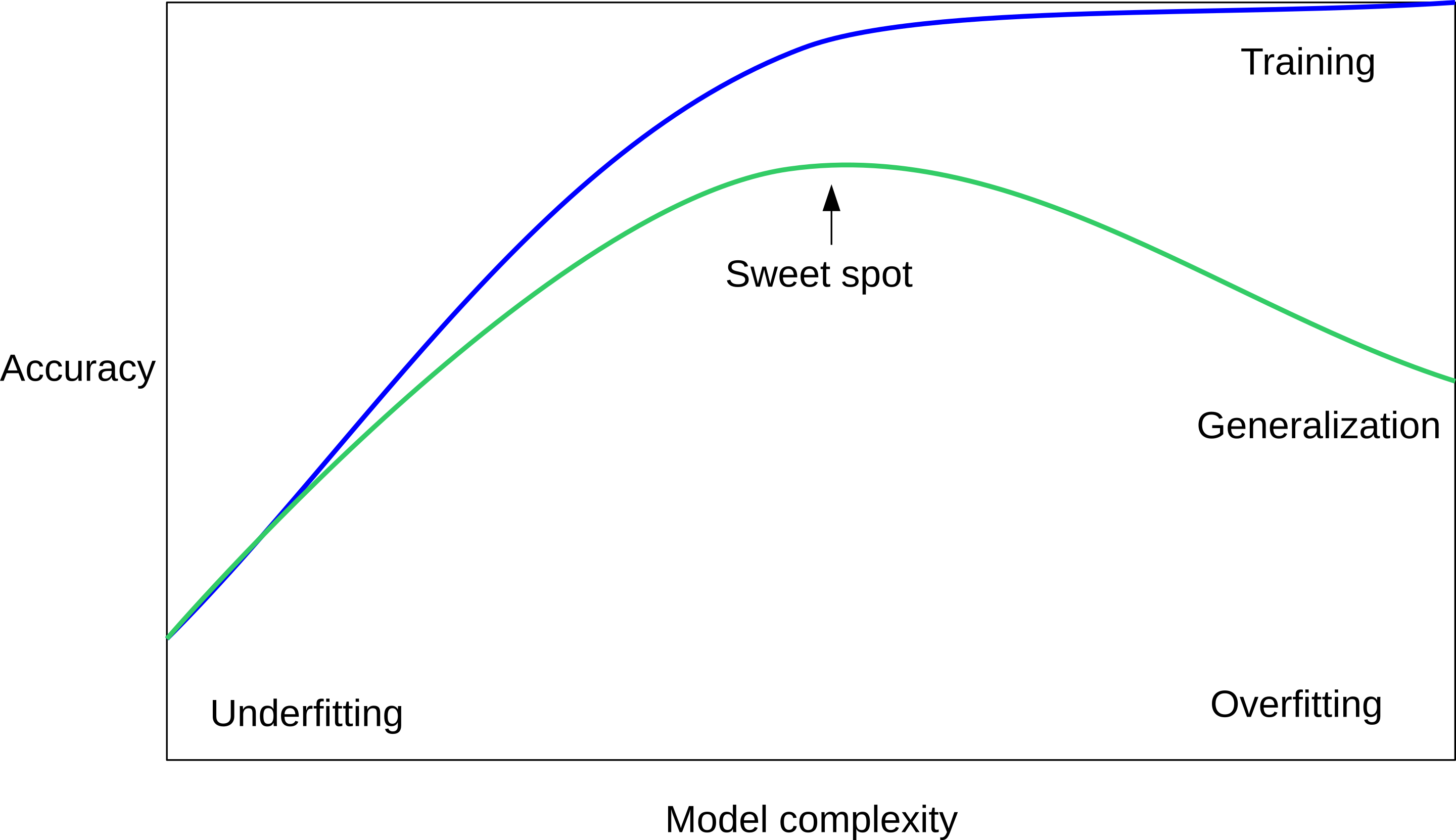
Overfitting vs Underfitting
- The optimal hyperparameter achieves balance between underfitting and overfitting
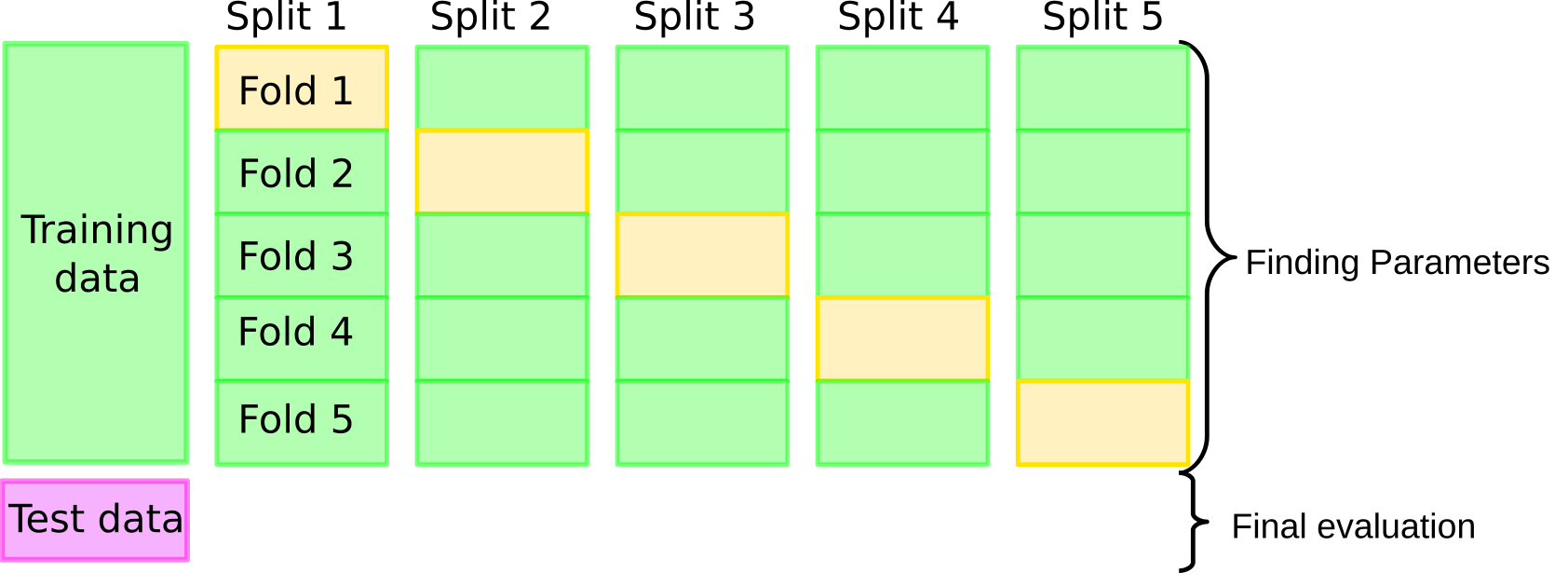
Idea
- Training → Validation (hyperparams tuning) → Test (final eval)
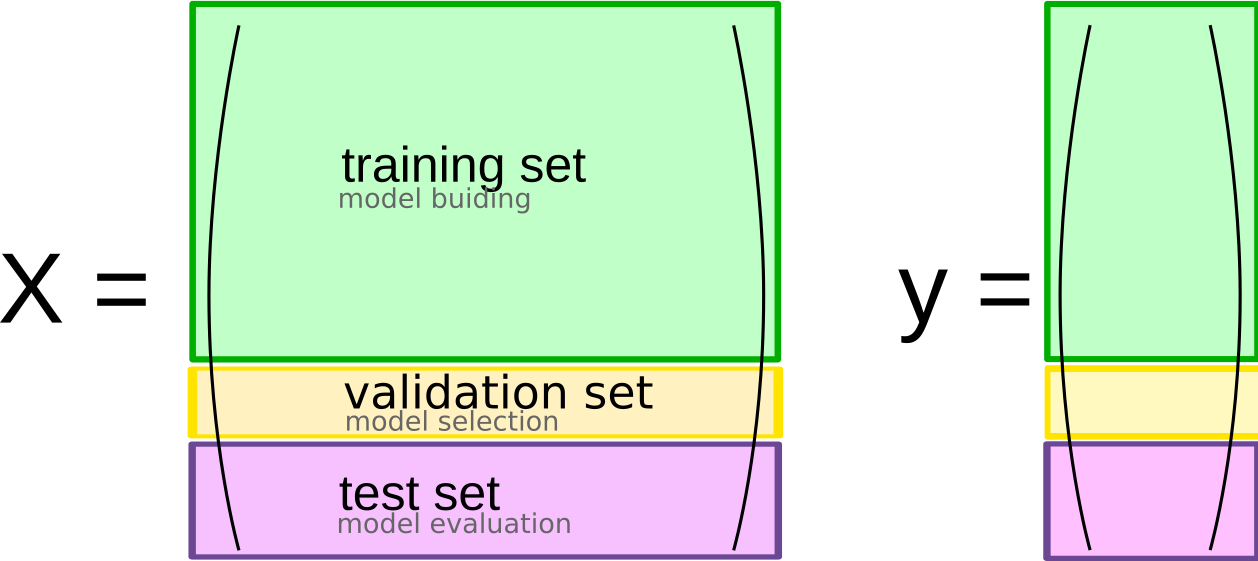
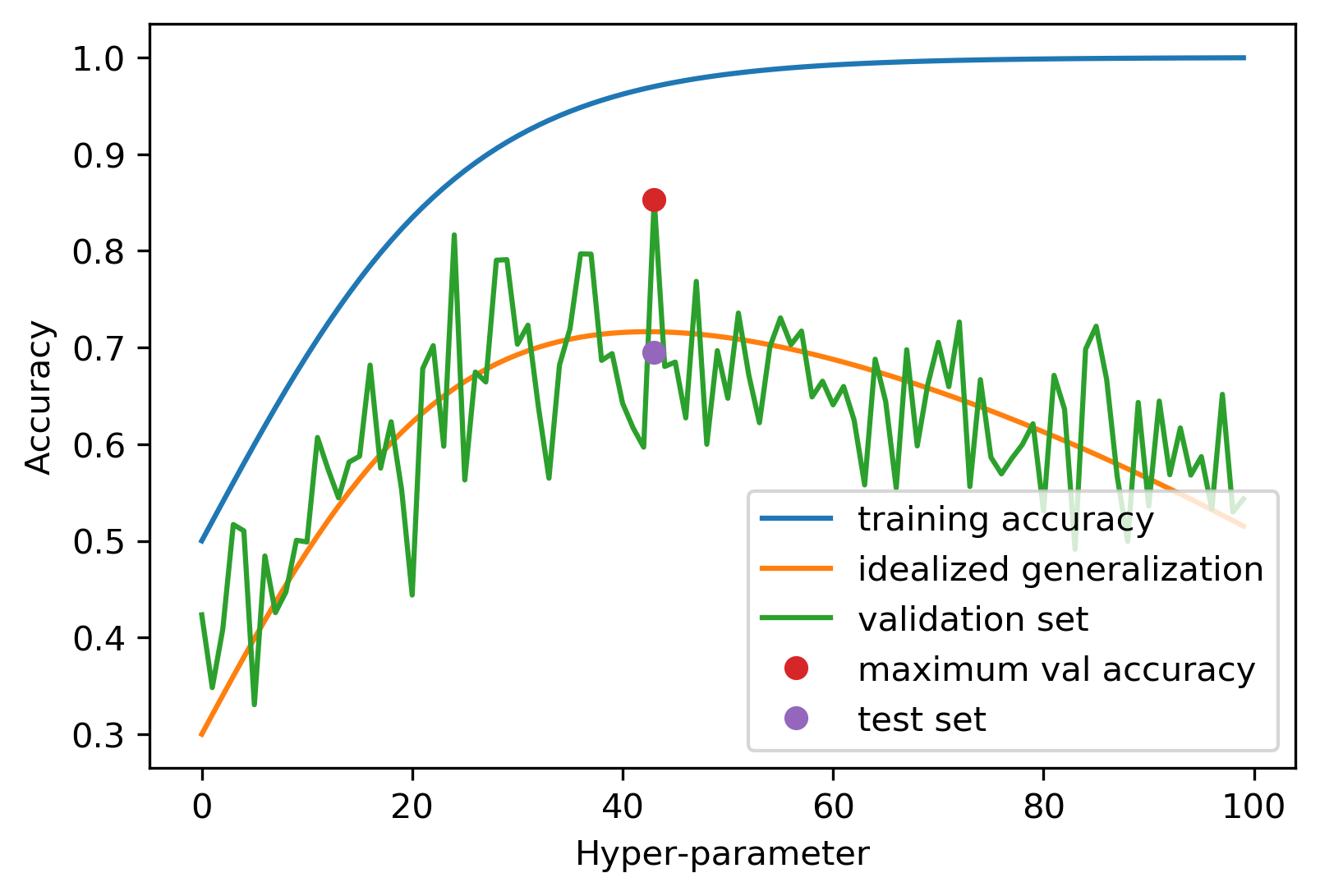
Why using three-hold split?
- It separates hyperparameter tuning (using validation set) and final evaluation (using test set)
- Ensures test set is only used for final evaluation
- Interesting reading: Preventing Overfitting in cross-validation - Ng 1997
Overfitting the Validation Set
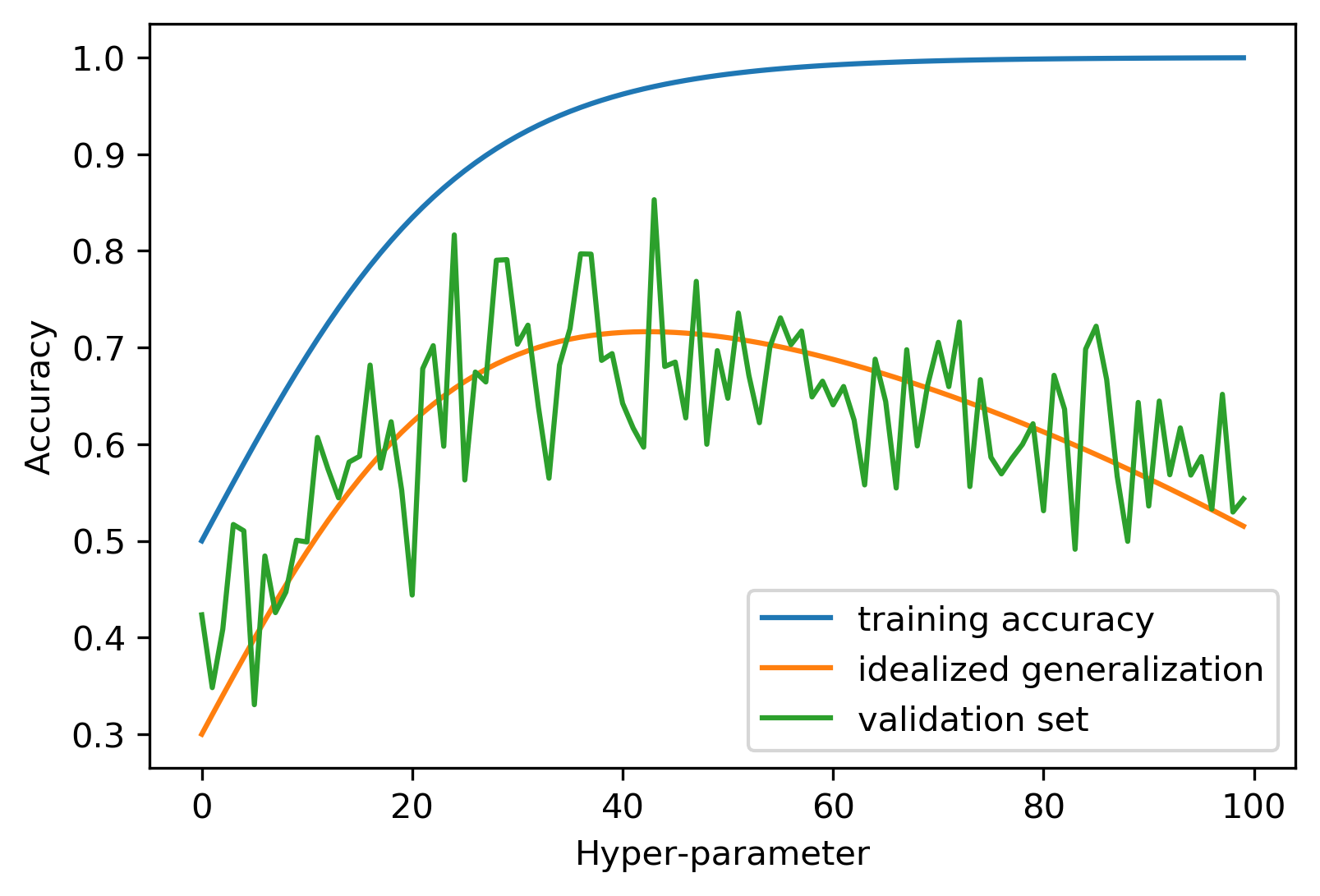
Overfitting the Validation Set
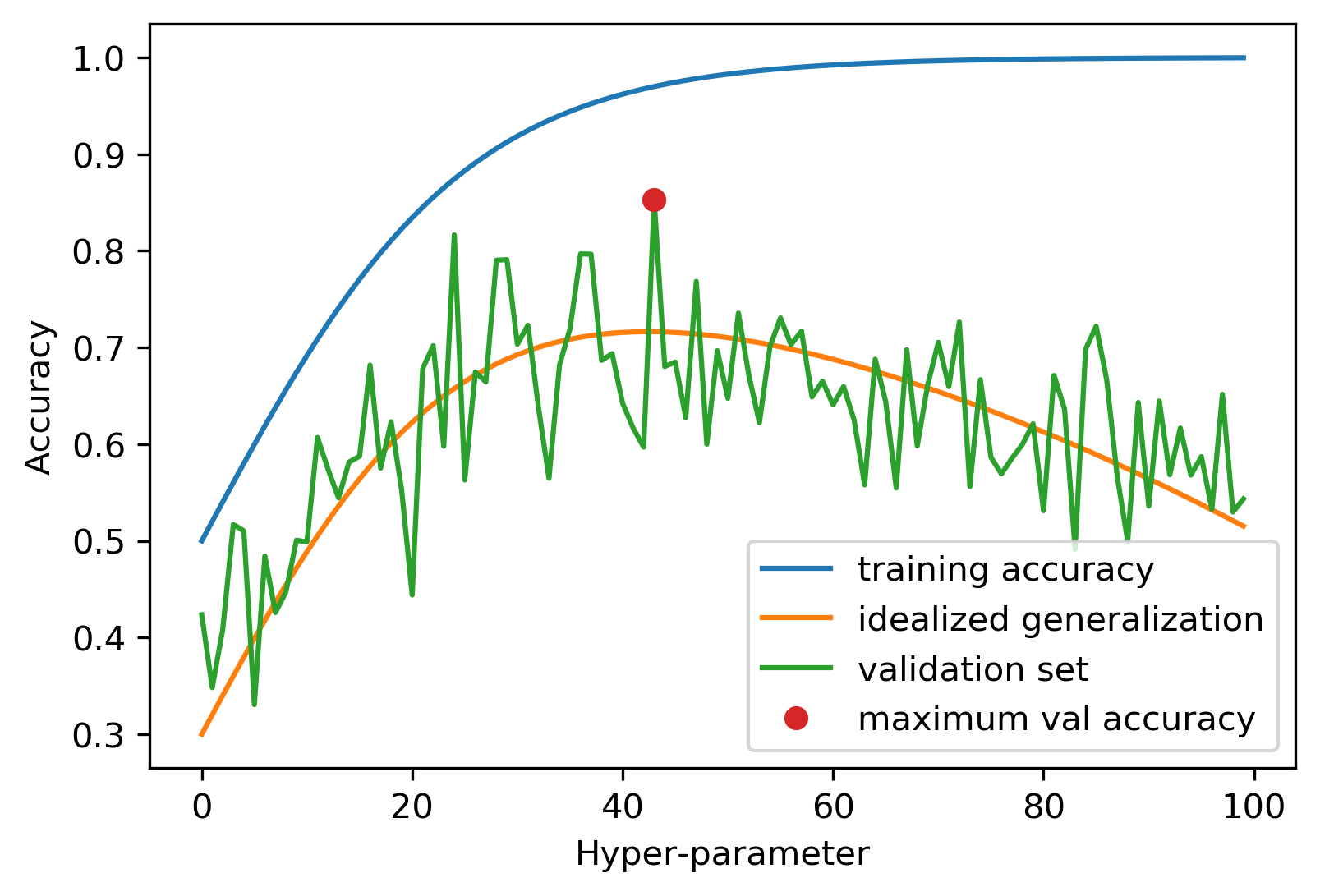
Overfitting the Validation Set
Idea
Grid-Search Workflow
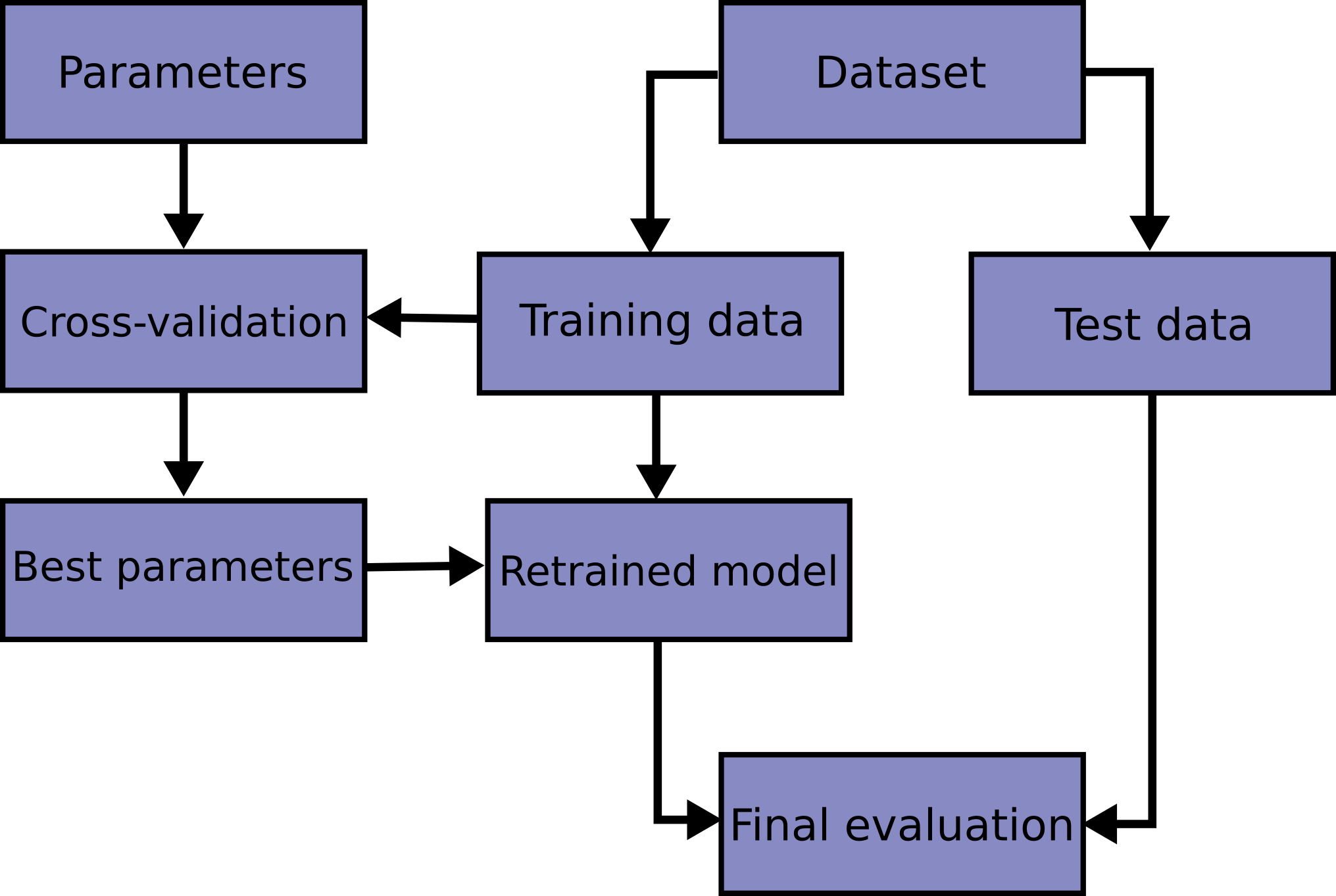
n_neighbors Search Results
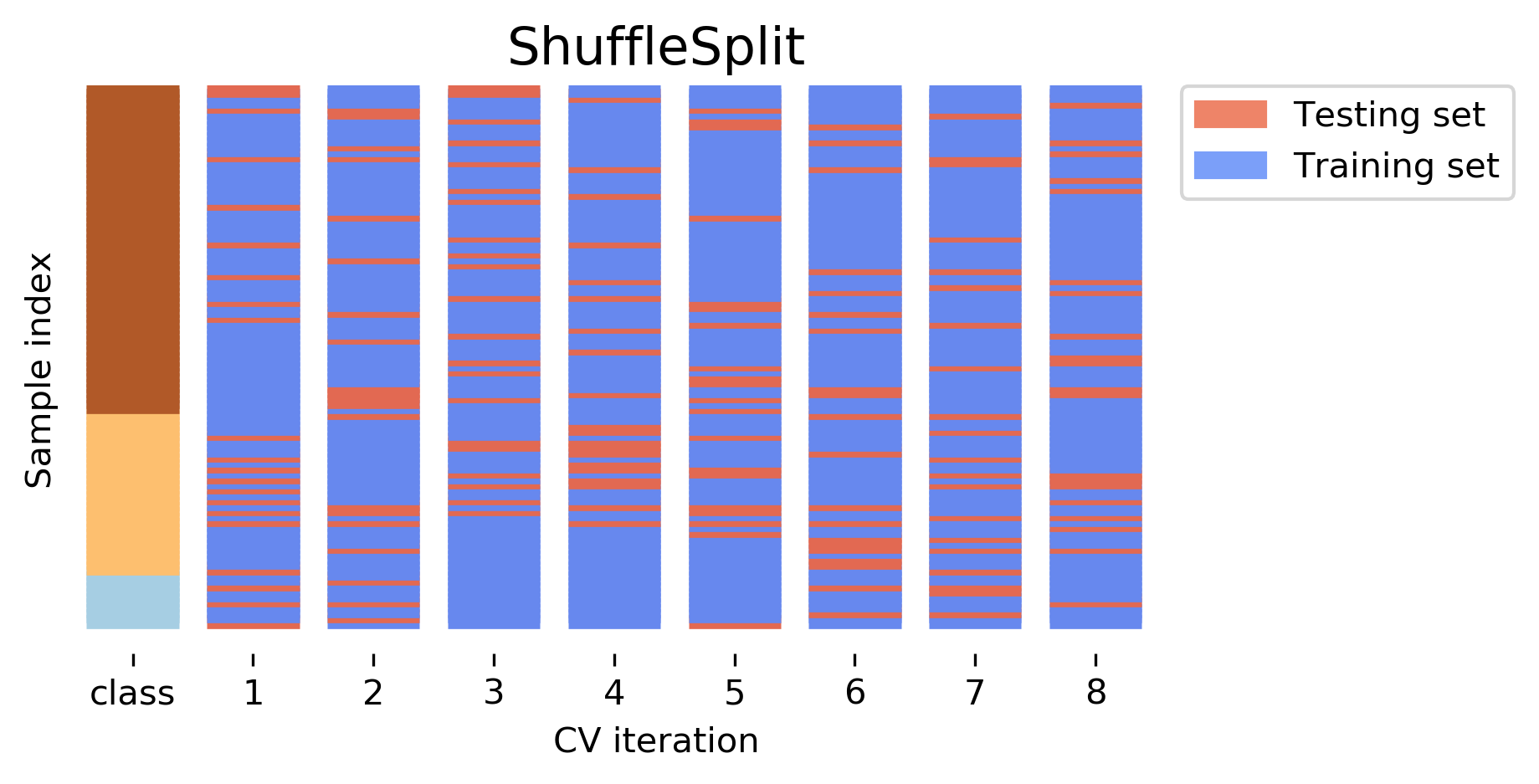
Should data be shuffled in CV?
- In sklearn,
KFolddoes not shuffle data and is subject to data ordering - Recommend to set
shuffle=TrueinKFold, or usingShuffleSplitfunction
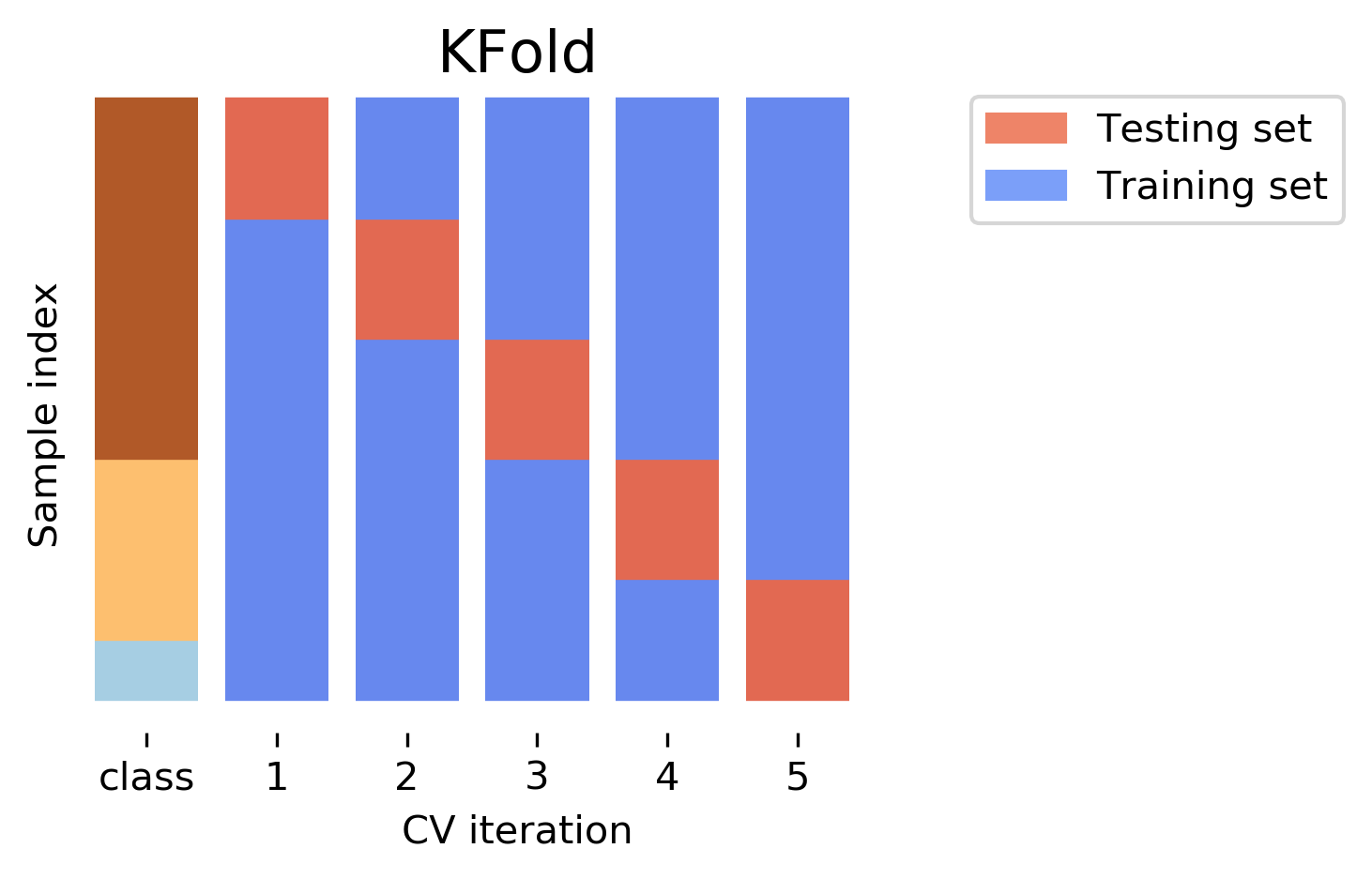
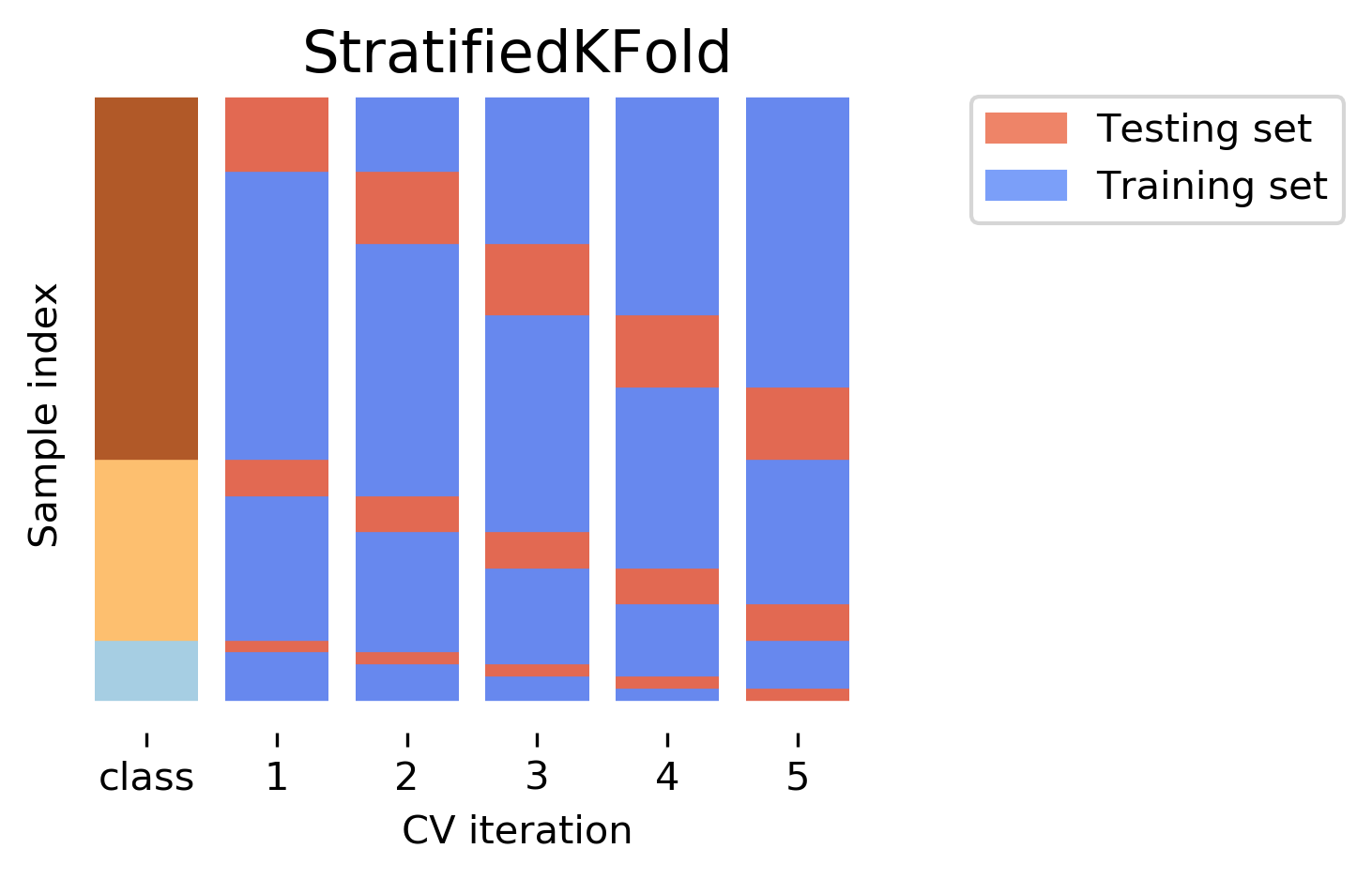
Stratified CV
- Standard CV leads to folds with different class distributions
Stratified CV: for multiclass classification or imbalanced data
- Preserve class distribution in each fold
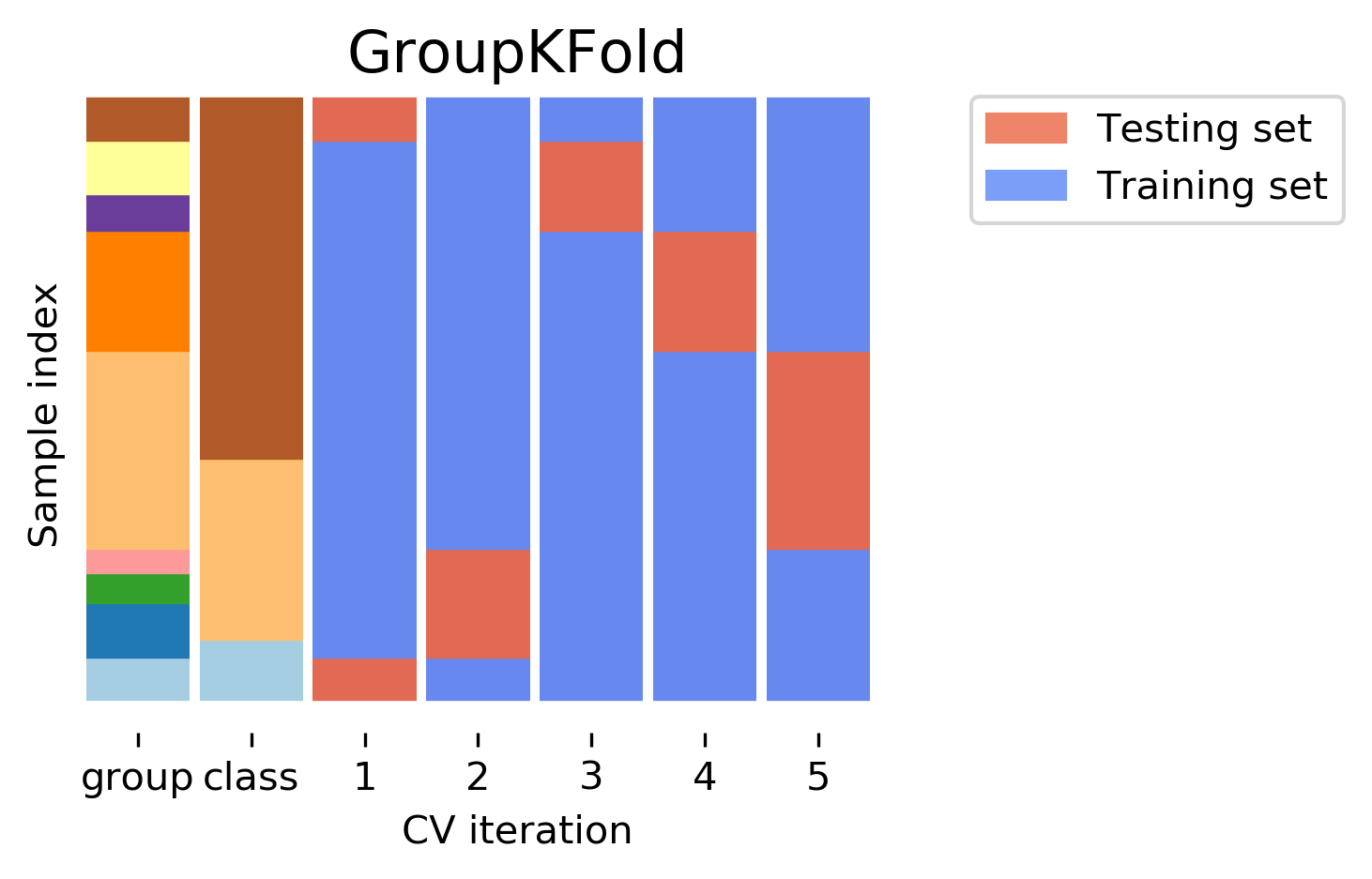
Scenario 2: To predict new data from unknown cities (not i.i.d.)
- GroupKFold should be used; ensure each group is contained in exactly one fold (either train or test)
- Data from 9 cities; 5-fold CV; GroupKFold as below.
CV for time series?
- Data is collected over time and is not i.i.d.; future data depends on past data
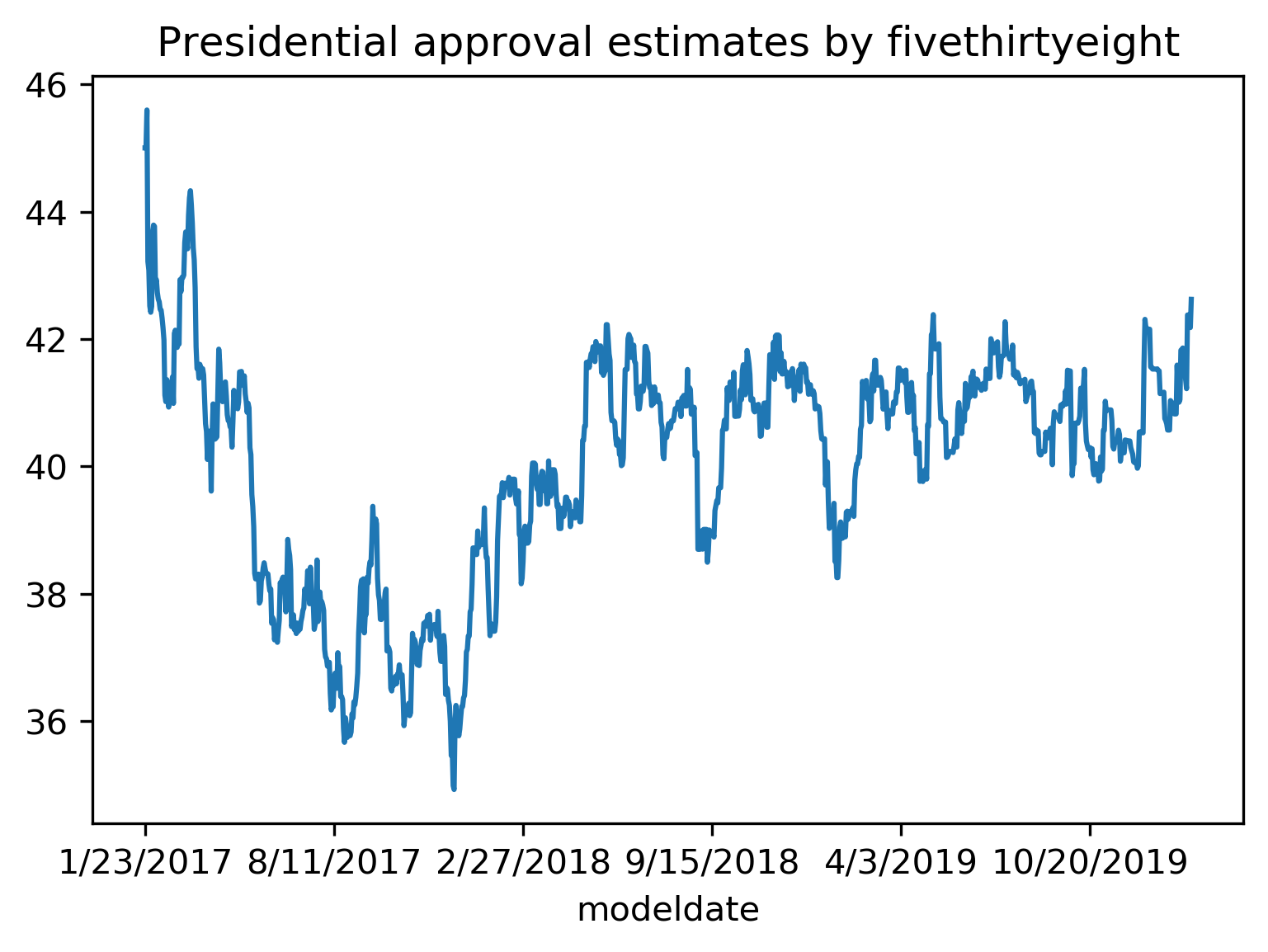
Standard train-test split or CV not suitable for time series
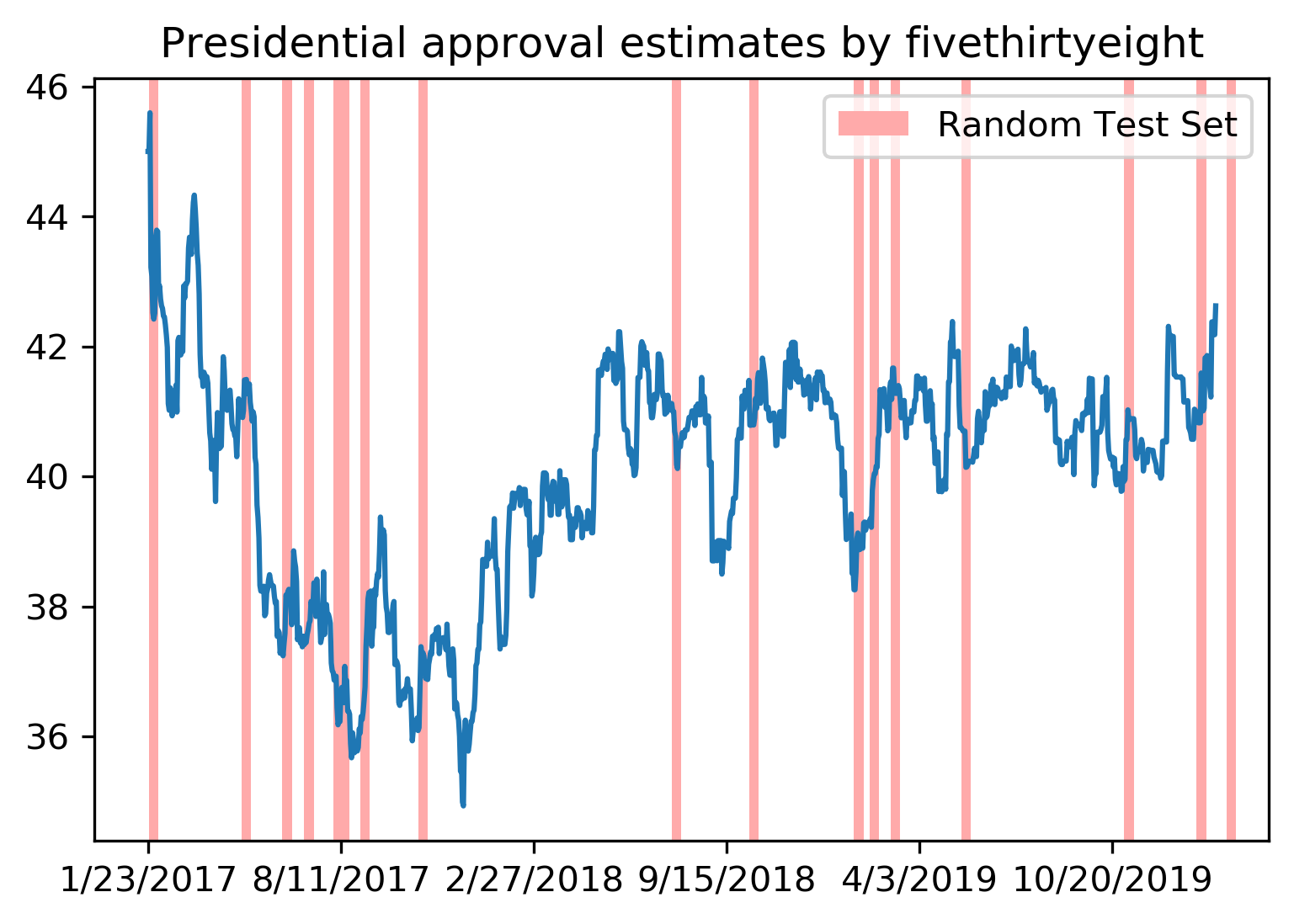
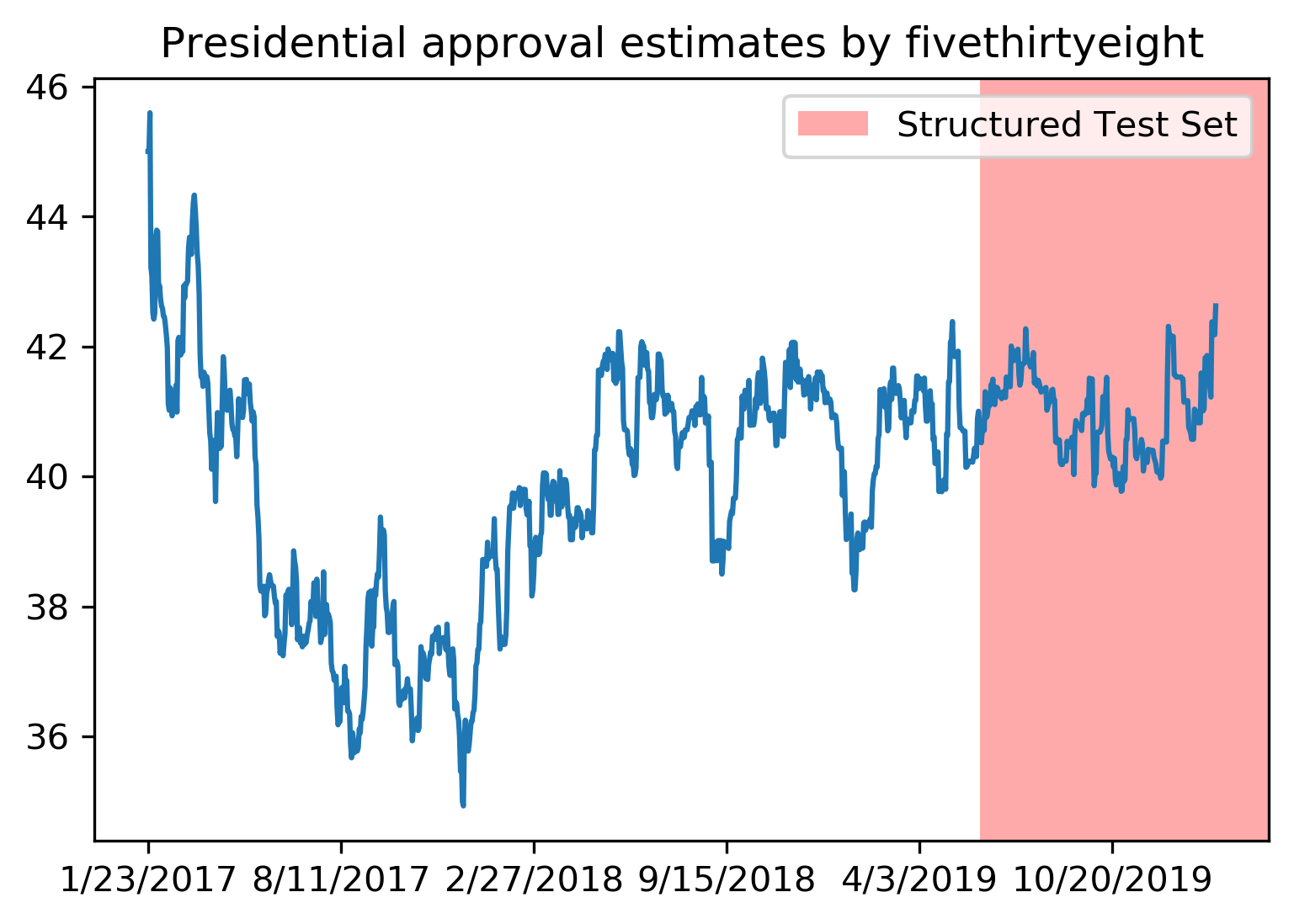
Train-Test Split for Time Series
- Using past data to train, future data to test
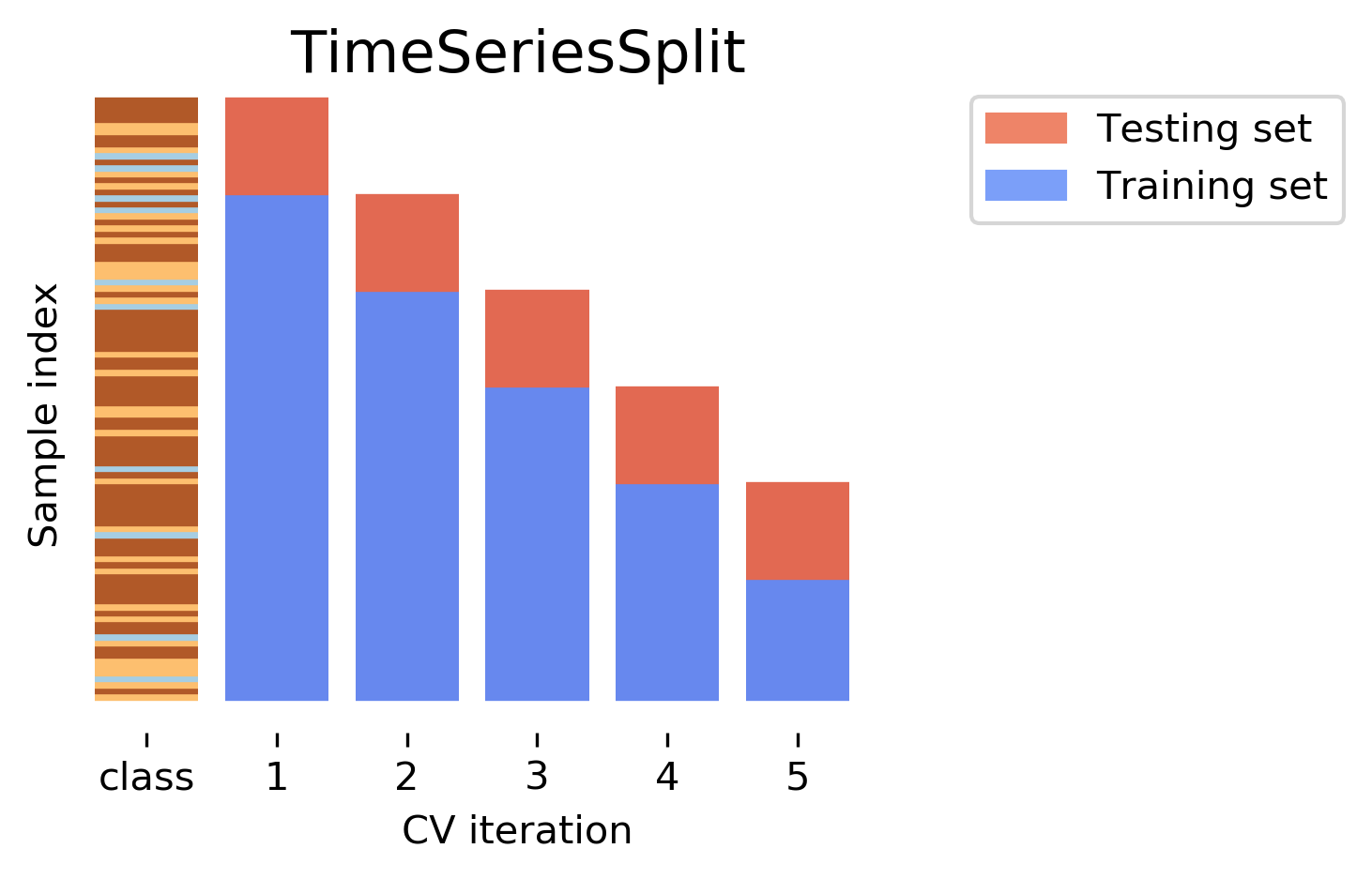
TimeSeriesSplit
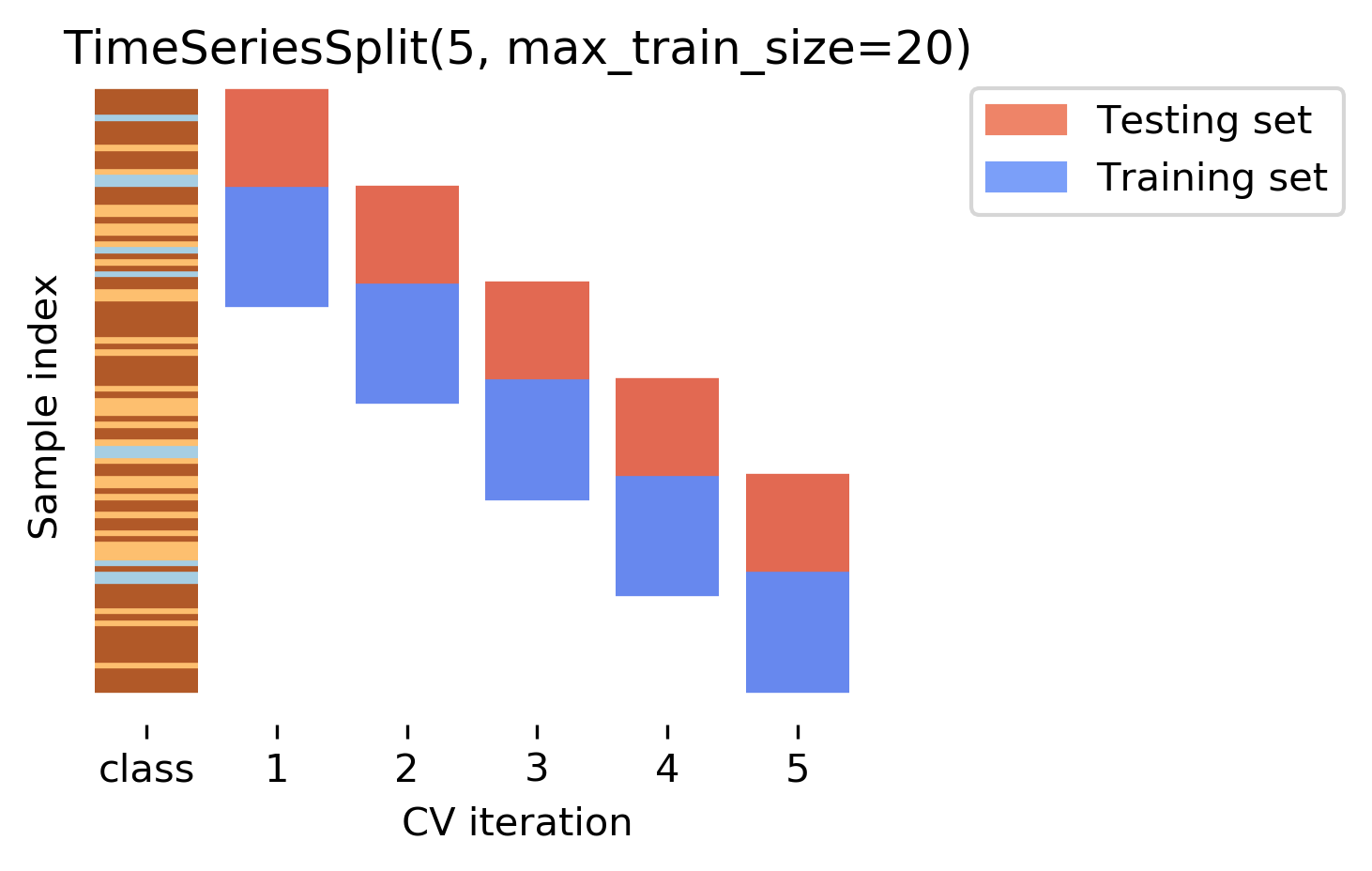
Time Series CV