Introduction to machine learning
- huanfa.chen@ucl.ac.uk
13 December 2025
ML as subset of AI
- Machine learning (decision tree, random forest, k-means, etc.)
- Deep learning (deep neural networks)
- Other AI tools: graphical models, symbolic AI
- Note: we don’t distinguish ML/DL and consider NN as part of ML
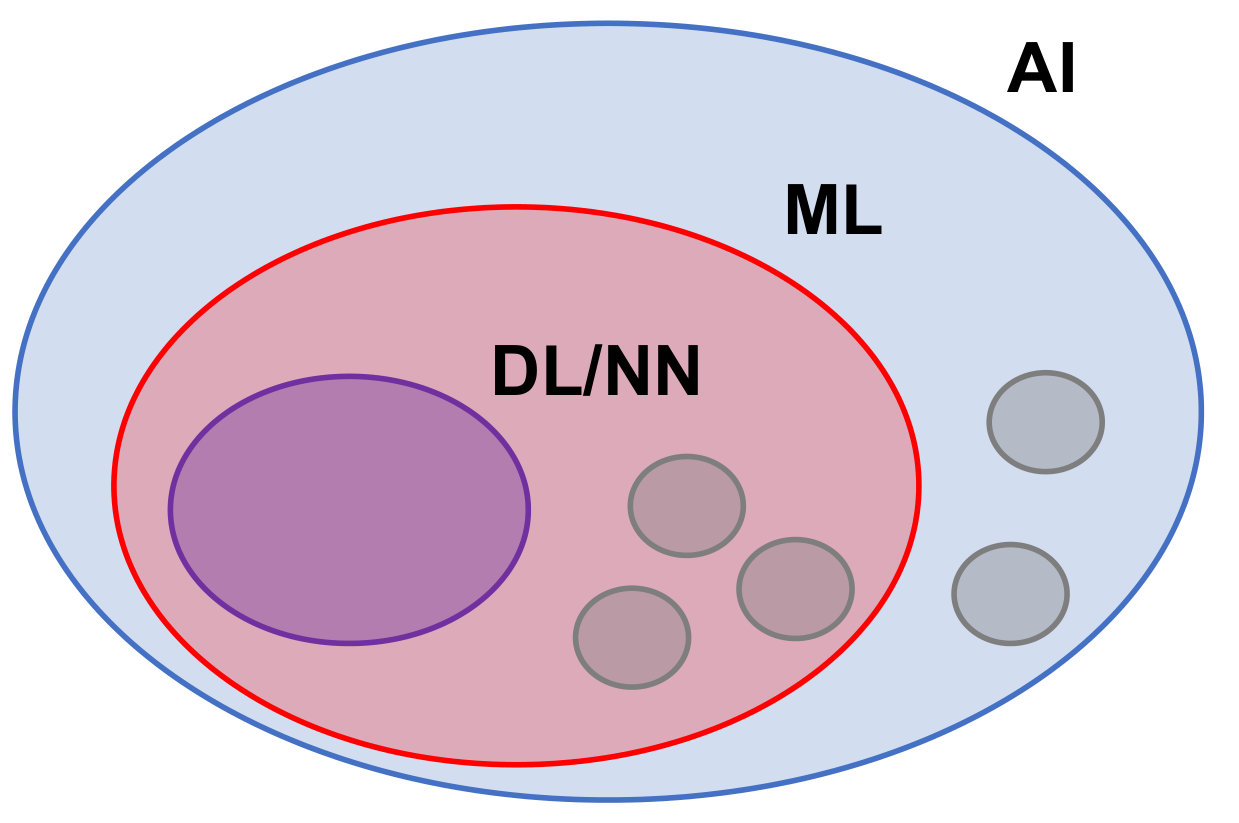
Image Credit: Lecture slide (ML is a subset of AI)Examples: Facebook
- Machine learning in news feed ranking
- Content selection and targeting
- Ads and recommendations
Examples: Facebook (cont.)
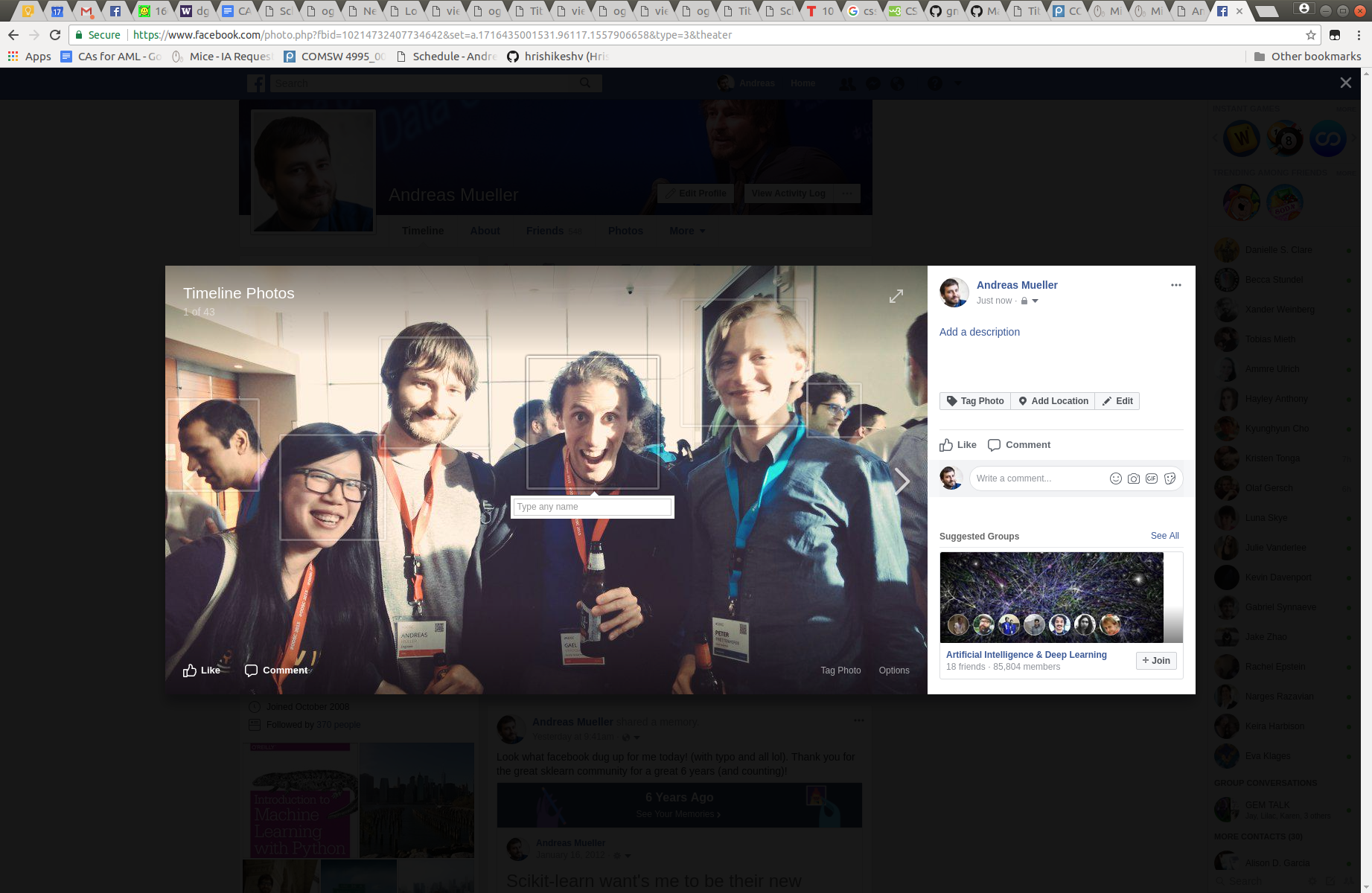
- Face detection and recognition
- Photo organization
Examples: Facebook (cont.)
- Photo selection and layout
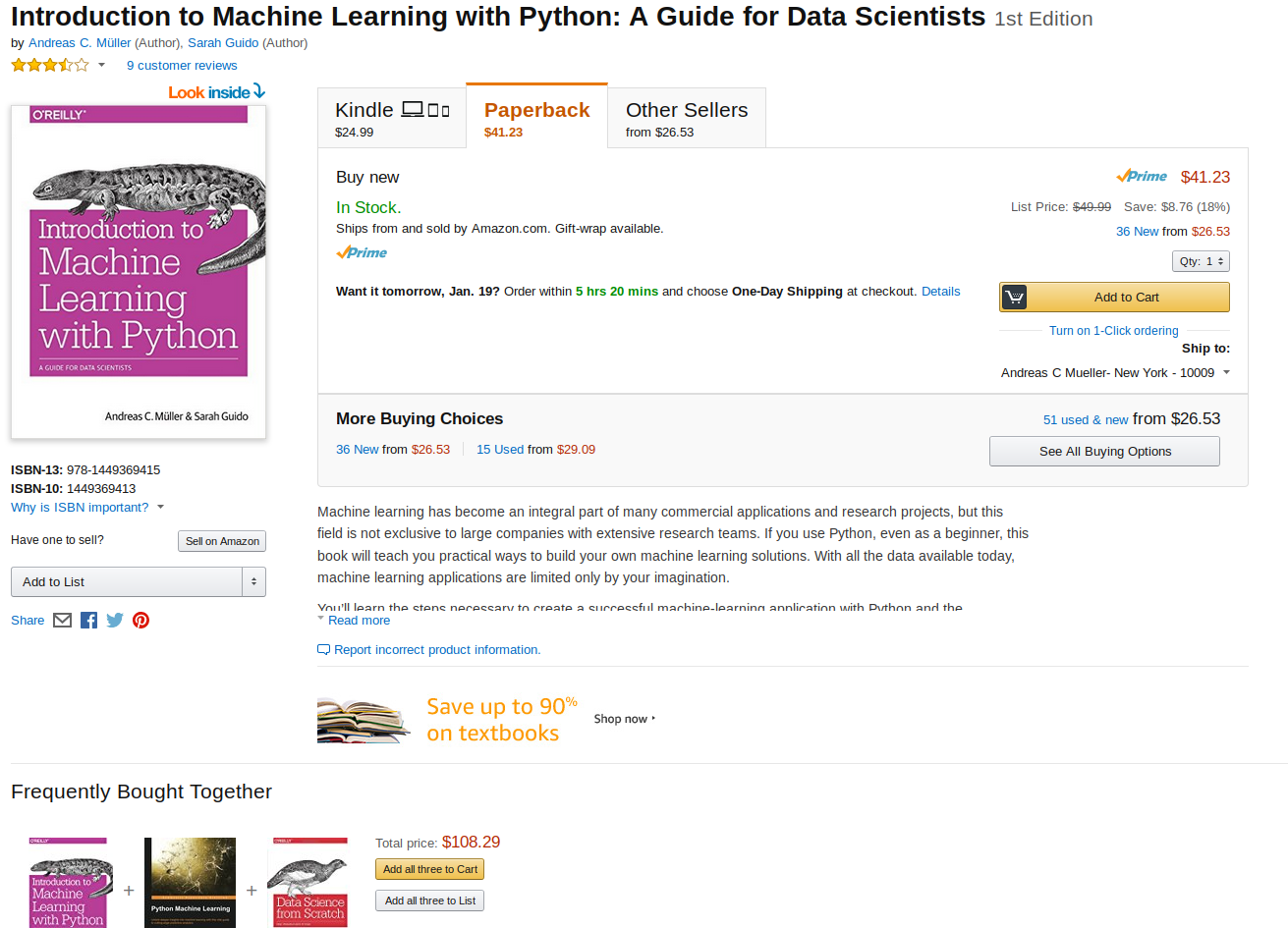
Examples: Amazon
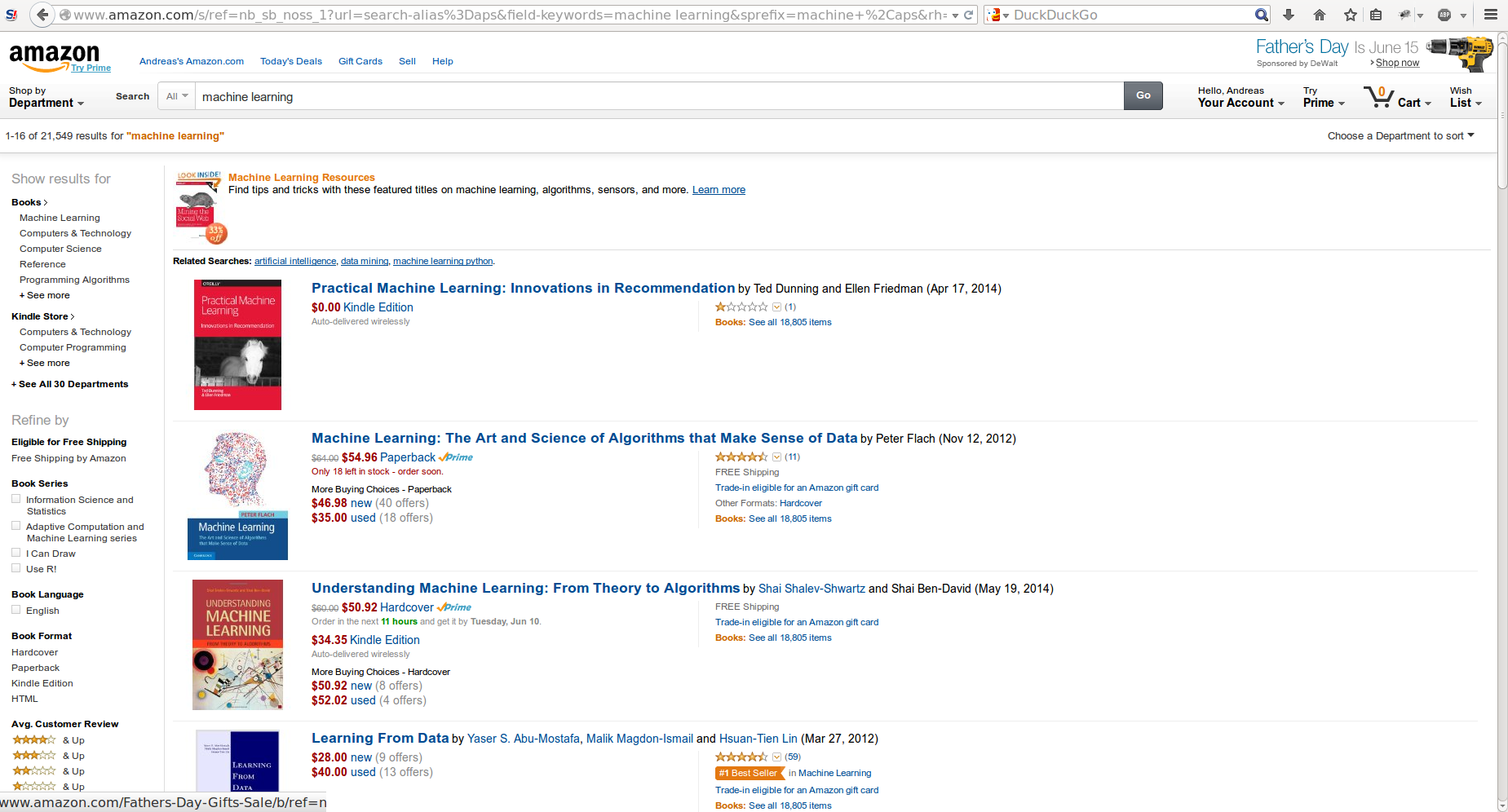
- Product ranking
- Personalised recommendations
- Ads selection
Examples: Amazon (cont.)
- Seller selection
- Default choices
- Related products
Science Applications
- Personalised cancer treatment
- Medical diagnosis
- Drug discovery
- Higgs boson discovery
- Exoplanet detection

Reinforcement Learning
- Agent learns to interact with environment
- Goal-directed behavior
- Examples: Alpha Go, self-driving cars


Reinforcement Learning: Explore & Learn

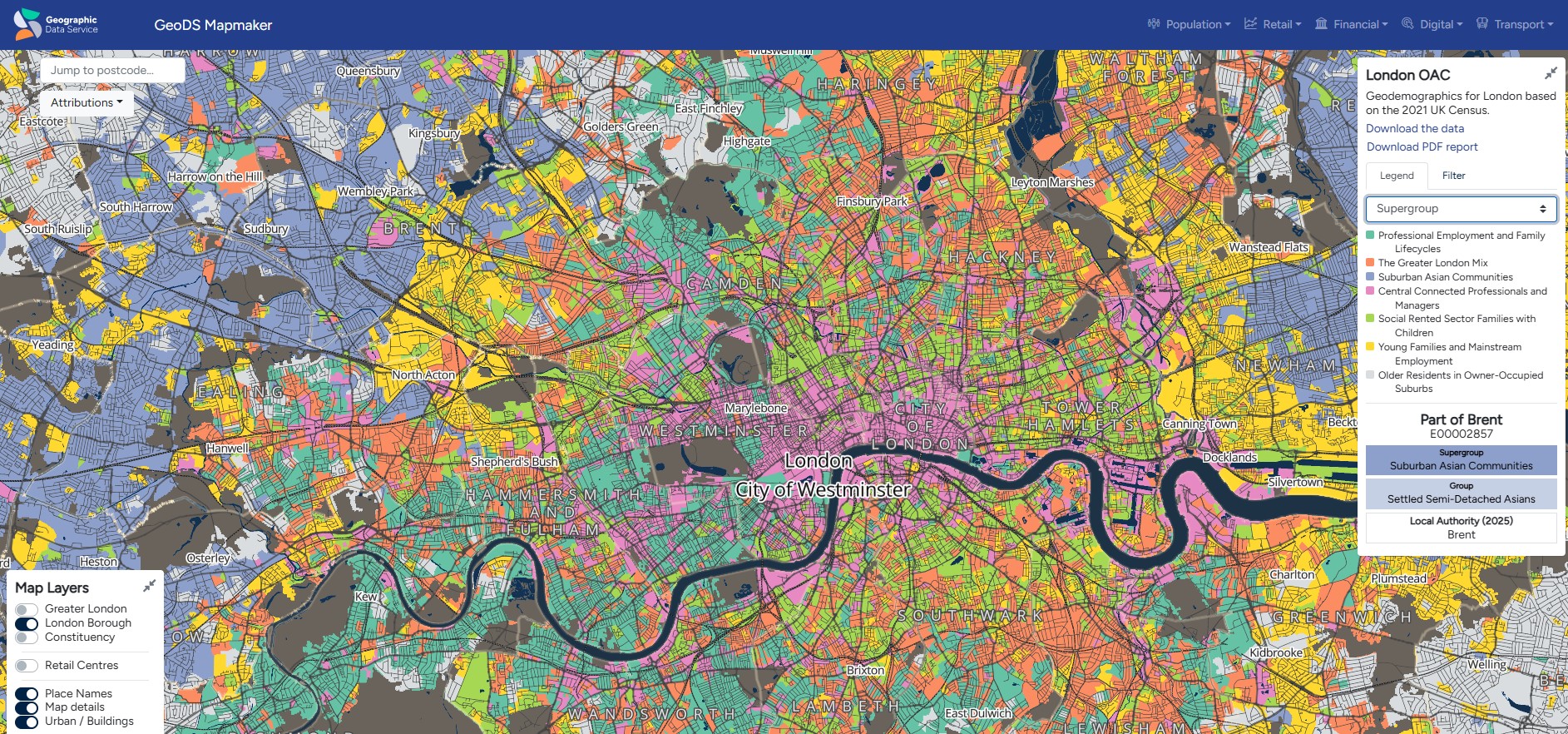
Don’t read a book by its name: classification of neighbourhoods
- Classifications of neighbourhoods (e.g. London output area classification) that are actually clustering
Don’t read a book by its name: anomaly detection
- Anomaly detection methods can be unsupervised, semi-supervised, or supervised learning

Image Credit: https://pub.towardsai.net/anomaly-detection-a-comprehensive-guide-9d4d7e320242Don’t read a book by its name: forecasting
- Forecasting can be done with lagged features (via supervised learning), or with time series data (via time series analysis), or both
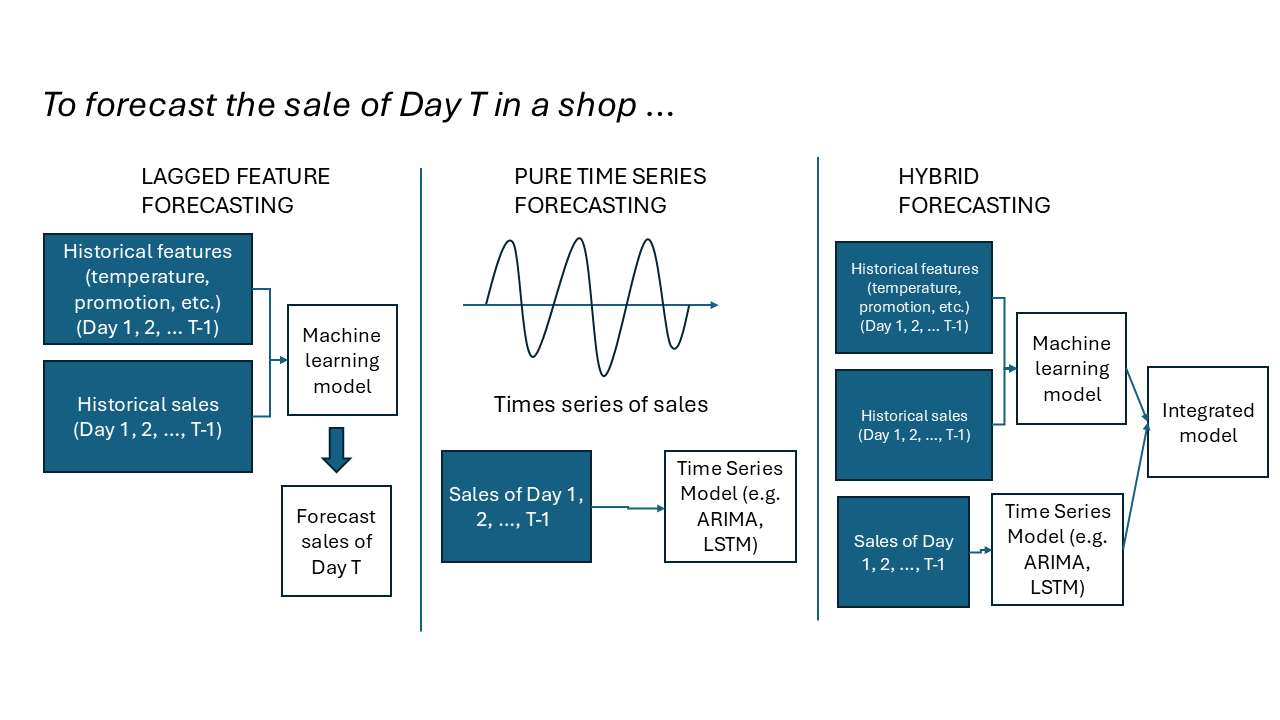
Image Credit: gemini.comWhat does LLM belong to?
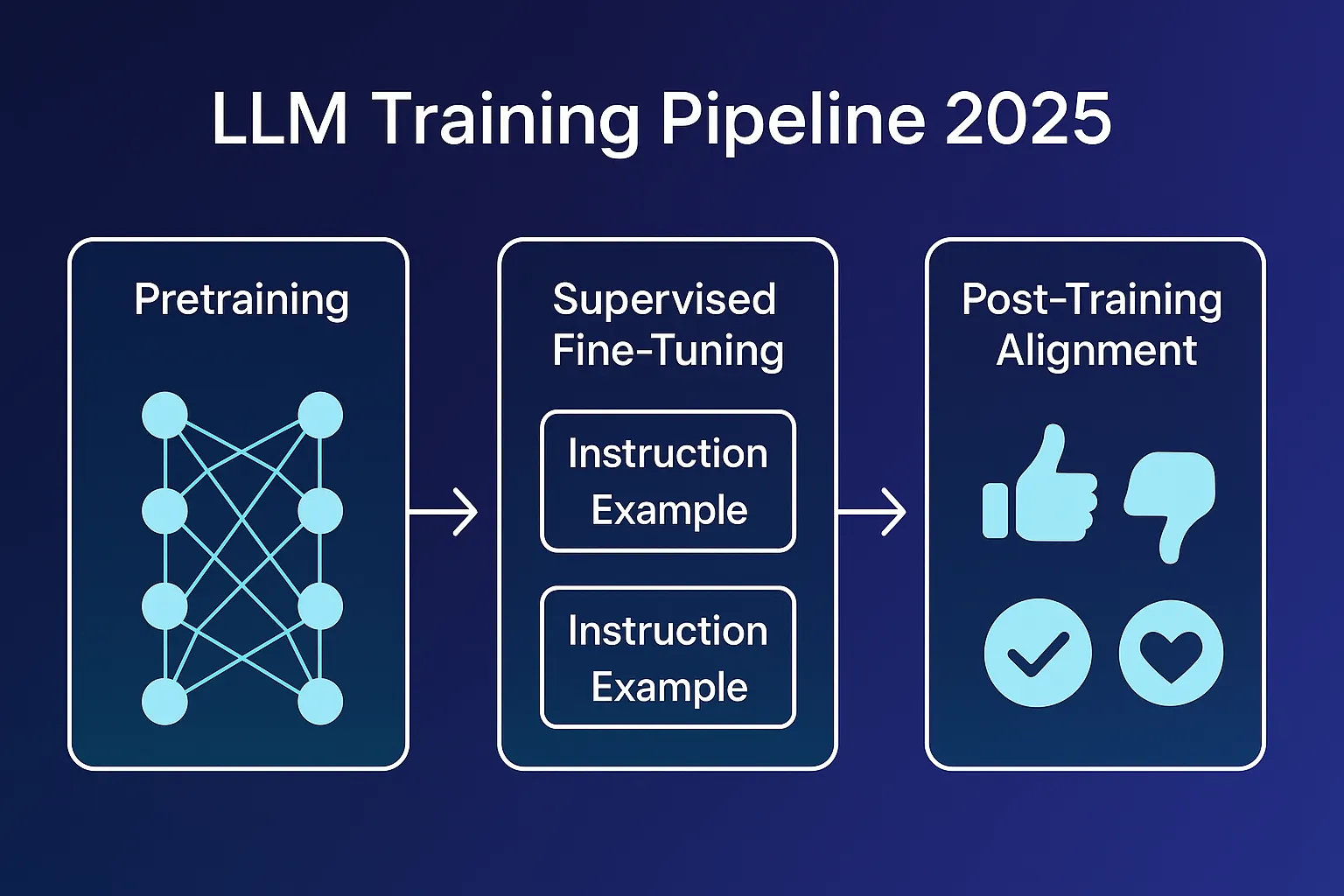
Image Credit: medium.comExplainable Results
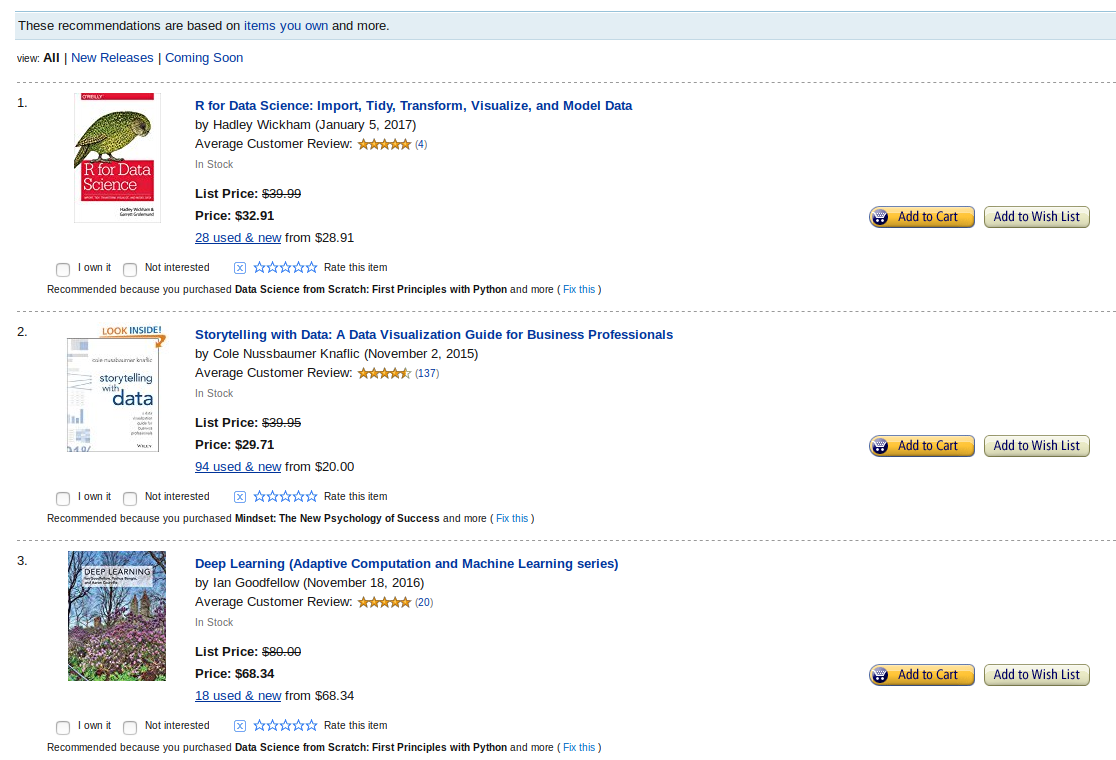
- Users want to know why recommendations are made
- Explainability improves engagement
- Important for trust and transparency
Ethical Considerations

- Bias in risk assessments
- Fairness in automated decisions
- Transparency and accountability
Theorem: Garbage in, garbage out (GIGO)
- Great algorithms + bad data = bad results
- Model performance is constrained by data quality.
- Biased, noisy, or incomplete data leads to misleading predictions.

Image Credit: x.com/xschelling/status/954936528555429888Good data = large size + high quality.
- Sufficient sample size to capture variability in the problem
- High-quality labels and accurate measurements.
- Representative of the population and application context.
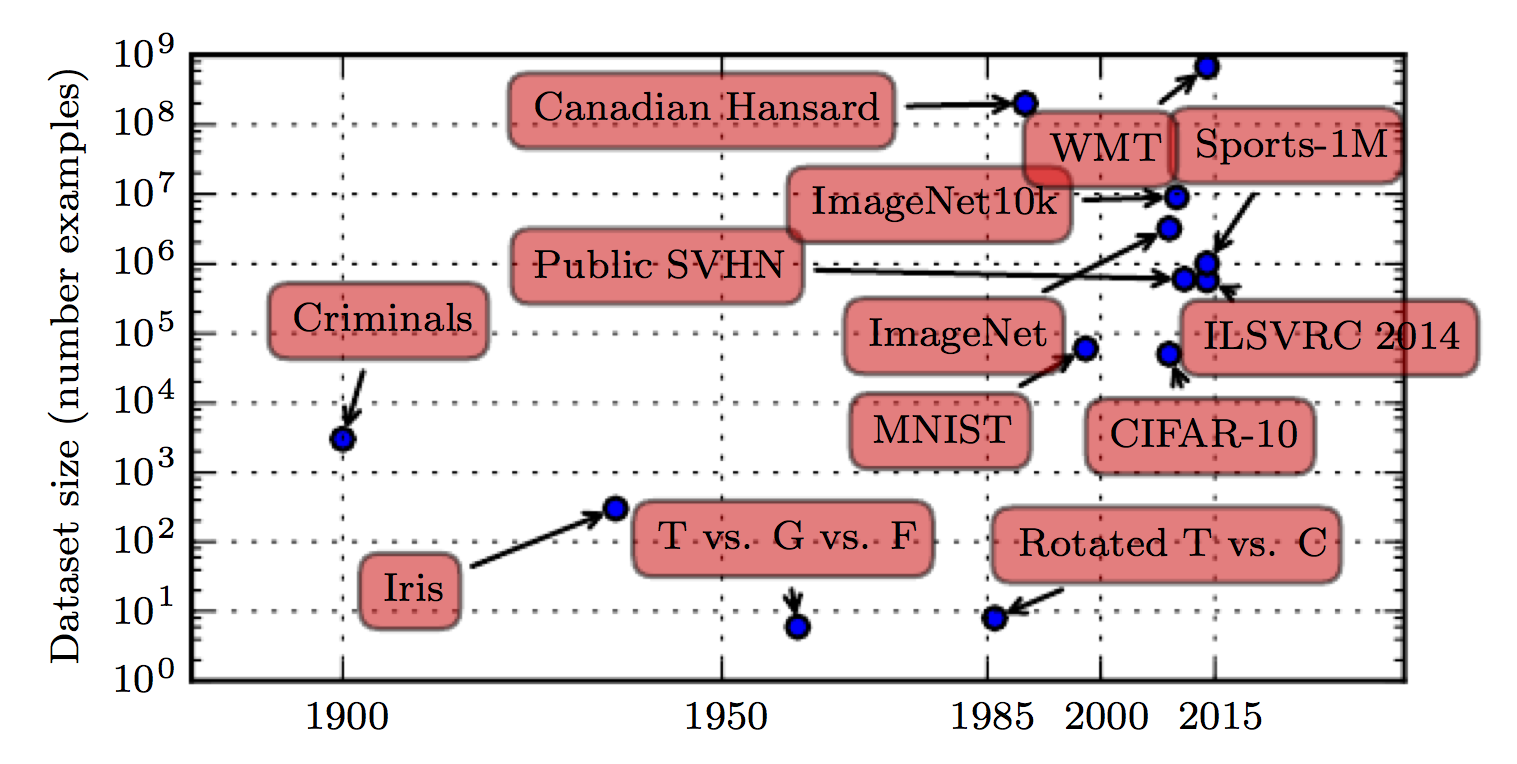
Image Credit: InternetData size and performance
The performance of ML/DL increases rapidly with the size of the data:
- Large neural nets benefit the most from big data.
- Medium and small neural nets also improve with more data.
- Traditional ML algorithms (e.g. random forest, SVM) may saturate earlier.
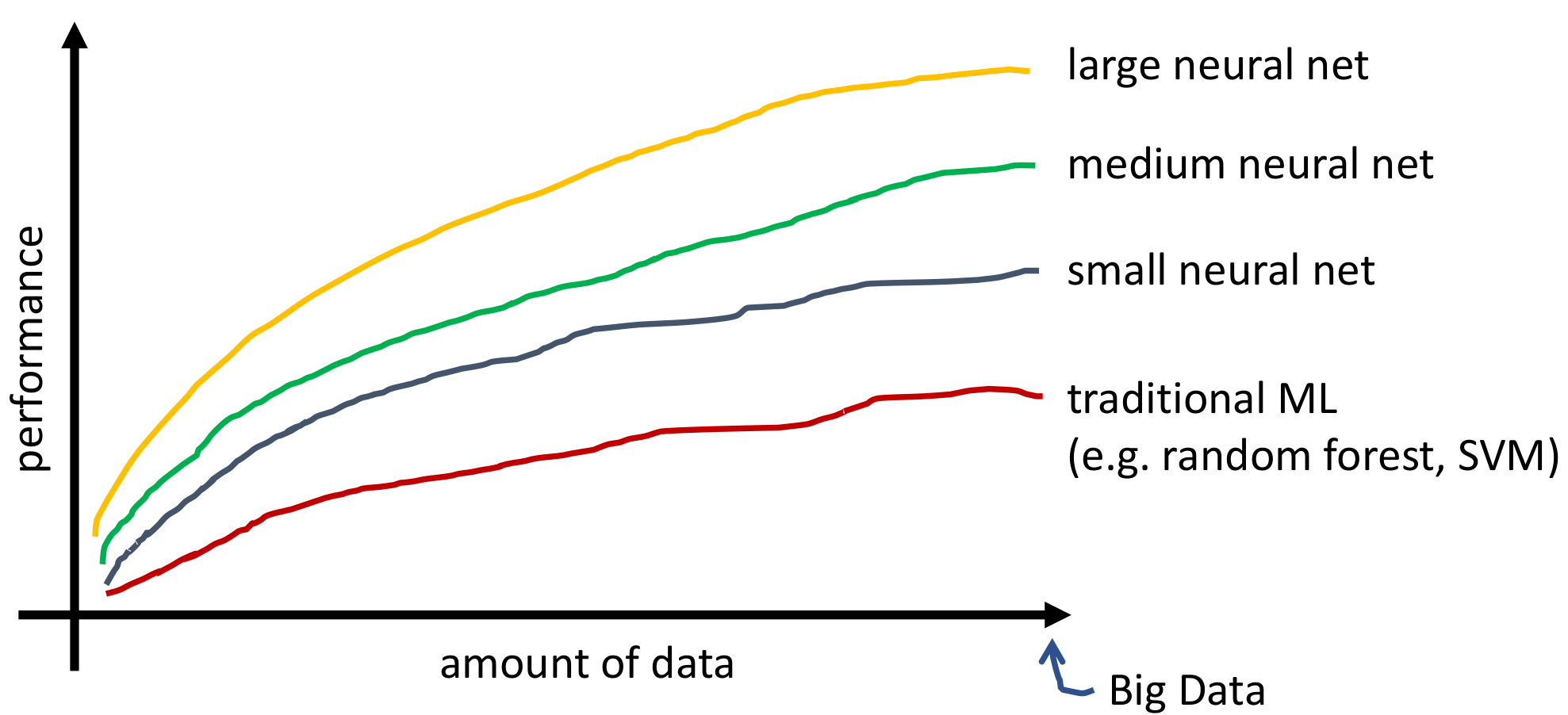
Performance vs data size for ML/DL models